Spark数据倾斜解决方案:优化策略与实战
113 浏览量
更新于2024-08-29
收藏 3.48MB PDF 举报
"本文主要探讨了Spark数据倾斜的问题,包括其定义、原因和解决策略。数据倾斜是指在并行处理的数据集中,某些分区的数据量远超其他分区,导致处理速度严重不平衡,成为性能瓶颈。文章指出,数据倾斜往往源于Stage内部Task处理数据量的不均等,以及数据源本身的分布问题。对于如何缓解或消除数据倾斜,文章提到了从源头避免数据倾斜,例如在使用Kafka作为数据源时,确保Producer使用合理的Partitioner来保证数据平衡。"
在Spark作业中,数据倾斜是一个严重的性能问题,它会导致部分Task处理时间过长,从而影响整个Stage乃至Job的执行效率。这种情况通常是由于数据在分区(Partition)间的分布不均匀造成,比如某个Partition承载的数据量过大,使得处理这个Partition的Task耗时过长。Spark的并行处理机制决定了一个Stage中耗时最长的Task将决定该Stage的总体执行时间。
造成数据倾斜的原因主要有两方面:
1. 数据源本身的分布不均:例如,当从HDFS或Kafka读取数据时,如果数据在这些存储系统的分区之间分布不均,那么Spark在读取时也会遇到类似问题。特别是对于Kafka,每个Partition对应Spark的一个Task,因此Kafka Partition的均衡至关重要。
2. Shuffle操作后的数据分布:Spark作业中,Shuffle操作可能导致数据重新分配到新的Partition,如果这个过程没有做好,可能会加剧数据倾斜。
解决数据倾斜的方法主要包括:
1. 预处理数据:在数据加载到Spark之前,可以先在数据源端进行预处理,例如,通过哈希或范围分区等方式确保数据相对均匀地分布在各个分区。
2. 调整Partition数量:增加Partition数量可以降低单个Partition的数据量,但过多的Partition会增加任务调度的开销,因此需要找到合适的平衡点。
3. 使用自定义Partitioner:根据业务需求定制Partitioner,确保数据按照特定规则分布,减少倾斜可能性。
4. 处理倾斜键:对于特定的关键值(key)导致的倾斜,可以采用采样、聚合小文件、动态调整Partition大小等方法来处理。
5. 使用Spark的Coalesce或Repartition操作:在不影响作业逻辑的前提下,适当时候可以使用这两个操作来优化数据分布。
在实际应用中,需要结合业务需求和集群资源情况,综合运用上述方法来有效解决Spark的数据倾斜问题。同时,监控和日志分析也是发现和诊断数据倾斜的重要手段,通过监控任务执行时间和数据分布,可以及时发现并调整作业参数,优化性能。
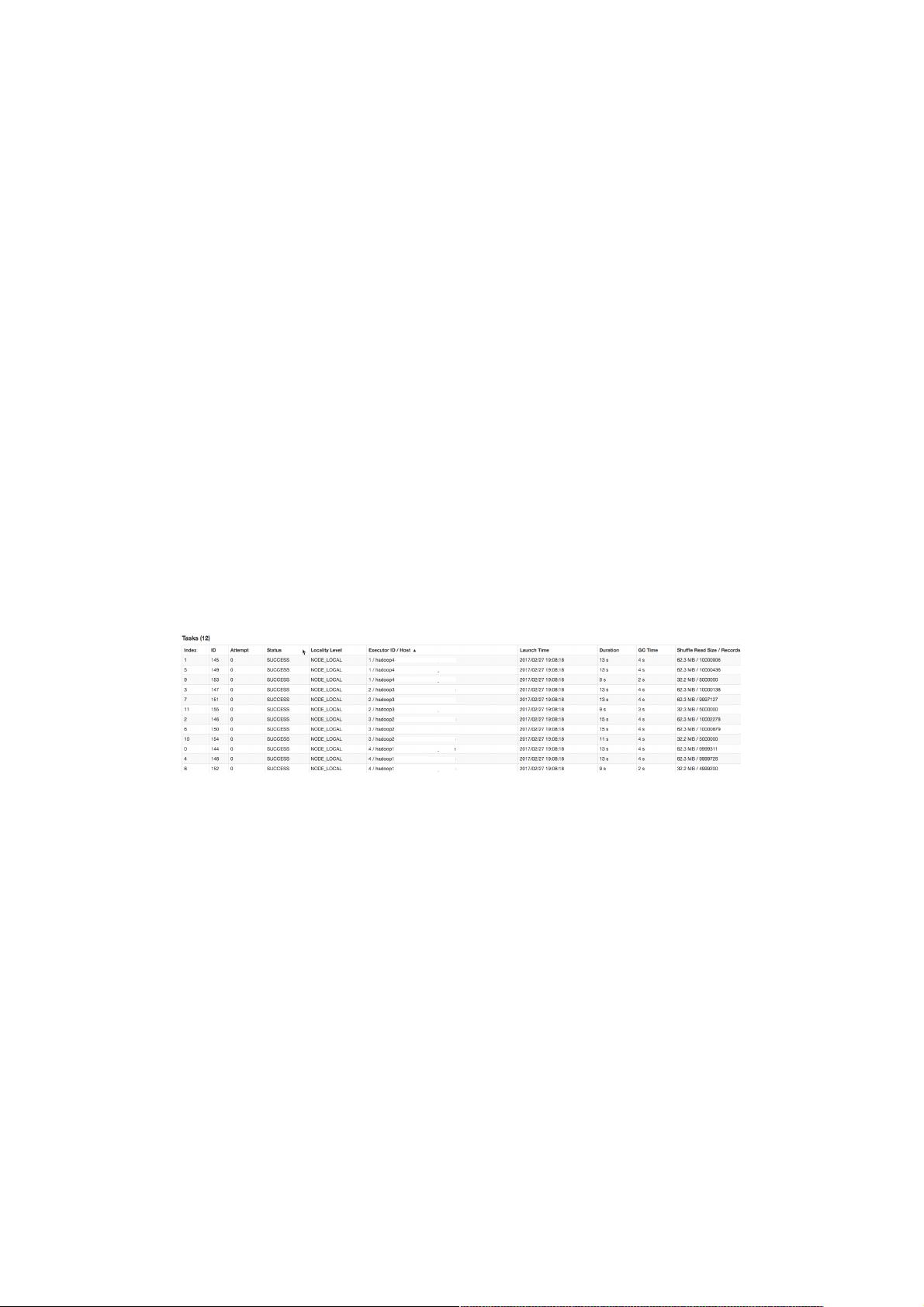
为545万,耗时12秒。
总结
适用场景适用场景
大量不同的Key被分配到了相同的Task造成该Task数据量过大。
解决方案解决方案
调整并行度。一般是增大并行度,但有时如本例减小并行度也可达到效果。
优势优势
实现简单,可在需要Shuffle的操作算子上直接设置并行度或者使用spark.default.parallelism设置。如果是Spark SQL,还可通
