基于元音长度的中文语音识别:关键技术与进展
版权申诉
124 浏览量
更新于2024-07-02
收藏 8.57MB PDF 举报
本文档深入探讨了人工智能领域中的一个重要分支——中语言语音识别,特别是在基于元音长度调整的技术上。首先,作者明确了论文的主题,即SpeechRecognition(语音识别),这是一种关键的技术,旨在让计算机理解并转换人类的口头表达。论文的关键字包括Hidden Markov Model(隐马尔可夫模型)、Features Extraction(特征提取)、Dynamic Time Warping(动态时间扭曲)以及Vowel Grouping(元音分组),这些都是语音识别过程中的核心技术手段。
在第一章“绪论”部分,作者指出语音是语言的物理表现形式,承载着丰富的信息,而语音信号处理则是研究如何处理这些信号以实现有效的通信和信息存储。自1940年代Dudley的声码器发展以来,语音处理技术尤其是智能语音技术取得了显著进步,涵盖了语音压缩、编码、合成、识别等多个方向。其中,语音识别作为核心研究内容,其目标不仅是逐词转录,更在于理解并响应口述语言中的意图。
在过去的几十年里,语音识别经历了重大发展,如LPC和DTW技术的应用极大地提升了识别性能。然而,论文着重强调的是基于元音长度调整的方法,这可能是针对汉语等语言特性的一种创新策略,因为元音长度在不同语言中往往具有独特的识别标志。这种调整可能涉及到对语音信号的实时分析,通过动态调整时间参数以适应不同发音速度和元音持续时间的变化。
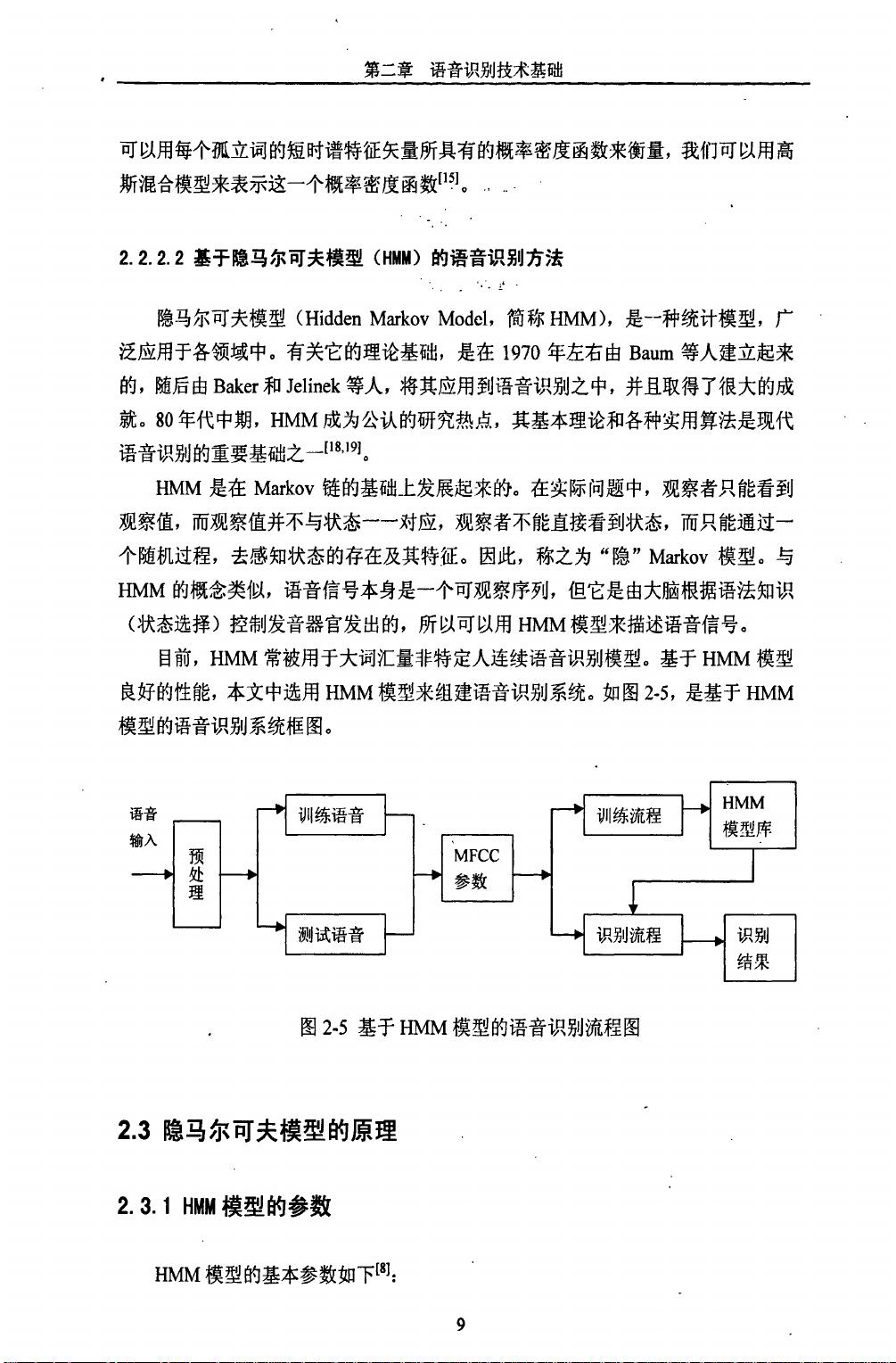
语音识别的研究历史始于50年代,60年代末和70年代初是关键时期,那时LPC和DTW技术的引入标志着语音识别技术的一个重大突破。随着信息技术的快速发展,语音识别的需求日益增长,推动着科研人员不断探索和优化技术,以满足计算机、自动化办公、通信和机器人等领域的需求。
本论文深入剖析了语音识别技术的理论基础,特别是在元音长度调整这一技术细节上的应用,展示了其在人工智能领域的前沿进展,并探讨了其在实际应用中的潜力和挑战。对于语音识别的未来发展趋势和跨学科合作的重要性,本文也给予了充分的关注。

剩余54页未读,继续阅读
2021-08-18 上传
2022-07-03 上传
2021-09-30 上传
2021-09-07 上传
2021-10-10 上传
2021-10-29 上传

programhh
- 粉丝: 8
- 资源: 3741
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
