SparkStructuredStreaming编程详解
175 浏览量
更新于2024-08-28
收藏 414KB PDF 举报
"Spark结构式流编程指南"
Spark的Structured Streaming是Spark SQL执行引擎上的一个强大的、可扩展的、容错的流处理框架。它利用静态数据模拟流处理,随着流数据的持续输入,Spark SQL引擎会连续处理并更新到最终的结果表中。Structured Streaming提供了一种将实时数据流视作连续追加的表格的抽象概念,允许开发者使用DataFrame和DataSet API进行复杂的操作,如聚集、事件窗口和流与批处理的连接。
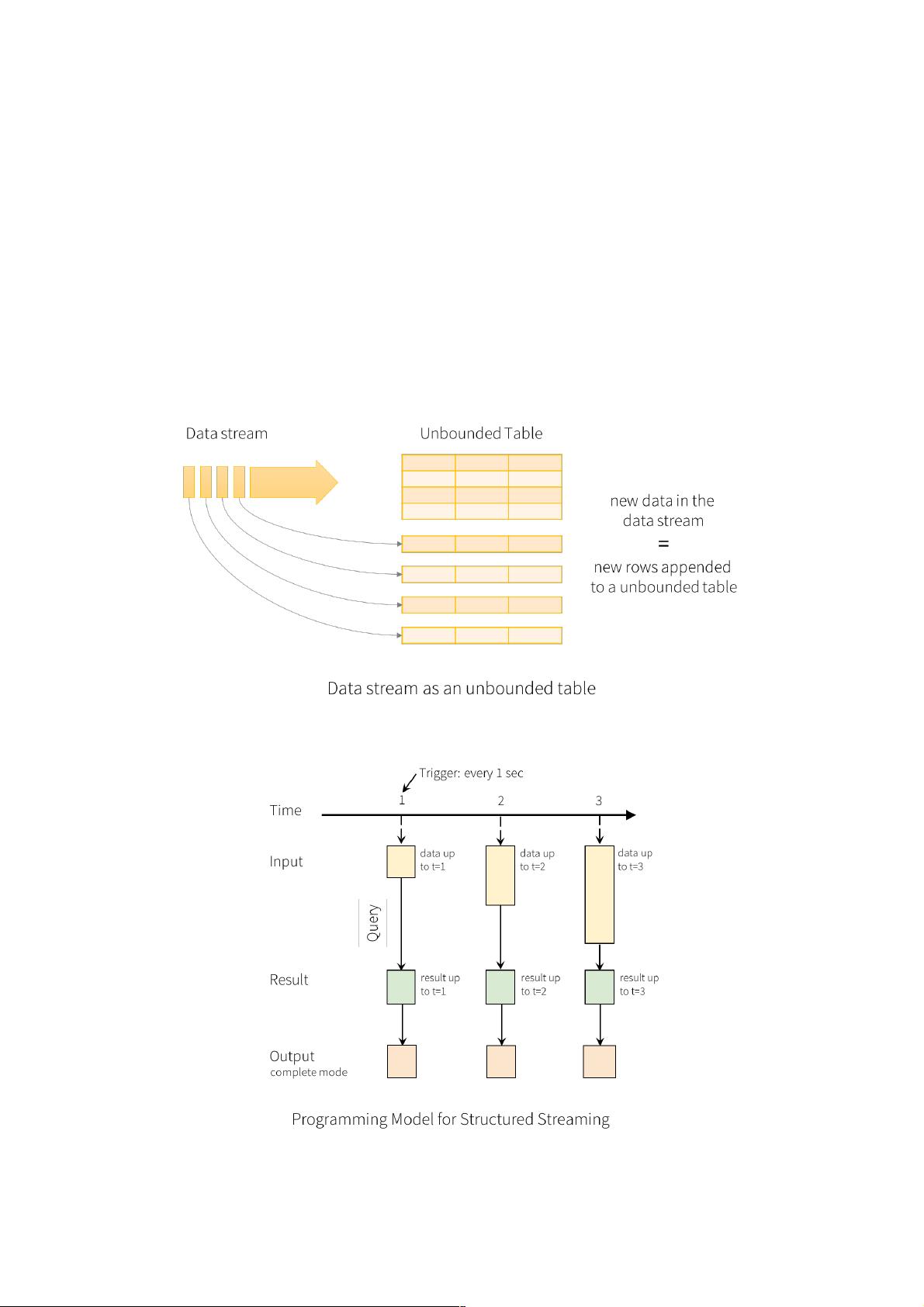
在编程模型中,Structured Streaming的核心概念是将实时流数据看作一个不断增长的输入表,每次新的数据到来都相当于在表中添加新的一行。处理这些数据流时,有三种不同的输出模式:
1. Complete模式:每次更新时,完整的结果表都会被写入外部存储,具体如何写取决于所使用的存储连接器。
2. Append模式:仅写入自上次触发后在结果表中新增的行,适用于结果表中的行不会改变的情况。
3. Update模式:只写入自上次触发后在结果表中更新的行(在Spark 2.0中暂不可用),不同于Complete模式,因为它不输出未修改的行。
Structured Streaming还支持事件时间和延迟数据处理。事件时间是数据本身携带的时间戳,通常在实时应用中更为重要,比如根据设备生成事件的时间进行分析。通过在事件时间上定义窗口操作,可以方便地进行如每分钟事件计数等聚合查询。在延迟数据出现时,Spark可以更新旧的聚合结果,同时清除旧状态,以控制中间数据的大小。水印机制自Spark 2.1引入,用于处理迟到的数据,允许用户设定一个阈值来界定何时可以清理旧状态。
Spark的Structured Streaming提供了高效、稳定和精确一次的保证,是处理实时流数据的强大工具,特别适合需要处理事件时间和延迟数据的场景。通过DataFrame和DataSet API,开发者可以编写出灵活且高效的流处理程序,实现各种复杂的实时数据分析任务。
Spark结构式流编程指南结构式流编程指南
概览
