Yann LeCun新突破:提升图像语义表示的自监督学习方法
版权申诉
77 浏览量
更新于2024-08-04
收藏 2.95MB PDF 举报
“Yann LeCun的新论文展示了在图像语义表示上的显著进步,超过先前的MAE(Masked Autoencoder)方法。论文提出了一种名为‘Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture’的新型自监督学习框架,旨在提升无监督学习的语义级别,同时减少对特定图像增强的依赖。”
在计算机视觉领域,自监督学习已经成为预训练模型的重要策略,尤其是在无标注数据丰富的环境中。传统的自监督方法主要分为基于不变性的方法和生成方法。基于不变性的方法,如SimCLR和MOCO,通过不同的数据增强技术生成图像的多个视图,然后让模型学习这些视图之间的相似性。这种方法能够学到高语义级别的表示,但也可能导致特定任务的偏差,限制了泛化能力。
另一方面,生成方法,特别是mask denoising,如MAE,通过随机遮盖图像的一部分并要求模型预测被遮盖的内容,以学习图像的表示。这种方式学习到的表示通常处于较低的语义层次,因此在复杂的语义任务上可能表现不佳,需要进一步的微调。
Yann LeCun的新工作旨在解决这些问题,提出了一种联合嵌入预测架构。这种架构结合了生成与不变性学习的特性,能够在不依赖特定图像增强的情况下提升语义表示的水平。论文中介绍的模型设计可能允许模型更有效地捕获图像中的高级语义信息,同时减少对下游任务的偏置。
通过使用这种新架构,模型不仅能够处理图像数据,还可能更容易地扩展到多模态学习,如音频或文本。这符合认知学习理论,即生物系统通过内部模型适应感官输入的变化来学习表示。新方法可能不需要复杂的适应机制,就能在未见过的任务上表现出色,比如图像分类和实例分割。
这篇论文对于自监督学习领域的贡献在于提出了一种新的自适应表示学习方法,它有望改进现有的无监督预训练技术,提高模型的泛化能力和多模态应用的能力。这一进展对于推动计算机视觉和人工智能技术的发展具有重要意义。
2023/6/28 16:38
Yann LeCun 新作!大幅超越 MAE,图像语义表示卷出新高度
