Cloudera实践训练:动手操作指南
需积分: 10 169 浏览量
更新于2024-07-18
1
收藏 3.71MB PDF 举报
"Cloudera定制培训提供了丰富的动手实践练习,涵盖了Hadoop、Spark、HBase、Impala等多个大数据处理和分析技术。这份手册旨在帮助用户深入理解和应用这些工具,提升在CDH(Cloudera Distributed Hadoop)环境中的实际操作能力。"
在本手册中,用户将能够学习和实践以下关键知识点:
1. **查询Hadoop数据与Apache Impala**:
Impala是Cloudera提供的一个快速、低延迟的SQL查询引擎,可以直接在Hadoop上运行。通过本练习,用户可以了解如何使用Impala进行交互式查询,理解其对大规模数据集的高性能处理能力。
2. **使用命令行和Hue访问HDFS**:
HDFS(Hadoop分布式文件系统)是Hadoop生态系统的基础。学习如何通过命令行接口以及图形化工具Hue与HDFS交互,能帮助用户更好地管理和操作存储在Hadoop集群上的数据。
3. **运行YARN作业**:
YARN(Yet Another Resource Negotiator)是Hadoop的资源管理系统,用于调度和管理集群中的计算资源。用户将了解如何提交和监控YARN作业,理解资源分配和任务调度的概念。
4. **使用Spark Shell探索RDD**:
Spark的核心数据结构是弹性分布式数据集(RDD)。通过Spark Shell,用户可以实践创建、转换和操作RDD,从而熟悉Spark的基本编程模型。
5. **使用Spark处理数据文件**:
用户将学习如何使用Spark处理各种数据文件,包括读取、转换和写入数据,这有助于理解Spark的数据处理能力和效率。
6. **使用PairRDD进行数据集连接**:
PairRDD是Spark中处理键值对数据的结构,用户将学习如何使用它来执行连接操作,如JOIN,这是数据集成中的常见任务。
7. **编写和运行Spark应用程序**:
实践编写Spark应用程序,涉及Spark编程模型、job和stage的生命周期,以及如何在集群上部署和运行这些应用程序。
8. **配置Spark应用程序**:
配置是确保Spark应用程序高效运行的关键。用户将学习如何根据需求调整Spark配置参数。
9. **查看Spark应用程序UI中的作业和阶段**:
Spark提供了一个Web UI来监控作业和阶段的执行情况,通过这个练习,用户可以理解Spark的工作流程和性能优化。
10. **持久化RDD**:
学习RDD的持久化机制,这是Spark优化内存使用和提高性能的重要手段。
11. **使用Spark实现迭代算法**:
Spark支持迭代计算,用户将在实践中了解如何利用Spark实现复杂的迭代算法,如机器学习中的梯度下降法。
12. **使用Spark SQL进行ETL**:
Spark SQL结合了SQL查询和DataFrame API,使用户可以方便地进行数据提取、转换和加载(ETL)操作。
13. **编写Spark Streaming应用程序**:
Spark Streaming提供了实时数据处理的能力,用户将学会如何创建Spark Streaming应用,处理连续的数据流。
14. **使用Spark Streaming处理多批次数据**:
这个练习将让用户理解如何处理多个数据批次,以实现更复杂的流处理逻辑。
15. **使用Spark Streaming处理Apache Kafka消息**:
Kafka是一种分布式流处理平台,本练习将展示如何结合Spark Streaming处理Kafka消息,实现实时数据流的分析和处理。
16. **附录A:启用Jupyter**:
Jupyter Notebook是一个交互式计算环境,可以用于编写和展示代码及结果。手册可能提供了关于如何在Cloudera环境中设置和使用Jupyter Notebook的信息,以便于数据探索和教学。
这些实践练习全面覆盖了大数据处理的关键组件,不仅让学习者掌握理论知识,更通过实际操作深化理解,提升在Cloudera CDH环境中的技能。

!
Copyright © 2010-2016 Cloudera, Inc. All rights reserved.
Not to be reproduced or shared without prior written consent from Cloudera.
15
15
Who Is Dr. Who?
You may notice that YARN says you are logged in as dr.who. This is what is
displayed when user authentication is disabled for the cluster, as it is on the
training VM. If user authentication were enabled, you would have to log in as a
valid user to view the YARN UI, and your actual username would be displayed,
together with user metrics such as how many applications you had run, how
much system resources your applications used and so on.
