深度学习驱动的超分辨率技术综述:从 SRCNN 到 ESPCN
需积分: 50 25 浏览量
更新于2024-07-18
收藏 3.2MB PPTX 举报
深度学习超分综述
深度学习在超分辨率(Super Resolution, SR)重建技术中扮演着关键角色,它是一种通过算法将低分辨率(Low-Resolution, LR)图像提升到高分辨率(High-Resolution, HR)的技术。本文将带你深入了解深度学习在这一领域的应用,特别适合对深度学习和图像处理有一定基础的学习者。
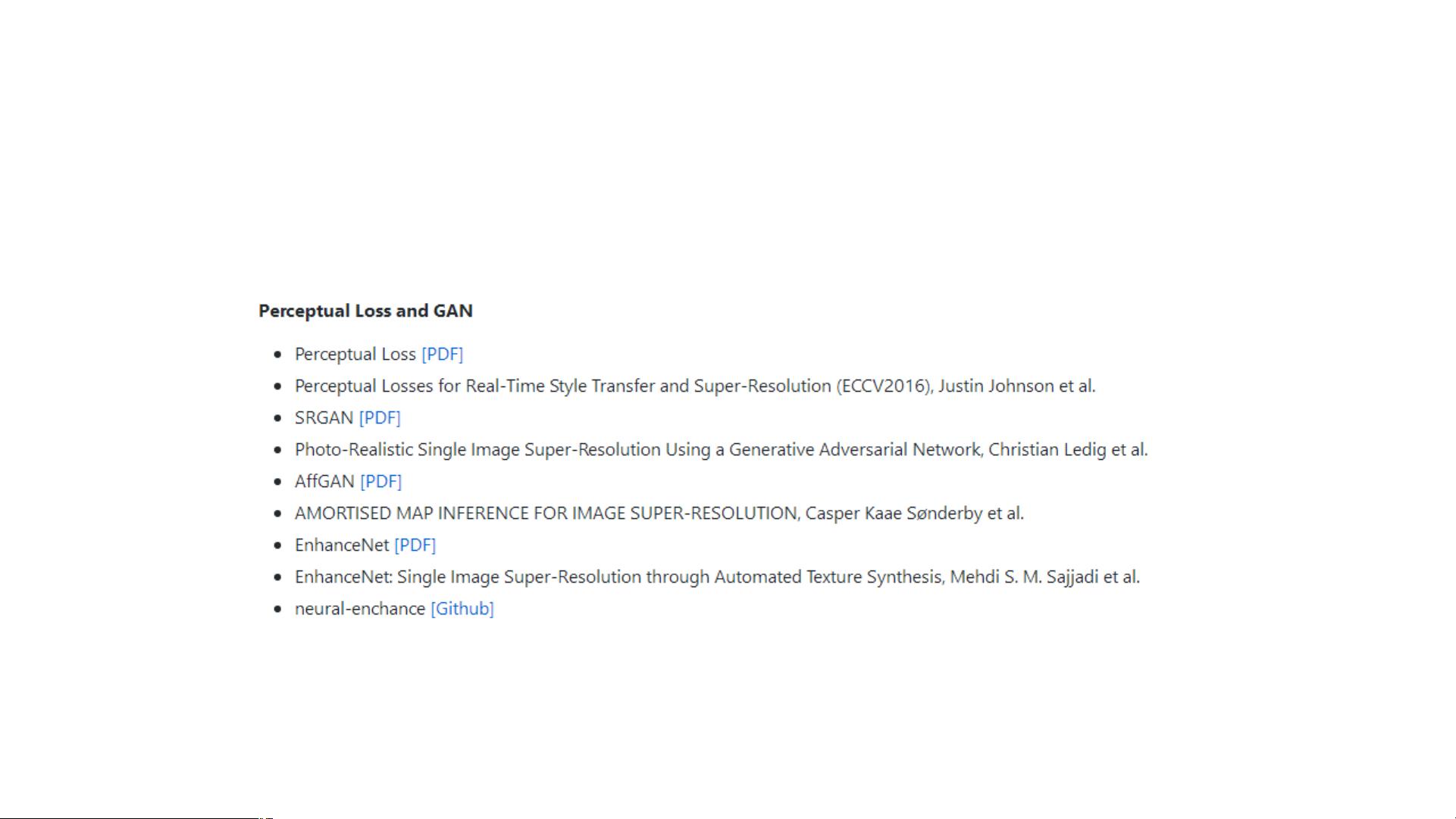
首先,深度学习超分辨率重建的核心是利用深度卷积神经网络(Deep Convolutional Neural Networks, DCNN)来学习并捕捉图像的高频和低频信息之间的复杂映射关系。这种技术起源于2015年的CVPR会议,由香港中文大学的Dong等人提出的SRCNN(Super-Resolution Convolutional Neural Network),它是第一个将卷积神经网络应用于超分辨率问题的方法。SRCNN将图像处理过程划分为图像块提取、非线性映射和图像重建三个阶段,并通过端到端学习实现,显著提高了与传统稀疏编码(Sparse Coding)方法的重建效果。
随后,如VDSR(Very Deep Super-Resolution)在2016年进一步发展,借鉴了VGG网络的结构,设计出包含20个权值层的深网络,解决了梯度爆炸问题,通过增大学习率和使用梯度裁剪策略,能够在4小时的训练时间内在Titan Z上达到较高的性能。VDSR的训练数据集包含了ImageNet的大规模图像,以及数据增强技术的应用。
FSRCNN(Fast Super-Resolution Convolutional Neural Network)于2016年发布,是对SRCNN的优化版本,采用了瓶颈结构来加速训练,相比于SRCNN测试速度提升了41倍。对于不同的放大因子,FSRCNN仅对特定的“deconv”部分进行重新训练,以适应不同的尺度变化。
ESPCN(Efficient Sub-Pixel Convolutional Neural Network)则关注如何更高效地执行上采样和卷积操作。尽管原始的上采样方法(如双三次插值)并不涉及学习,ESPCN强调的是在保持计算效率的同时,寻找更为精准的放大策略。
深度学习超分重建方法不断进化,从基础的卷积神经网络模型到更深层次的网络架构设计、训练技巧和优化策略的运用,展现了其在提升图像质量方面的巨大潜力。随着技术的深入研究,我们期待未来深度学习能带来更多的创新,为图像处理和人工智能领域带来更多突破。
剩余22页未读,继续阅读
2013-07-01 上传
2016-07-26 上传
2023-09-06 上传
2024-04-19 上传
2023-08-09 上传
2023-08-24 上传
2023-03-24 上传
2024-01-08 上传

smilesi
- 粉丝: 2
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
