机器学习流程详解:从数据采集到预处理
需积分: 0 26 浏览量
更新于2024-08-05
收藏 671KB PDF 举报
"这篇资源主要介绍了机器学习的基础概念和工作流程,强调了数据采集、数据清洗、数据处理(包括无量纲化)等关键步骤,并提到了特征工程中的无量纲化、缺失值处理、定量特征离散化、定性特征哑编码和文本特征向量化。此外,还讨论了数据清洗时的常见问题,如数据缺失、重复和错误。"
在机器学习(ML)中,特征构建和选择是模型性能的关键因素。特征构建涉及将原始数据转化为有意义的输入,以便机器学习算法能够理解。这可能包括对数值特征的无量纲化,确保所有特征在同一尺度上,使得算法能够公平地对待每个特征。无量纲化的方法有标准化(Z-score)和归一化(最小-最大缩放)等。
缺失值是数据预处理中常见的问题,需要采取策略来处理。这可能包括删除含有缺失值的记录(如果缺失值比例较小)、使用平均值、中位数或众数填充(对于数值特征)或者使用模式填充(对于类别特征)。对于大规模数据,可以使用更复杂的方法,如KNN imputation或矩阵分解技术。
定量特征的离散化是将连续数值变量转换为离散的类别变量,有助于减少噪声和提高模型解释性。常用方法有等宽分箱、等频分箱和基于熵或信息增益的最优分割。
定性特征(类别特征)的哑编码是将非数值特征转换为数值,以便于算法处理。常见的哑编码方法有one-hot编码,它为每个类别创建一个新特征,值为0或1。
文本特征向量化是将文本数据转化为数值形式,便于机器学习算法处理。常用方法有词袋模型(Bag-of-Words)、TF-IDF和词嵌入(如Word2Vec或GloVe)。
数据采集是机器学习项目的第一步,可以通过爬虫、API接口和数据库等方式获取。爬虫适用于获取互联网上的实时或特定数据,API则提供结构化的公开数据,而数据库存储公司内部数据,便于管理和分析。
数据清洗是机器学习中最耗时的部分,包括检查数据合理性、有效性,以及处理数据缺失、重复和错误。异常值的处理尤为关键,它们可能影响模型的训练和预测性能,需要通过上下文理解和统计分析来识别并处理。
