理解大数据技术:Hadoop生态圈解析
需积分: 22 92 浏览量
更新于2024-09-10
收藏 60KB DOCX 举报
"这篇文章主要介绍了Hadoop大数据生态圈,包括HDFS和MapReduce等核心组件,以及Hive和Spark等扩展工具。"
Hadoop生态圈是针对大数据处理所构建的一系列开源工具和框架的集合,旨在解决单机无法应对的海量数据处理问题。这个生态圈的核心是Hadoop Distributed File System (HDFS),它是一个分布式文件系统,能够跨越众多机器存储大量数据,为用户提供单一的文件系统视图,而无需关心数据的具体物理位置。
HDFS的设计目标是高容错性和高吞吐量,适合处理和存储非常大的文件。它通过将大文件分割成多个块,并将这些块复制到多台机器上,确保即使有硬件故障,数据仍然可访问且可用。这种分布式的特性使得HDFS成为大数据存储的理想选择。
处理大数据的另一个关键组件是MapReduce,这是一种编程模型,用于大规模数据集的并行计算。MapReduce包含两个主要阶段:Map和Reduce。在Map阶段,数据被分成键值对,并分发到集群中的各个节点进行处理;Reduce阶段则聚合Map阶段的结果,进一步处理和汇总数据。MapReduce简化了编写处理大数据的复杂性,但其计算模型相对简单,适合批处理任务,可能不适合实时或交互式查询。
随着技术的发展,出现了MapReduce的优化和替代方案,如Tez和Spark。Tez是Apache Hadoop的一个低延迟任务调度框架,它改进了MapReduce的执行效率,提高了数据处理的速度。Spark则更进一步,提供内存计算,显著提升了大数据处理的性能,尤其适用于迭代算法和实时分析。Spark还提供了诸如Spark SQL、Spark Streaming和MLlib等模块,支持SQL查询、流处理和机器学习等应用场景。
Hadoop生态圈还包括其他工具,如Hive,它是一个基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,使得非Java背景的用户也能轻松处理Hadoop上的数据。此外,Pig是另一种高级数据处理语言,用于简化Hadoop上的数据操作,而HBase是一个NoSQL数据库,提供实时读写访问,适用于需要随机访问和快速检索的大数据场景。
Hadoop生态圈提供了一个完整的解决方案,涵盖了大数据的存储、计算、管理和分析等多个方面。通过灵活选择和组合这些工具,企业可以有效地处理和利用海量数据,从而实现商业价值。理解并掌握Hadoop生态圈的各个组件及其功能,对于在大数据时代成功运营至关重要。
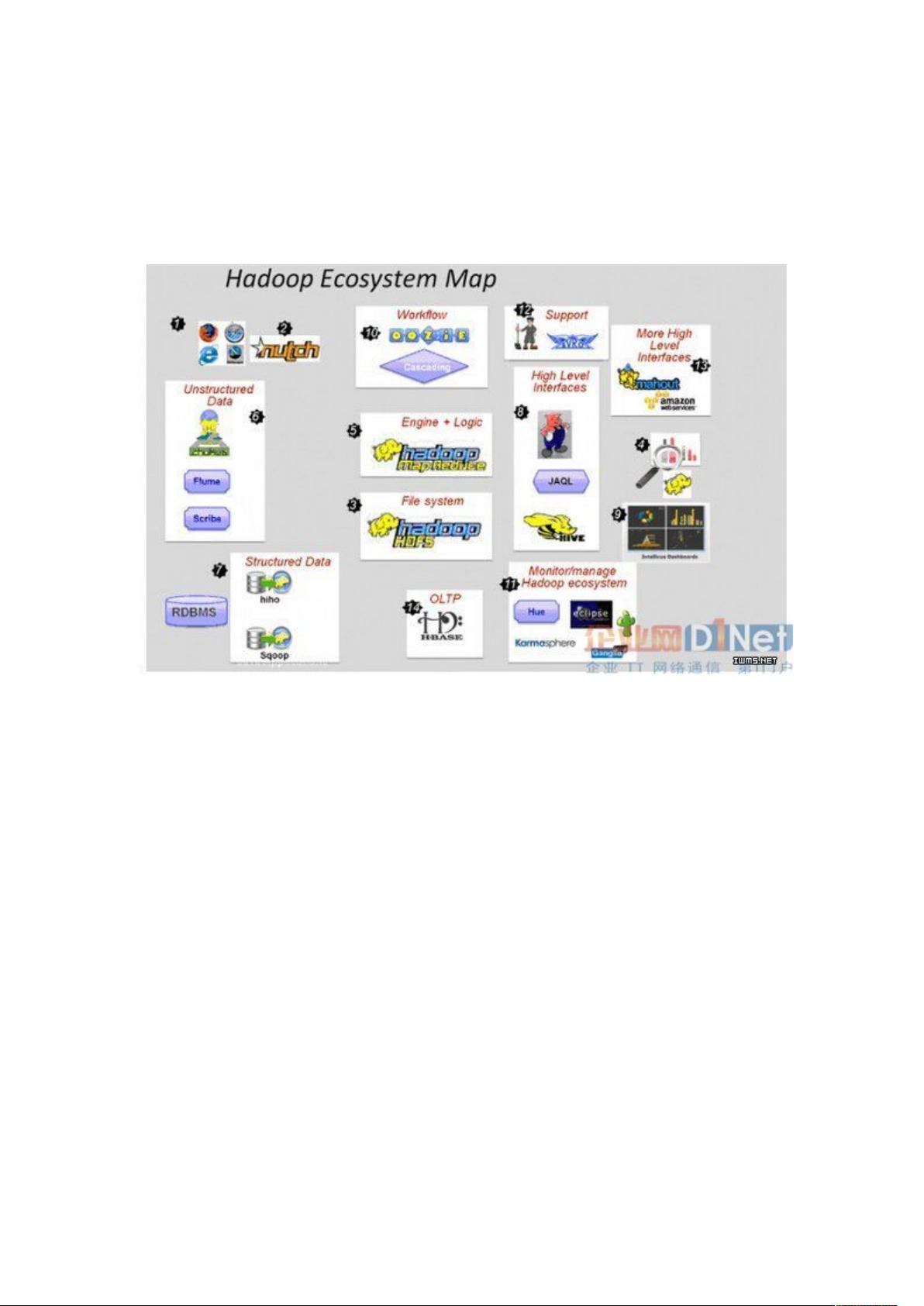
一文教你看懂大数据的技术生态
圈:Hadoop,hive,spark
责任编辑:editor005|2015-03-02 13:50:51本文摘自:中国大数据
大数据本身是个很宽泛的概念,Hadoop 生态圈(或者泛生态圈)基本上都是
为了处理超过单机尺度的数据处理而诞生的。你可以把它比作一个厨房所以需
要的各种工具。锅碗瓢盆,各有各的用处,互相之间又有重合。你可以用汤锅
直接当碗吃饭喝汤,你可以用小刀或者刨子去皮。但是每个工具有自己的特性,
虽然奇怪的组合也能工作,但是未必是最佳选择。
大数据,首先你要能存的下大数据。
传统的文件系统是单机的,不能横跨不同的机器。HDFS(Hadoop
Distributed FileSystem)的设计本质上是为了大量的数据能横跨成百上千台机器,
但是你看到的是一个文件系统而不是很多文件系统。比如你说我要获取/hdfs
下载后可阅读完整内容,剩余6页未读,立即下载
202 浏览量
194 浏览量
227 浏览量
127 浏览量

一枝梅花押海棠
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