过SET spark.sql.shuffle.partitions=[num_tasks]设置并行度。可用最小的代价解决问题。一般如果出现数据倾斜,都可以通过
这种方法先试验几次,如果问题未解决,再尝试其它方法。
劣势劣势
适用场景少,只能将分配到同一Task的不同Key分散开,但对于同一Key倾斜严重的情况该方法并不适用。并且该方法一般只
能缓解数据倾斜,没有彻底消除问题。从实践经验来看,其效果一般。
自定义Partitioner
原理
使用自定义的Partitioner(默认为HashPartitioner),将原本被分配到同一个Task的不同Key分配到不同Task。
案例
以上述数据集为例,继续将并发度设置为12,但是在groupByKey算子上,使用自定义的Partitioner(实现如下)
由下图可见,使用自定义Partition后,耗时最长的Task 6处理约1000万条数据,用时15秒。并且各Task所处理的数据集大小
相当。
总结
适用场景适用场景
大量不同的Key被分配到了相同的Task造成该Task数据量过大。
解决方案解决方案
使用自定义的Partitioner实现类代替默认的HashPartitioner,尽量将所有不同的Key均匀分配到不同的Task中。
优势优势
不影响原有的并行度设计。如果改变并行度,后续Stage的并行度也会默认改变,可能会影响后续Stage。
劣势劣势
适用场景有限,只能将不同Key分散开,对于同一Key对应数据集非常大的场景不适用。效果与调整并行度类似,只能缓解数
据倾斜而不能完全消除数据倾斜。而且需要根据数据特点自定义专用的Partitioner,不够灵活。
将Reduce side Join转变为Map side Join
原理
通过Spark的Broadcast机制,将Reduce侧Join转化为Map侧Join,避免Shuffle从而完全消除Shuffle带来的数据倾斜。
剩余10页未读,继续阅读
268 浏览量
316 浏览量
270 浏览量
154 浏览量
268 浏览量
146 浏览量
270 浏览量
290 浏览量
点击了解资源详情

weixin_38579899
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- HTC G22刷机教程:掌握底包刷入及第三方ROM安装
- JAVA天天动听1.4版:证书加持的移动音乐播放器
- 掌握Swift开发:实现Keynote魔术移动动画效果
- VB+ACCESS音像管理系统源代码及系统操作教程
- Android Nanodegree项目6:Sunshine-Wear应用开发
- Gson解析json与网络图片加载实践教程
- 虚拟机清理神器vmclean软件:解决安装失败难题
- React打造MyHome-Web:公寓管理Web应用
- LVD 2006/95/EC指令及其应用指南解析
- PHP+MYSQL技术构建的完整门户网站源码
- 轻松编程:12864液晶取模工具使用指南
- 南邮离散数学实验源码分享与学习心得
- qq空间触屏版网站模板:跨平台技术项目源码大全
- Twitter-Contest-Bot:自动化参加推文竞赛的Java机器人
- 快速上手SpringBoot后端开发环境搭建指南
- C#项目中生成Font Awesome Unicode的代码仓库
