R与SAS在生物统计学中的应用指南
需积分: 9 36 浏览量
更新于2024-07-17
收藏 4.34MB PDF 举报
"《生物统计学手册》第三版是一本由John H. McDonald撰写的关于生物统计学的权威著作,提供了使用SAS和R进行统计分析的指导。书中包括了从基本概念到高级统计测试的详细解释,适用于Windows、Mac和Linux平台的免费统计编程语言R的配套指南也由Salvatore Mangiafico编写并提供,帮助读者理解和应用各种统计方法。"
《生物统计学手册》第三版涵盖了生物统计学的基本原理和各种统计测试,旨在帮助研究人员和学生深入理解生物数据的分析方法。作者首先介绍了数据分析的步骤,并讨论了生物变量的类型。接着,书中探讨了概率论,这是理解统计学的基础,包括基本的假设检验概念。在介绍这些概念时,书中特别强调了混淆变量的影响,这对于正确解读统计数据至关重要。
书中的一个重要部分是针对名义变量的测试,如精确的拟合优度检验、功效分析、卡方检验、G检验以及Fisher's精确独立性检验。这些检验用于评估分类数据之间的关联或独立性,尤其在处理小样本时需特别注意方法的选择。书中还讨论了如何处理卡方和G检验中的小数字问题,以及如何进行重复的G检验和Cochran-Mantel-Haenszel检验,以适应不同类型的独立性测试。
此外,书中还包括了描述性统计的内容,如中心趋势的统计量和离散度的度量,以及标准误差的概念,这些都是分析数据集基本信息的重要工具。书中还涉及了假设检验,如t检验和ANOVA,以及非参数检验,如Mann-Whitney U检验和Kruskal-Wallis检验,这些对于比较不同组间的差异非常有用。
对于那些需要进行大量高级统计分析的用户,作者推荐学习SAS或类似程序,但同时也指出R语言由于其自由、跨平台和日益增长的用户群体,是值得考虑的替代选择。Salvatore Mangiafico编写的R语言伴侣指南为《生物统计学手册》中的许多统计测试提供了实例程序,有助于读者快速上手R语言。
《生物统计学手册》第三版是生物科学领域进行统计分析的重要参考书,它不仅提供了理论知识,还提供了实用的计算指导,是研究者和学生提升统计分析技能的理想资源。