Structured Streaming 是一个可拓展,容错的,基于Spark SQL执行引擎的流处理引擎。使用小量的静态数据模拟流处理。伴
随流数据的到来,Spark SQL引擎会逐渐连续处理数据并且更新结果到最终的Table中。你可以在Spark SQL上引擎上使用
DataSet/DataFrame API处理流数据的聚集,事件窗口,和流与批次的连接操作等。最后Structured Streaming 系统快速,稳
定,端到端的恰好一次保证,支持容错的处理。
小样例
编程模型
结构化流的关键思想是将实时数据流视为一个连续附加的表
基本概念
将输入的数据当成一个输入的表格,每一个数据当成输入表的一个新行。
"Output"是写入到外部存储的写方式,写入方式有不同的模式:
1.Complete模式: 将整个更新表写入到外部存储,写入整个表的方式由存储连接器决定。
2.Append模式:只有自上次触发后在结果表中附加的新行将被写入外部存储器。这仅适用于结果表中的现有行不会更改的查
下载后可阅读完整内容,剩余6页未读,立即下载
2021-11-23 上传
2018-08-23 上传
2016-08-10 上传
2017-03-01 上传
2015-09-29 上传
2020-07-02 上传
2022-08-03 上传
2019-06-30 上传
2019-12-02 上传

weixin_38588394
- 粉丝: 8
- 资源: 954
 我的内容管理
展开
我的内容管理
展开







最新资源
- OPNET 用户指南_翻译稿
- 数据库的设计-----VFP
- FLEX 3 CookBook 简体中文学习基础资料PDF
- TOMCAT移植到JBOSS
- Myeclipse7[1].0+JBoss5.0测试EJB3.0环境搭建过程详解
- PROTEUS中文教程
- NCURSES Programming HOWTO中文第二版
- 高性能计算之并行编程技术--MPI并行程序设计
- ORACLE备份策略
- 软件评测师07年大题与答案,Word版
- The Productive Programmer.pdf
- c#团队开发之命名规范
- 计算机操作系统(汤子瀛)习题答案.pdf
- ArcGIS Server轻松入门
- 基于组播技术的网络抢答系统设计
- USB数据采集的几个问题
