协同过滤推荐系统:原理与应用
需积分: 0 49 浏览量
更新于2024-06-30
收藏 1.16MB DOCX 举报
"推荐系统是利用用户行为数据进行个性化推荐的技术,主要分为基于用户的协同过滤、基于物品的协同过滤以及基于内容的推荐等方法。协同过滤是推荐系统中的核心算法,它通过寻找用户之间的相似性或物品之间的相似性来实现推荐。在用户较少的情况下,协同过滤可以帮助解决冷启动问题,通过收集用户注册信息和物品反馈来逐步建立用户兴趣模型。"
在协同过滤中,有两种主要的推荐方式:基于用户的推荐和基于物品的推荐。基于用户的推荐利用K-邻居算法,找到与目标用户兴趣最相似的K个用户,然后推荐他们喜欢但目标用户还未体验的物品。而基于物品的推荐则通过计算物品之间的相似度,如果用户喜欢某物品A,系统会推荐与其相似的物品C给用户。
推荐引擎的分类除了协同过滤,还包括基于内容的分析。基于内容的推荐系统不依赖其他用户的数据,而是通过分析物品的内容特征来进行推荐,适合处理冷启动问题、推荐特殊兴趣的物品,并能提供推荐理由。然而,这种方法要求物品的内容特征具有良好的结构,并且无法直接获取其他用户的评价信息。
协同过滤推荐系统的工作流程包括以下几个步骤:
1. 收集用户偏好数据,这些数据通常来源于用户的购买记录、评分、浏览历史等。
2. 对数据进行预处理,包括去除噪声(如误操作)和归一化,使数据在统一尺度上。
3. 计算相似度,可以使用欧几里得距离、余弦相似度或皮尔逊相关系数等方法来衡量用户或物品之间的相似度。
4. 根据相似度选取邻居,可以设定固定数量的邻居或者设置相似度阈值来筛选。
5. 基于这些邻居进行推荐,基于用户的CF推荐邻居喜欢的物品,基于物品的CF推荐与用户已喜欢物品相似的其他物品。
基于用户相似度与物品相似度的区别在于,前者关注用户之间的关联,后者关注物品属性的关联。物品相似度计算通常是针对物品评分矩阵的列向量进行的,而用户相似度则考虑行向量。
推荐系统通过不断学习和调整,能够提供更加精准和个性化的推荐服务,从而提升用户体验。在实际应用中,可能会结合多种推荐策略,以克服单一方法的局限性,例如,可以结合基于内容的推荐和协同过滤来优化推荐效果。
