利用Hadoop优化分布式搜索引擎
版权申诉
131 浏览量
更新于2024-07-02
收藏 2.21MB PDF 举报
"大数据技术文档概述了大数据处理的挑战,特别是信息检索的难题,并介绍了hadoop、nutch和solr的结合如何解决这些问题。文档详细阐述了hadoop的高效处理能力、高扩展性和数据安全特性,nutch的功能,以及solr在分布式索引和检索中的作用。此外,文档还提出了研究目标,包括深入研究hadoop和nutch的各个方面,并通过开发插件提升搜索引擎的性能。"
大数据技术是当前信息技术领域的热点,主要应对的是海量数据的存储、处理和分析。随着互联网的发展,数据量呈现指数级增长,传统的数据处理方式已无法满足需求。本文档聚焦于如何利用分布式处理技术解决这一问题。
hadoop是Apache基金会的一个开源项目,它的核心组件包括分布式文件系统HDFS(Hadoop Distributed File System)和计算模型MapReduce。HDFS提供了高容错性和高吞吐量的数据访问,适合大规模数据集的存储。MapReduce则将复杂的大规模计算任务分解为多个小任务,在集群中并行处理,极大地提升了处理效率。
Nutch是基于hadoop的全文搜索引擎,它不仅能够抓取网页,还具备解析、评分和索引等功能。Nutch的插件系统增强了其灵活性,允许开发人员根据需求定制抓取和解析规则,从而提高搜索的相关性和用户体验。
solr是另一个Apache项目,它是一个高性能的企业级搜索服务器,支持分布式索引和查询。通过solr,可以实现大规模数据的快速检索,并且能够通过设置主题进行精准的索引和检索。
文档的研究目标是深入探索分布式搜索引擎,优化索引构建策略。这包括对hadoop的HDFS和MapReduce进行详细研究,理解其工作原理;对Nutch的架构、技术与插件系统进行分析,尤其是开发支持表单登录的protocol-httpclient插件,以及优化url过滤和信息解析插件,以提升搜索结果的相关性。同时,文档还计划实现基于mapreduce的Google排序算法,进一步提高系统的搜索关联度。
系统功能结构中,本地资源解析模块是处理本地文本PDF等文件的关键部分,可能涉及到将非结构化数据转化为结构化数据,以便于后续的处理和分析。
这个大数据技术文档旨在通过研究和优化hadoop、nutch和solr的组合,构建一个高效、灵活且具有高相关性的分布式搜索引擎系统。
