Redis实战:布隆过滤器解决分布式缓存击穿
49 浏览量
更新于2024-08-30
收藏 640KB PDF 举报
本文将深入探讨大厂五剑客之Redis实战中的分布式缓存解决方案,着重讲解如何使用布隆过滤器来解决缓存击穿问题。在分布式系统中,缓存击穿往往发生在并发情况下,当大量请求同时访问不存在于缓存中的数据时,导致数据库压力剧增。本文档通过一个实际案例,展示了如何在Java应用中利用Redis实现布隆过滤器,一个用于快速判断数据可能存在性的概率型数据结构。
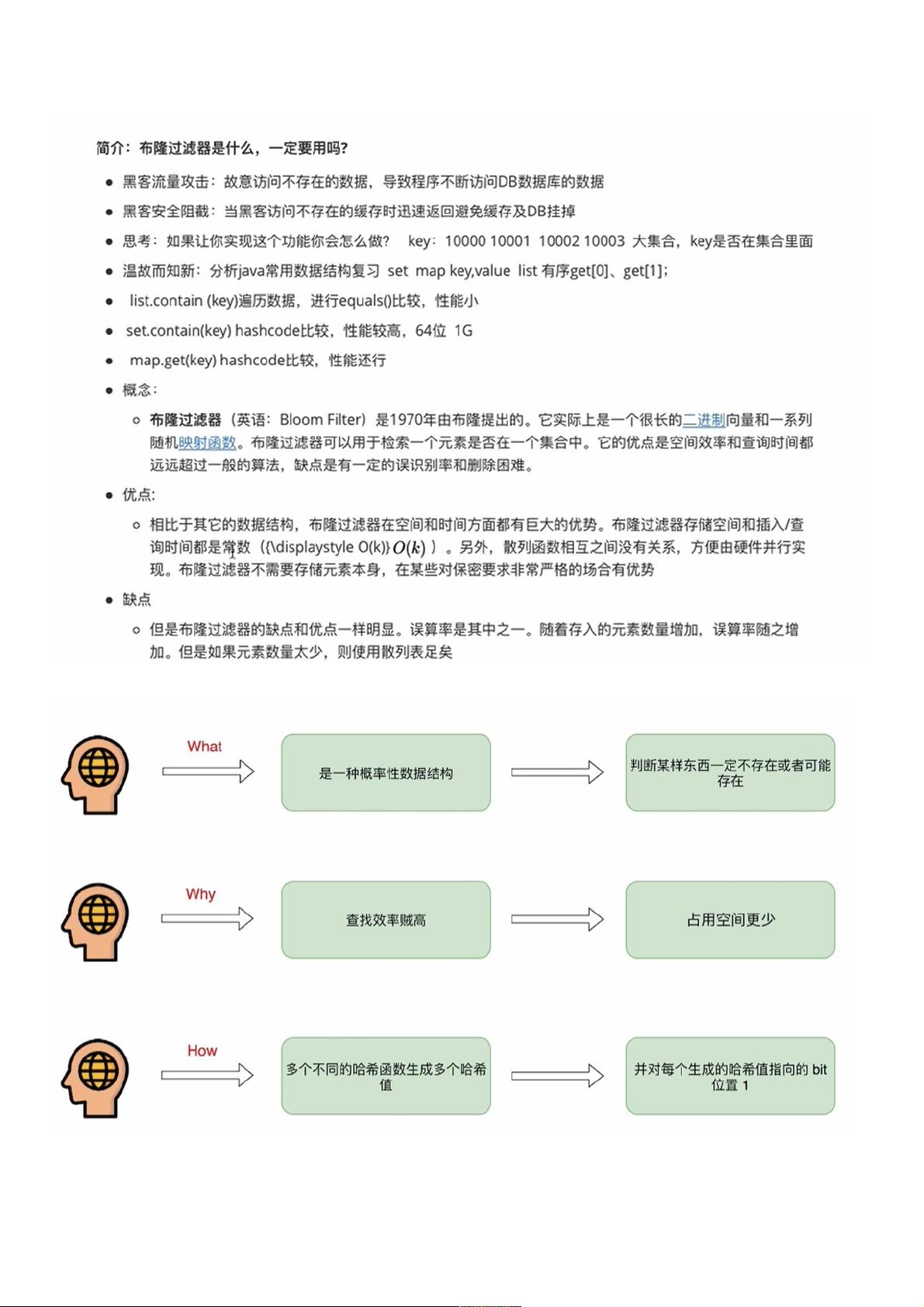
首先,布隆过滤器是一种空间效率极高的数据结构,它存储的是数据哈希值的散列映射,而不是实际数据。与Set和Map等其他数据结构并列,布隆过滤器主要用于检测数据是否“可能”存在,而非保证绝对不存在。它通过多个散列函数对键进行哈希计算,然后将结果存储在位数组中,从而提供了一种快速且低空间占用的查询机制。
在提供的代码示例中,`BloomFilterService` 类展示了布隆过滤器的具体使用。`@Resource` 注解用于注入`SysUserMapper`,以便在初始化时从数据库加载所有用户数据到内存中的布隆过滤器中。`initBloomFilter` 方法首先执行SQL查询获取所有用户,创建一个具有预设误差率(如3%)的布隆过滤器,然后将每个用户ID添加到过滤器中。`userIdExists` 方法则接受一个用户ID,使用布隆过滤器的`mightContain` 方法判断该ID是否可能存在于过滤器中。
测试部分没有在文中展示,但可以想象,开发者可能会编写单元测试或集成测试,验证布隆过滤器的正确性和性能,比如检查误报率(真阳性)和漏报率(真阴性)是否在可接受范围内。
接下来,文档可能还会讨论Redis布隆过滤器与Google的布隆过滤器实现之间的差异,以及在实际部署时如何调整参数以优化性能。此外,可能会涉及如何处理缓存更新和布隆过滤器同步的问题,以及在分布式环境中如何保证一致性。
这篇文章提供了一个关于使用Redis布隆过滤器作为分布式缓存解决方案的实战指南,旨在帮助开发者理解和解决缓存击穿问题,提升系统的可用性和性能。
大厂五剑客之大厂五剑客之redis实战分布式缓存彻底解决方案实战分布式缓存彻底解决方案—12—-布隆过滤器等布隆过滤器等
缓存击穿。
存的是数据的hashCode的内存。
布隆过滤器和set和map是平级的,是判断一定不存在还是可能存在的数据结构。
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
220 浏览量
296 浏览量
229 浏览量
187 浏览量
146 浏览量
217 浏览量
129 浏览量

weixin_38593644
- 粉丝: 4
- 资源: 914
 我的内容管理
展开
我的内容管理
展开







最新资源
- BasicFormControlPART1:如何在不关闭应用程序的情况下打开和关闭其他表单。-开源
- blog_app:博客项目
- 滑冰
- namma_utpanna
- 全国行政区划json文件
- ABlog
- 网络连接查看器 365TcpView(网络连接查看器) v3.0
- raptor_infiltrate19:#INFILTRATE19猛禽派对包
- 易语言直接使用通用型
- crux-themes-5.0.2.zip
- OSXvnc:适用于macOS的VNC服务器
- storybook-addon-image-snapshots:Storybook插件,用于基于@ storybookaddon-storyshots-puppeteer插件获取故事的图像快照
- kodluyoruzilkrepo:我在编码培训中打开了第一个回购协议
- pulumi-eks:一个Pulumi组件,可轻松创建和管理Amazon EKS集群
- 易语言硬盘分区找文件
- L128864ST7922C,c语言过tp驱动源码,c语言程序