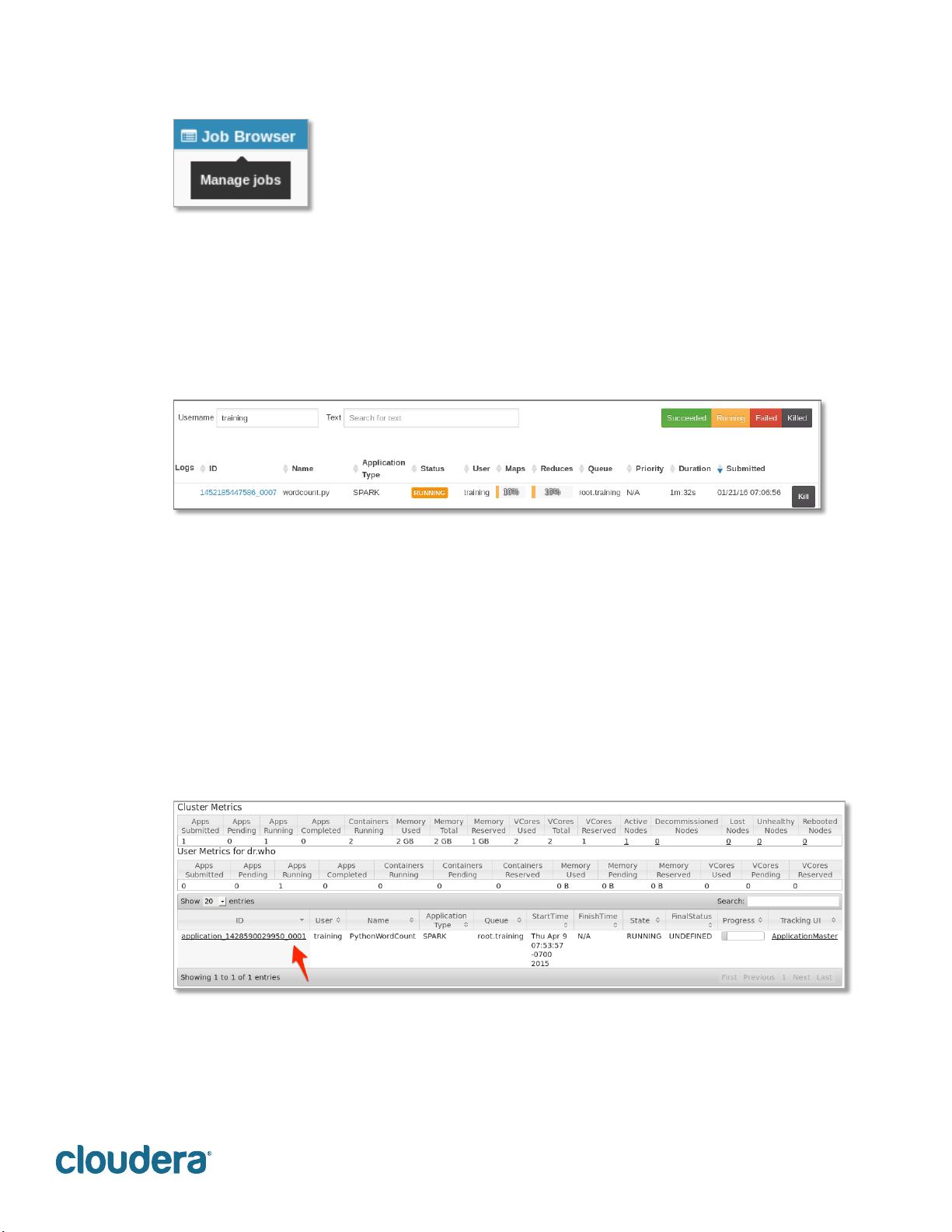
2.' :)F'!.$,'!$A!,3'!L)#%'+!-.!,3'!"#%+,'(!2',(-0+!+'0,-$.E!B3-03!&-+=#)C+!
-.A$(?),-$.!+%03!)+!,3'!.%?8'(!$A!)==#-0),-$.+!(%..-./!0%(('.,#CE!=('L-$%+#C!
(%.E!$(!B)-,-./!,$!(%.H!,3'!)?$%.,!$A!?'?$(C!%+'&!).&!)L)-#)8#'H!).&!3$B!
?).C!B$(F'(!.$&'+!)('!-.!,3'!0#%+,'(9!!
!
3.' "#-0F!,3'!Nodes!#-.F!-.!,3'!"#%+,'(!?'.%!$.!,3'!#'A,9!:3'!8$,,$?!+'0,-$.!B-##!
&-+=#)C!)!#-+,!$A!B$(F'(!.$&'+!-.!,3'!0#%+,'(9!:3'!=+'%&$>&-+,(-8%,'&!0# % +, '(!
%+'&!A$(!,()-.-./!3)+!$.#C!)!+-./#'!.$&'E!B3-03!-+!(%..-./!$.!,3'!#$0)#!?)03-.'9!