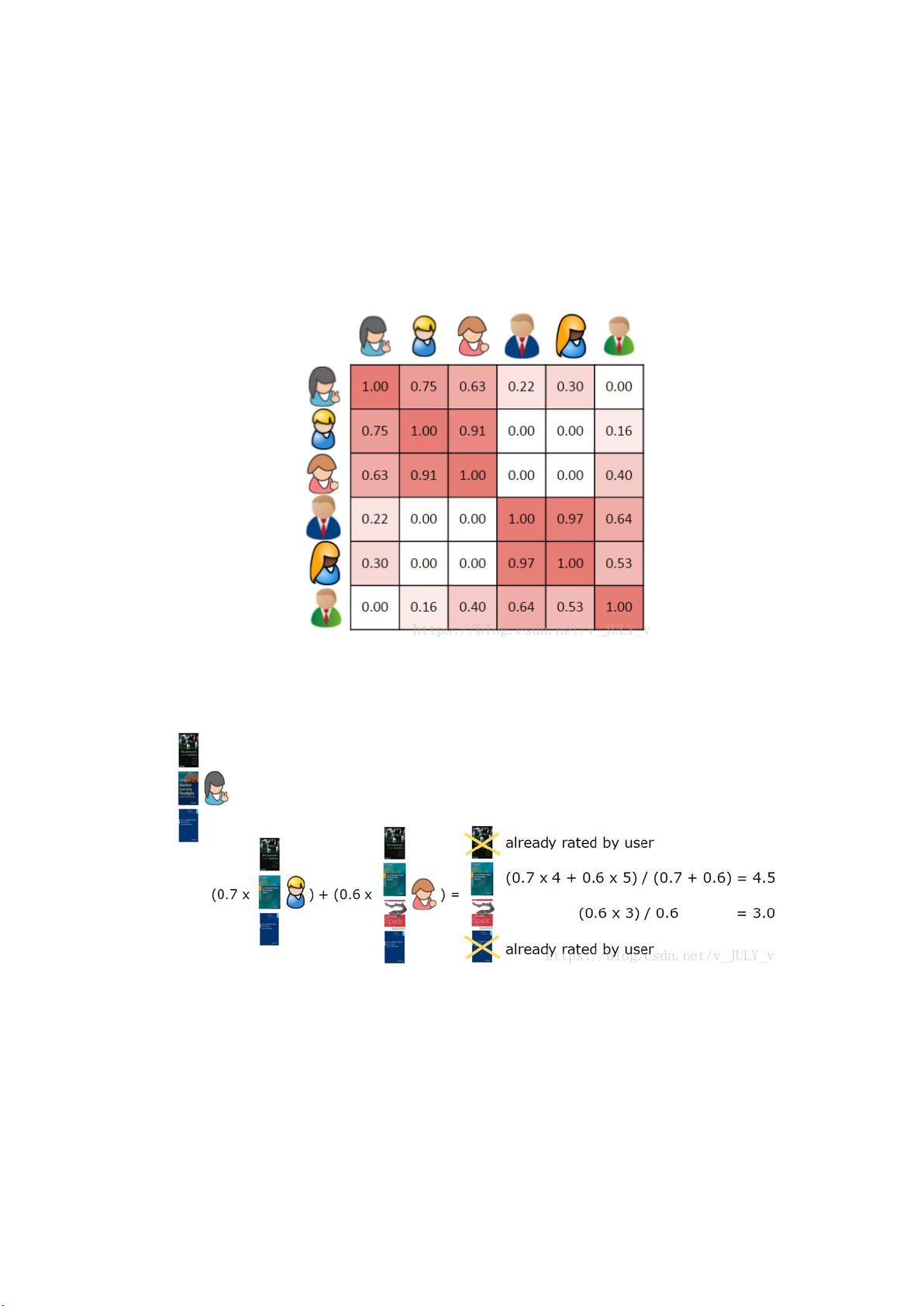
对于大多数相似度量,向量之间相似度越高,代表彼此更相似。本例中,第一个用户第
二、第三个用户非常相似,有两本共同书籍,与第四、第五个用户的相似度低一些,只有一
本共同书籍,而与最后一名用户完全不相似,因为没有一本共同书籍。
计算出每个用户的相似性:
所以,我们找到了与第一个用户最相似的 K 个用户,删除第一个用户已经评价过的书籍,
给最相似的 K 个用户正在阅读的书籍加权,然后计算出总和。
剩余15页未读,继续阅读
2022-08-03 上传
2018-12-10 上传
2009-09-06 上传
2021-01-02 上传
2022-08-08 上传
2021-01-20 上传
2020-12-09 上传
2021-01-21 上传

南小鹏
- 粉丝: 38
- 资源: 289
 我的内容管理
展开
我的内容管理
展开







最新资源
- PureMVC AS3在Flash中的实践与演示:HelloFlash案例分析
- 掌握Makefile多目标编译与清理操作
- STM32-407芯片定时器控制与系统时钟管理
- 用Appwrite和React开发待办事项应用教程
- 利用深度强化学习开发股票交易代理策略
- 7小时快速入门HTML/CSS及JavaScript基础教程
- CentOS 7上通过Yum安装Percona Server 8.0.21教程
- C语言编程:锻炼计划设计与实现
- Python框架基准线创建与性能测试工具
- 6小时掌握JavaScript基础:深入解析与实例教程
- 专业技能工厂,培养数据科学家的摇篮
- 如何使用pg-dump创建PostgreSQL数据库备份
- 基于信任的移动人群感知招聘机制研究
- 掌握Hadoop:Linux下分布式数据平台的应用教程
- Vue购物中心开发与部署全流程指南
- 在Ubuntu环境下使用NDK-14编译libpng-1.6.40-android静态及动态库