https://mp.weixin.qq.com/s/X72rZayd-guXWjhxzFSwTg
3/12
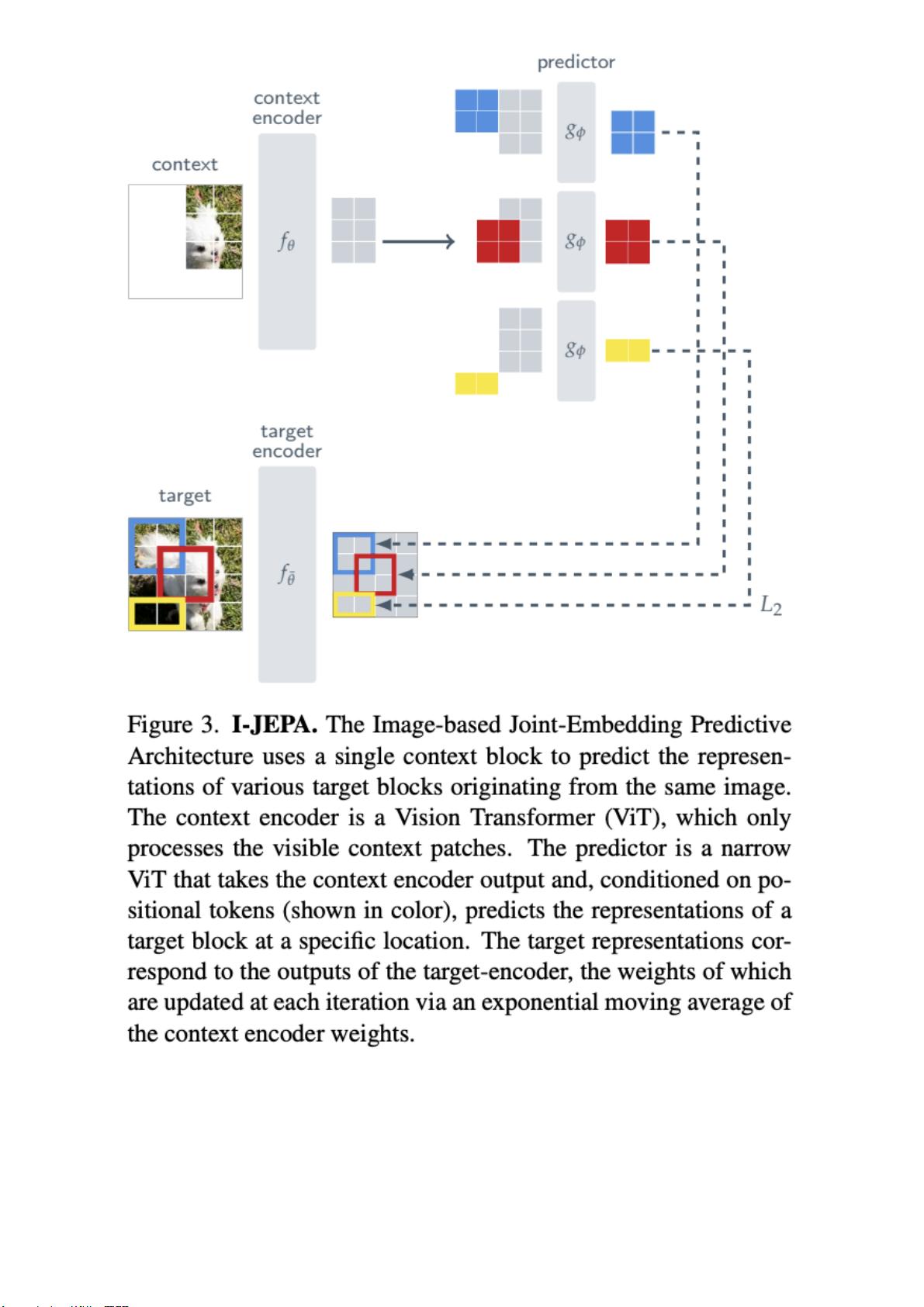
I-JEPA是一种预测目标块表示的方法。在I-JEPA中,目标对应于图像块的表示。
它首先从图像中随机采样一个上下文块x,并去除与目标块重叠的部分,然后将x通过上下文编
码器fθ获得对应的patch-level表示sx,最后通过预测器gφ,将sx作为输入,以及每个patch的
mask token,输出M个目标块表示sˆy(1), ..., sˆy(M),并计算预测值与目标值之间的L2距离,
剩余11页未读,继续阅读
2023-10-18 上传
2018-05-18 上传
2014-07-11 上传
2020-11-11 上传
2017-11-14 上传
2023-08-13 上传
2015-01-04 上传
2023-08-12 上传
2017-09-25 上传

地理探险家
- 粉丝: 1255
- 资源: 5609
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Jive for Android SDK:示例应用的使用指南
- Python中的贝叶斯建模与概率编程指南
- 自动化NBA球员统计分析与电子邮件报告工具
- 下载安卓购物经理带源代码完整项目
- 图片压缩包中的内容解密
- C++基础教程视频-数据类型与运算符详解
- 探索Java中的曼德布罗图形绘制
- VTK9.3.0 64位SDK包发布,图像处理开发利器
- 自导向运载平台的行业设计方案解读
- 自定义 Datadog 代理检查:Python 实现与应用
- 基于Python实现的商品推荐系统源码与项目说明
- PMing繁体版字体下载,设计师必备素材
- 软件工程餐厅项目存储库:Java语言实践
- 康佳LED55R6000U电视机固件升级指南
- Sublime Text状态栏插件:ShowOpenFiles功能详解
- 一站式部署thinksns社交系统,小白轻松上手