在数据预处理过程中,数据的无量纲化是必要的,因为它可以使不同单位或范围的特征在同一尺度上比较,从而提高模型的训练效率和预测准确性。无量纲化的应用广泛,对于很多机器学习算法,尤其是线性模型和神经网络,都有显著的影响。
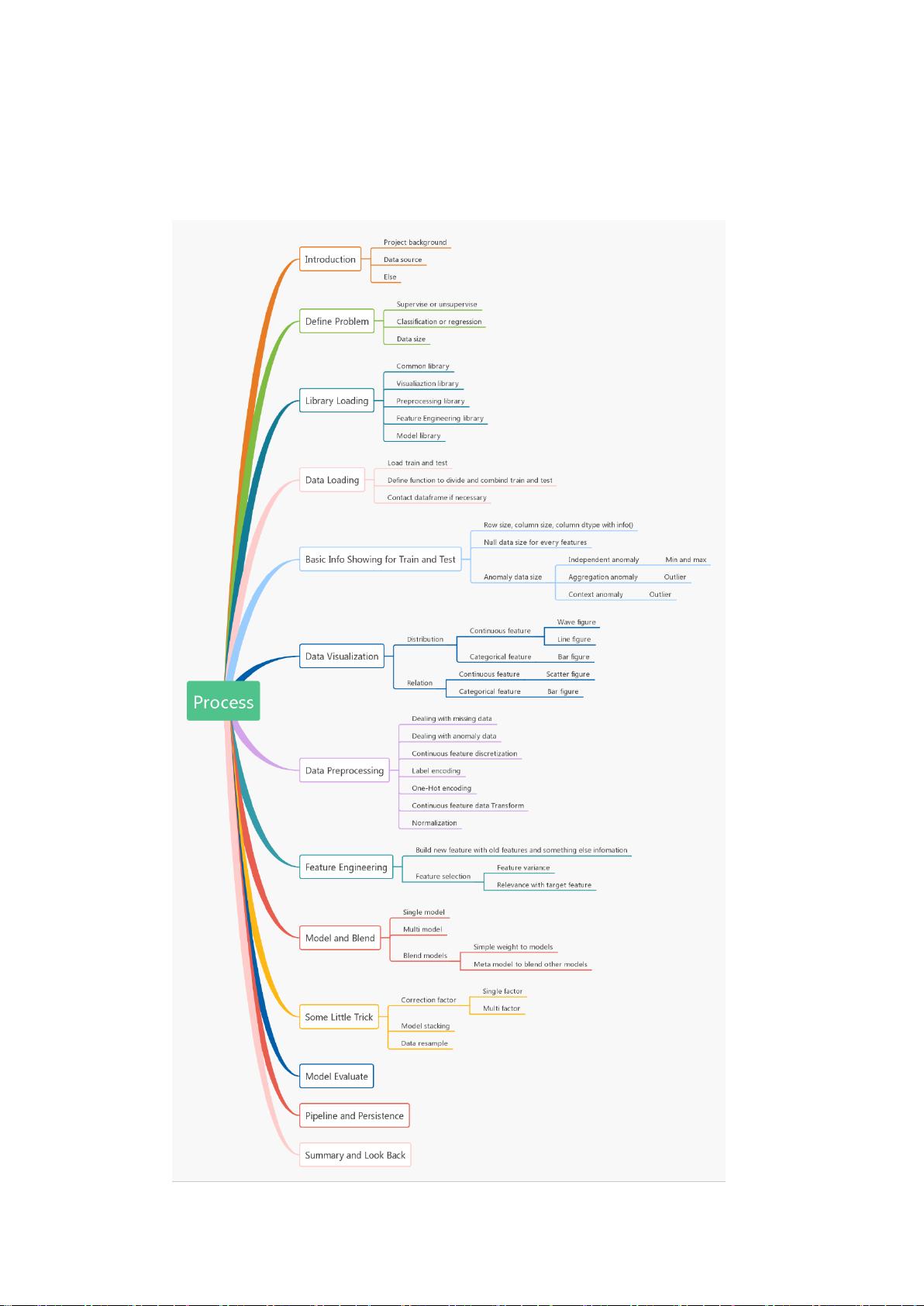
机器学习的工作流程
ML 是一个流程性很强的工作(所以很多人后面会用 PipeLine),数据采集、数据清洗、
数据预处理、特征工程、模型调优、模型融合、模型验证、模型持久化;
下载后可阅读完整内容,剩余5页未读,立即下载
2022-03-10 上传
141 浏览量
2021-03-21 上传
2021-04-07 上传
2021-10-07 上传
2022-03-10 上传
2021-02-03 上传
2021-10-13 上传

BellWang
- 粉丝: 27
- 资源: 315
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握压缩文件管理:2工作.zip文件使用指南
- 易语言动态版置入代码技术解析
- C语言编程实现电脑系统测试工具开发
- Wireshark 64位:全面网络协议分析器,支持Unix和Windows
- QtSingleApplication: 确保单一实例运行的高效库
- 深入了解Go语言的解析器组合器PARC
- Apycula包安装与使用指南
- AkerAutoSetup安装包使用指南
- Arduino Due实现VR耳机的设计与编程
- DependencySwizzler: Xamarin iOS 库实现故事板 UIViewControllers 依赖注入
- Apycula包发布说明与下载指南
- 创建可拖动交互式图表界面的ampersand-touch-charts
- CMake项目入门:创建简单的C++项目
- AksharaJaana-*.*.*.*安装包说明与下载
- Arduino天气时钟项目:源代码及DHT22库文件解析
- MediaPlayer_server:控制媒体播放器的高级服务器