)*$+,##-!#.!,/#0# 1 /"* 0!'%*%/'%/"'!
!
4A!
analyzed the data using a test designed for a measurement variable, those two sleepy
isopods would cause the average time for males to be much greater than for females, and
the difference might look statistically significant. When converted to ranks and analyzed
using a non-parametric test, the last and next-to-last isopods would have much less
influence on the overall result, and you would be less likely to get a misleadingly
“significant” result if there really isn’t a difference between males and females.
Some variables are impossible to measure objectively with instruments, so people are
asked to give a subjective rating. For example, pain is often measured by asking a person
to put a mark on a 10-cm scale, where 0 cm is “no pain” and 10 cm is “worst possible
pain.” This is not a ranked variable; it is a measurement variable, even though the
“measuring” is done by the person’s brain. For the purpose of statistics, the important
thing is that it is measured on an “interval scale”; ideally, the difference between pain
rated 2 and 3 is the same as the difference between pain rated 7 and 8. Pain would be a
ranked variable if the pains at different times were compared with each other; for
example, if someone kept a pain diary and then at the end of the week said “Tuesday was
the worst pain, Thursday was second worst, Wednesday was third, etc....” These rankings
are not an interval scale; the difference between Tuesday and Thursday may be much
bigger, or much smaller, than the difference between Thursday and Wednesday.
Just like with measurement variables, if there are a very small number of possible
values for a ranked variable, it would be better to treat it as a nominal variable. For
example, if you make a honeybee sting people on one arm and a yellowjacket sting people
on the other arm, then ask them “Was the honeybee sting the most painful or the second
most painful?”, you are asking them for the rank of each sting. But you should treat the
data as a nominal variable, one which has three values (“honeybee is worse” or
“yellowjacket is worse” or “subject is so mad at your stupid, painful experiment that they
refuse to answer”).
Categorizing
It is possible to convert a measurement variable to a nominal variable, dividing
individuals up into a two or more classes based on ranges of the variable. For example, if
you are studying the relationship between levels of HDL (the “good cholesterol”) and
blood pressure, you could measure the HDL level, then divide people into two groups,
“low HDL” (less than 40 mg/dl) and “normal HDL” (40 or more mg/dl) and compare the
mean blood pressures of the two groups, using a nice simple two-sample t–test.
Converting measurement variables to nominal variables (“dichotomizing” if you split
into two groups, “categorizing” in general) is common in epidemiology, psychology, and
some other fields. However, there are several problems with categorizing measurement
variables (MacCallum et al. 2002). One problem is that you’d be discarding a lot of
information; in our blood pressure example, you’d be lumping together everyone with
HDL from 0 to 39 mg/dl into one group. This reduces your statistical power, decreasing
your chances of finding a relationship between the two variables if there really is one.
Another problem is that it would be easy to consciously or subconsciously choose the
dividing line (“cutpoint”) between low and normal HDL that gave an “interesting” result.
For example, if you did the experiment thinking that low HDL caused high blood
pressure, and a couple of people with HDL between 40 and 45 happened to have high
blood pressure, you might put the dividing line between low and normal at 45 mg/dl.
This would be cheating, because it would increase the chance of getting a “significant”
difference if there really isn’t one.
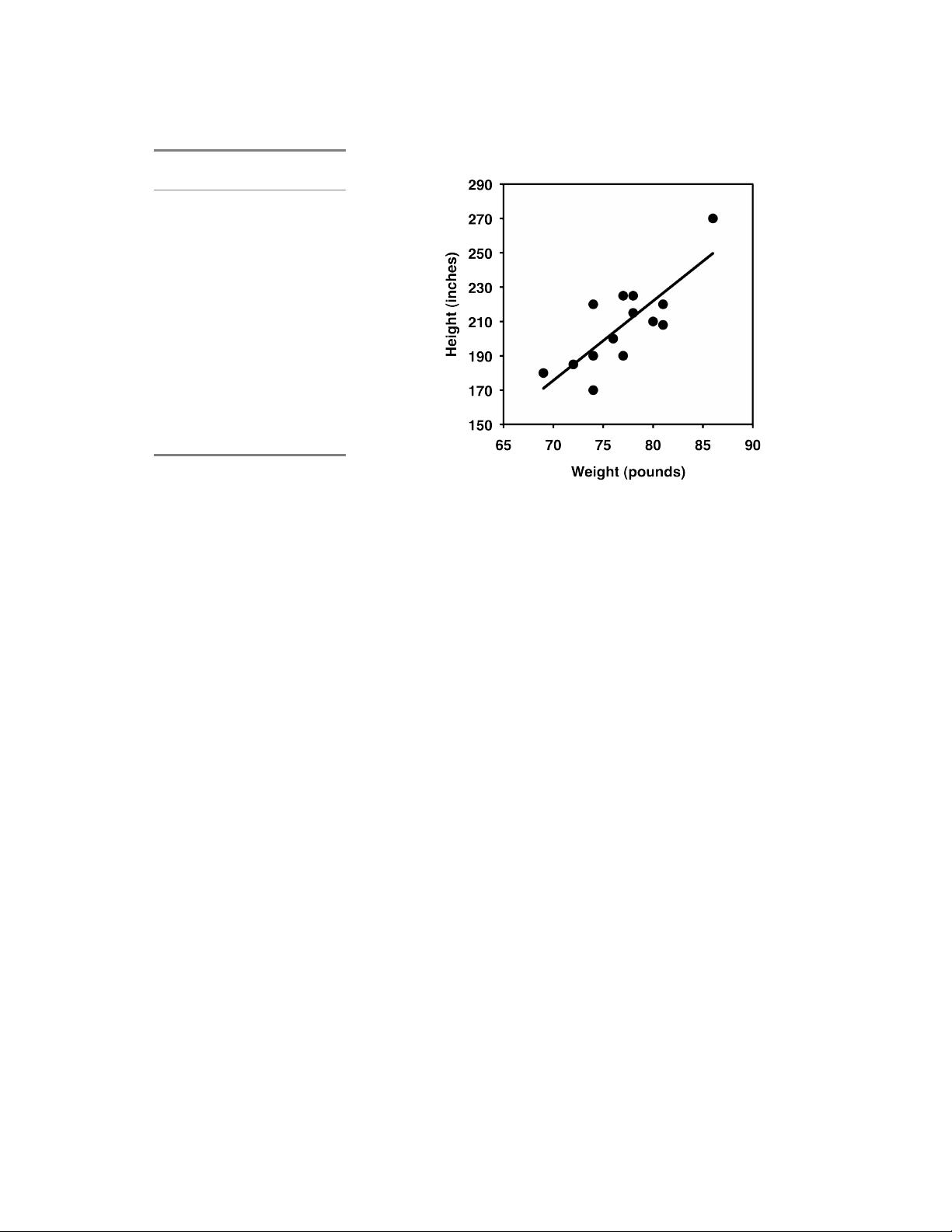
To illustrate the problem with categorizing, let’s say you wanted to know whether tall
basketball players weigh more than short players. Here’s data for the 2012-2013 men’s
basketball team at Morgan State University:



剩余304页未读,继续阅读
2021-09-08 上传
2019-08-21 上传
2021-09-08 上传
2018-02-20 上传
2012-10-01 上传
2018-12-30 上传
2018-12-26 上传

BoBoZhang
- 粉丝: 0
- 资源: 20
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