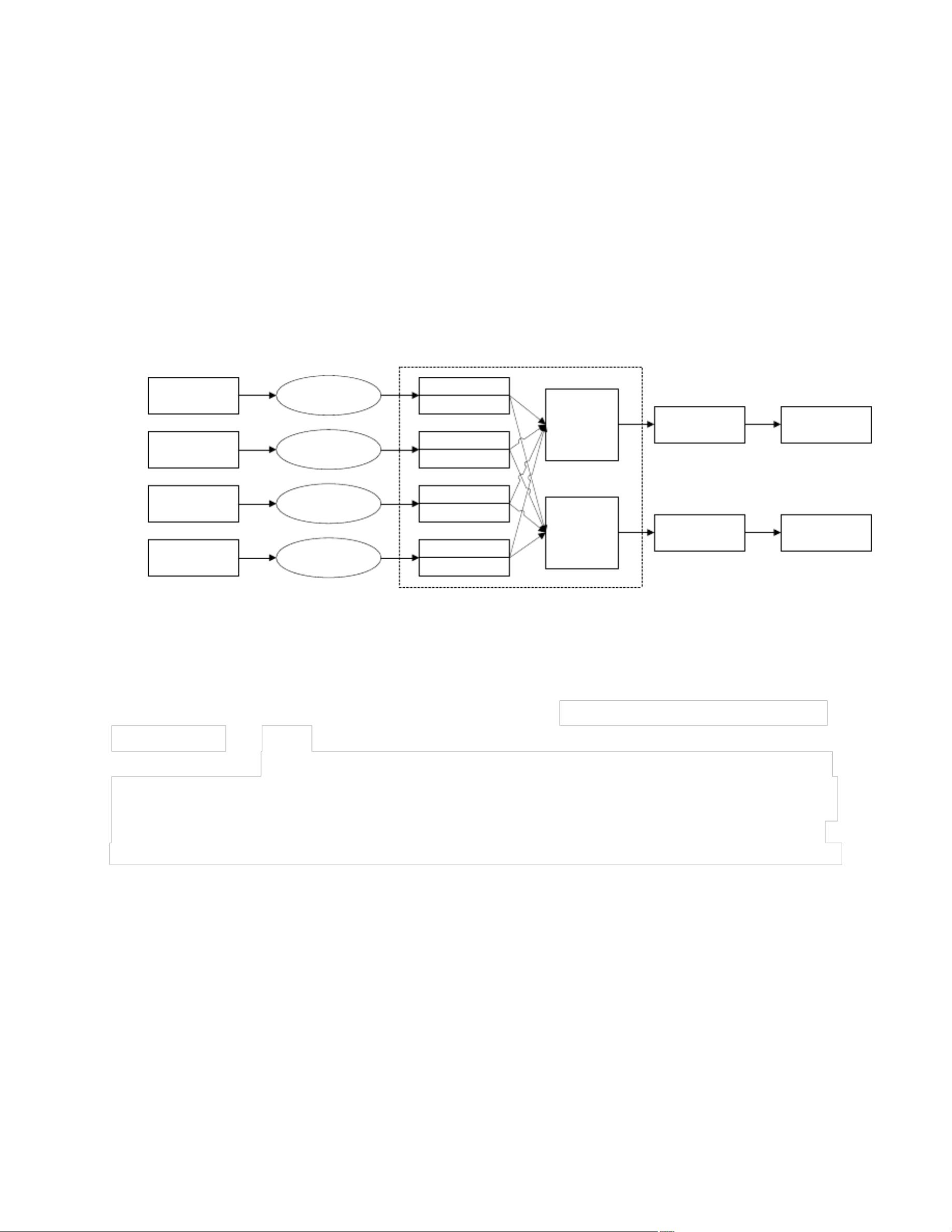
Hbase分布式数据库 Pig数据流语言 Hive数据仓库 Mahout数据挖掘库 Avro远程过程调用
MapReduce
分布式处理模型
HDFS
分布式文件系统
ZooKeeper
分布式协同系统
Hadoop Common
Hadoop项目的核心
图 Hadoop 框架图
子项目
Hadoop Common
HDFS
MapReduce
HBase
Pig
Hive
ZooKeeper
Mahout
Arvo
功能
Hadoop 系统核心,提供子项目的基本支持
实现高吞吐的分布式存储
执行分布式并行计算
一个可扩展的分布式数据库系统
为并行计算提供数据流语言和执行框架
提供类 SQL 语法进行数据查询的数据仓库
提供分布式锁等
一个大规模机器学习和数据挖掘库
Hadoop 的 RPC(远程过程调用)方案
表 Hadoop 子项目功能介绍
5
剩余31页未读,继续阅读
1431 浏览量
454 浏览量
2021-11-06 上传
115 浏览量
178 浏览量
2022-06-21 上传
242 浏览量
316 浏览量

xxpr_ybgg
- 粉丝: 6836
 我的内容管理
展开
我的内容管理
展开







最新资源
- HaneWin DHCP Server 3.0.34:全面支持DHCP/BOOTP的服务器软件
- 深度解析Spring 3.x企业级开发实战技巧
- Android平台录音上传下载与服务端交互完整教程
- Java教室预约系统:刷卡签到与角色管理
- 张金玉的个人简历网站设计与实现
- jiujie:探索Android项目的基础框架与开发工具
- 提升XP系统性能:4G内存支持插件详解
- 自托管笔记应用Notes:轻松跟踪与搜索笔记
- FPGA与SDRAM交互技术:详解读写操作及代码分享
- 掌握MAC加密算法,保障银行卡交易安全
- 深入理解MyBatis-Plus框架学习指南
- React-MapboxGLJS封装:打造WebGL矢量地图库
- 开源LibppGam库:质子-伽马射线截面函数参数化实现
- Wa的简单画廊应用程序:Wagtail扩展的图片库管理
- 全面支持Win7/Win8的MAC地址修改工具
- 木石百度图片采集器:深度采集与预览功能