D.!,3'!(')#!B$(#&E!,3-+!#-+,!B$%#&!+3$B!?%#,-=#'!B$(F'(!.$&'+9!
!
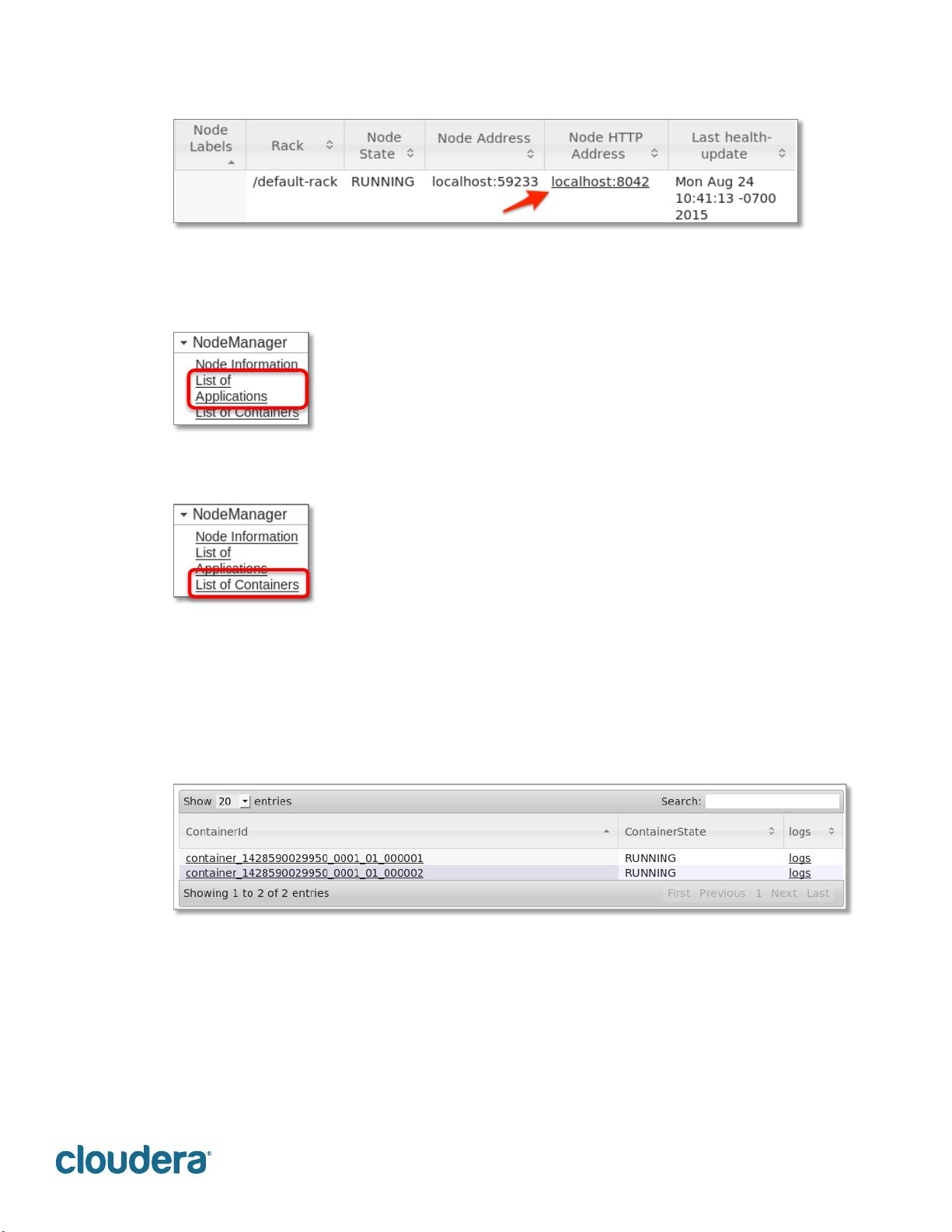
4.' "#-0F!,3'!Node'HTTP'Address!,$!$='.!,3'!K$&'!2).)/'(!SD!A$(!,3),!.$&'9!:3-+!
&-+=#)C+!+,),-+,-0+!)8$%,!,3'!+'#'0,'&!.$&'E!-.0#%&-./!)?$%.,!$A!)L)-#)8#'!
?'?$(CE!0%(('.,#C!(%..-./!)==#-0),-$.+!M,3'('!)('!.$.'NE!).&!+$!$.9!

剩余86页未读,继续阅读
2023-07-12 上传
2021-05-05 上传
2021-05-15 上传
2021-06-20 上传
2019-03-24 上传

okboyjs
- 粉丝: 0
- 资源: 22
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
