物联网Lambda架构:Spark Streaming与MLlib的实时数据分析
需积分: 5 111 浏览量
更新于2024-07-17
收藏 1.65MB PDF 举报
在2017年的SPARK SUMMIT大会上,Bas Geerdink,ING公司的数据分析领域章主管,就Lambda Architecture在物联网(IoT)快速数据分析中的应用以及Spark Streaming和MLlib技术进行了深入探讨。Bas拥有人工智能和信息学硕士学位,是Spark认证开发者,并在LinkedIn上分享他的见解和经验,@bgeerdink。
Lambda Architecture是一种经典的大数据处理框架,由Nathan Marz在2013年提出,旨在解决实时处理、批量处理和长期批处理的需求,适用于处理大规模、高并发的数据流和静态数据。该架构分为三个层次:
1. **Lambda Layer**(实时处理层):主要用于处理实时或接近实时的数据流,如物联网设备产生的传感器数据。在这个层面上,Bas提到了使用Spark Streaming,这是一种基于微批处理的流处理工具,它允许快速处理不断流动的数据并提供即时响应。Spark Streaming通过将数据分片并在多个节点上并行处理,确保了处理速度和可扩展性。
2. **Batch Layer**(批量处理层):用于对静态数据进行离线分析,处理的是存储在Hadoop HDFS或其他批量处理系统中的大量文件或表。这一层通常使用批处理工具,如Apache Hadoop MapReduce或Spark的DataFrame API,对数据进行深度挖掘和复杂分析。
3. **History Layer**(历史存储层):保存所有历史数据,以便进行长期分析和查询。这些数据可能被定期或按需加载到数据仓库或数据湖中,如Amazon S3或Apache Hive。
Lambda Architecture的优点是可以满足不同场景下的需求,但批评点包括其复杂性,以及需要维护两个独立的代码库和数据存储系统。为了简化,现代实践中可能会采用替代方案,比如将流数据视为迷你批次处理,或者在一个系统中结合批处理和流处理,例如Spark Streaming可以与Spark SQL协同工作,提供统一的查询和可视化工具。
Bas Geerdink在会议上分享了智能停车这一具体应用场景,展示了如何利用Lambda Architecture和Spark Streaming来整合实时和静态数据,优化停车设施的管理和运营。在这个案例中,系统可能实时分析车辆进出停车场的数据,同时执行基于历史数据的停车预测和推荐。
Bas Geerdink的演讲强调了在物联网环境中,如何通过Lambda Architecture和Spark Streaming技术来应对数据挑战,提供快速、安全且可扩展的分析解决方案。这不仅涉及技术选型,还包括数据处理策略的优化和安全性考虑。
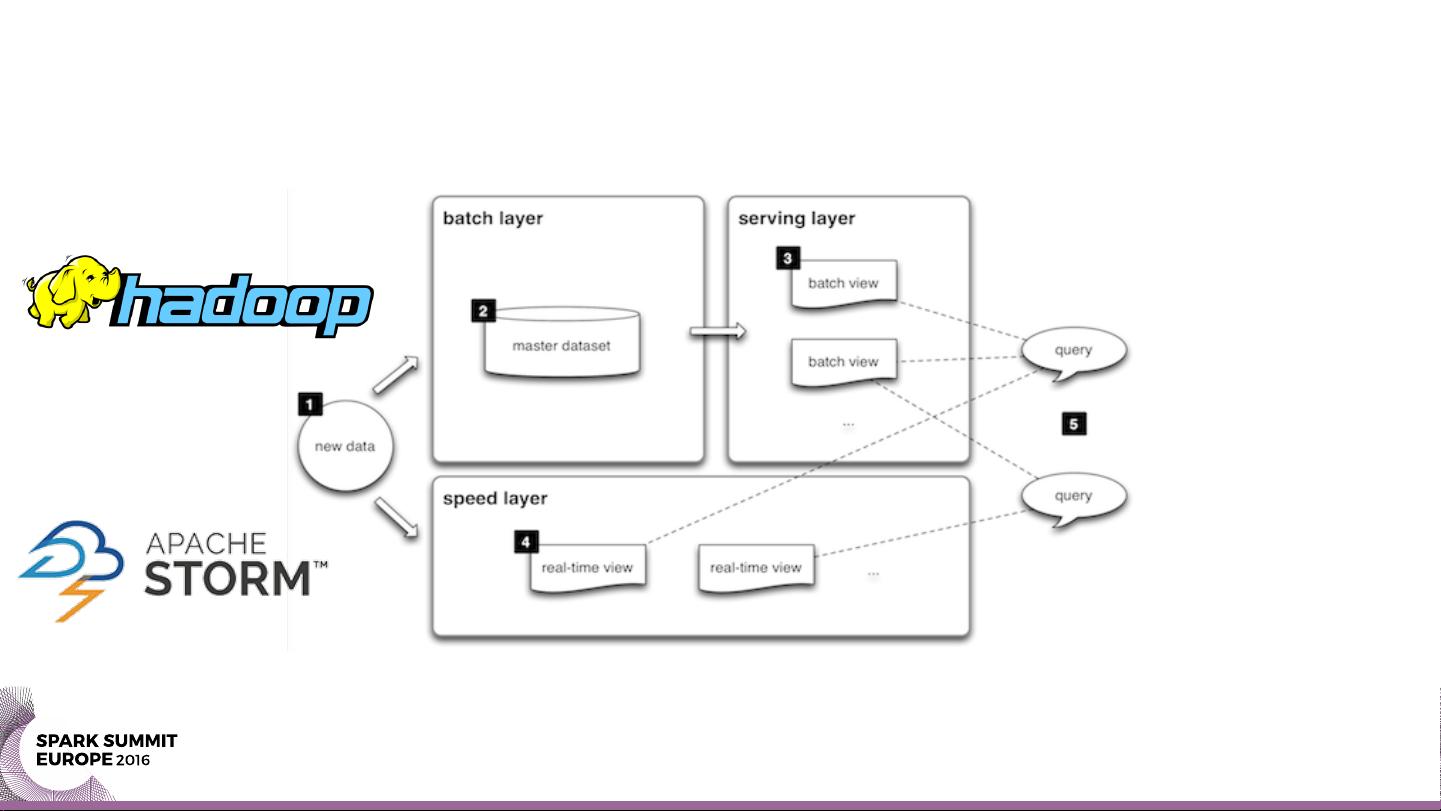
Lambda Architecture
Source: Nathan Marz (2013)
剩余26页未读,继续阅读
2024-12-25 上传

weixin_38743968
- 粉丝: 404
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- model_MEPERS
- Contacts_App
- java版商城源码-learnUrl:学习网址
- paizhao.zip
- 新星
- ACs---Engenharia:为需求工程主题的AC1创建的存储库
- tmux-power:mu Tmux电力线主题
- Flutter_frist_demo:颤振学习演示
- java版商城源码-mall:购物中心
- u5_final
- 华为模拟器企业网设计.zip
- python-random-integer-project
- aqi-tool:空气质量指数(AQI)计算器
- java版商城源码-MachiKoroDigitization:MachiKoro游戏由3人组成
- c04-ch5-exercices-leandregrimmel:c04-ch5-exercices-leandregrimmel由GitHub Classroom创建
- Monique-Nilles
