4nm旗舰手机SoC中的多模式8K-MACHW神经处理单元
需积分: 10 133 浏览量
更新于2024-07-05
收藏 42.53MB PDF 举报
"ISSCC2022_Session_15_PPT 涉及的主题是机器学习处理器,特别是介绍了一个在4纳米旗舰移动SoC中的多模式8K-MACHW利用率感知神经处理单元,该单元拥有统一的多精度数据路径。报告内容涵盖了设计动机、NPU架构、关键特性(如可配置的数据预取和执行、统一的多精度乘加器、动态操作模式)、测量结果以及与其他方案的比较。"
本文主要讨论的是在2022年国际固态电路会议(ISSCC)第15会话中关于机器学习处理器的创新设计。这个特定的演讲重点是一个针对4纳米工艺旗舰移动系统级芯片(SoC)的多模式8K-MACHW利用率感知神经处理单元(NPU)。MACHW可能是指机器学习操作中的计算核心或硬件单元,8K则可能指处理能力的规模,与高分辨率图像处理或大数据集处理相关。
1. **设计动机**:
设计的动机在于解决现代移动设备中神经网络计算效率和能效的问题。随着深度学习应用的增加,需要更高效、灵活且能适应不同工作负载的处理单元,以优化能源消耗并提高性能。
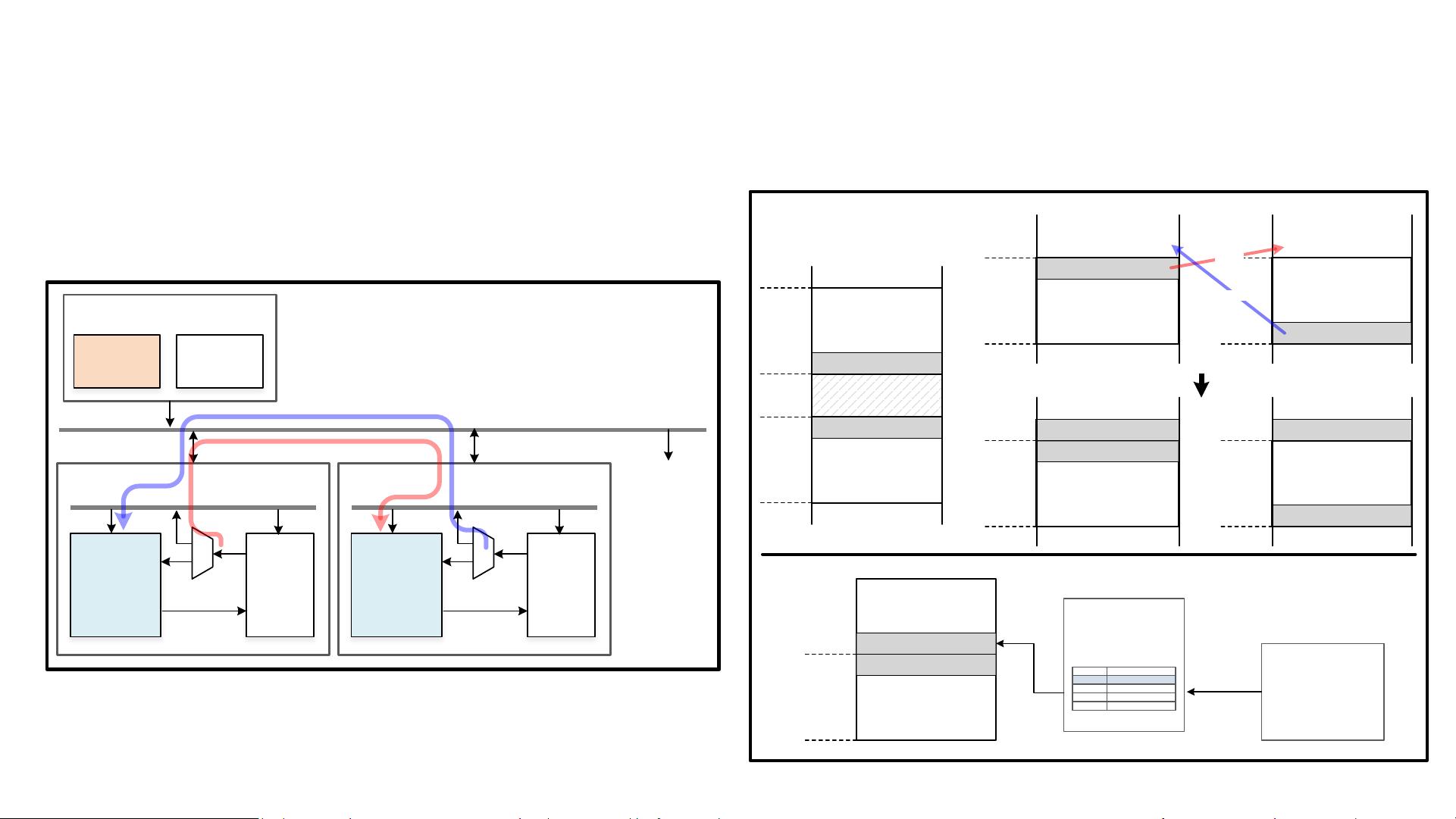
2. **NPU架构**:
NPU的架构设计旨在实现利用率最大化,通过一个统一的多精度数据路径,可以处理不同精度要求的任务。这可能包括半精度(FP16)、单精度(FP32)和更低精度的运算,以适应不同的模型和计算需求。
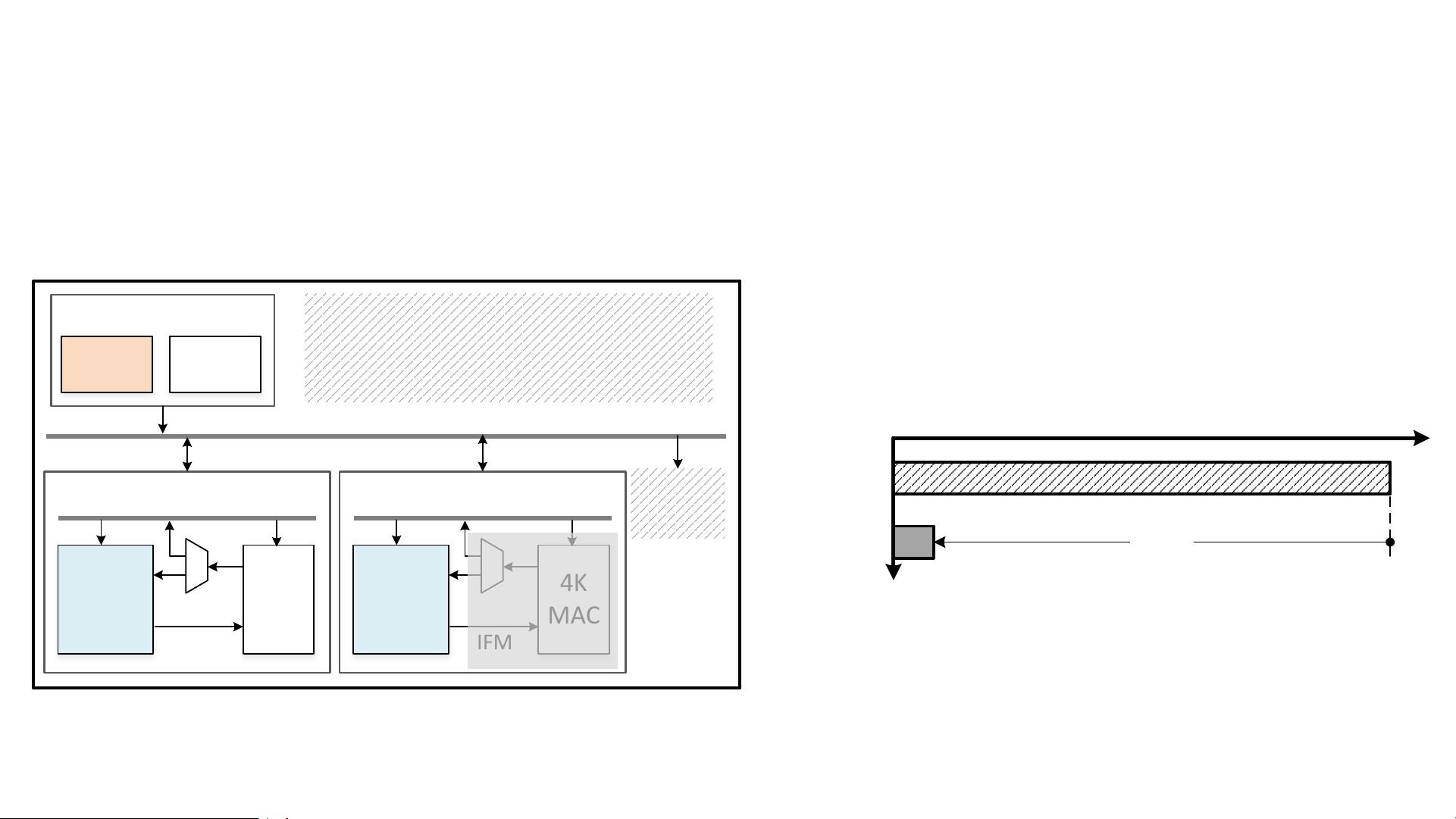
3. **关键特性**:
- **可配置的数据预取和执行**:这一特性允许处理器根据工作负载动态调整数据预取策略,以减少内存访问延迟,提高执行效率。
- **统一的多精度MACs**:多精度乘加器(MACs)是神经网络计算的核心,统一的设计意味着可以处理不同精度的运算,降低了硬件复杂性,同时提高了灵活性。
- **动态操作模式**:NPU能够根据计算需求切换到不同的操作模式,这可能包括高性能模式、低功耗模式等,以适应不同的应用场景。
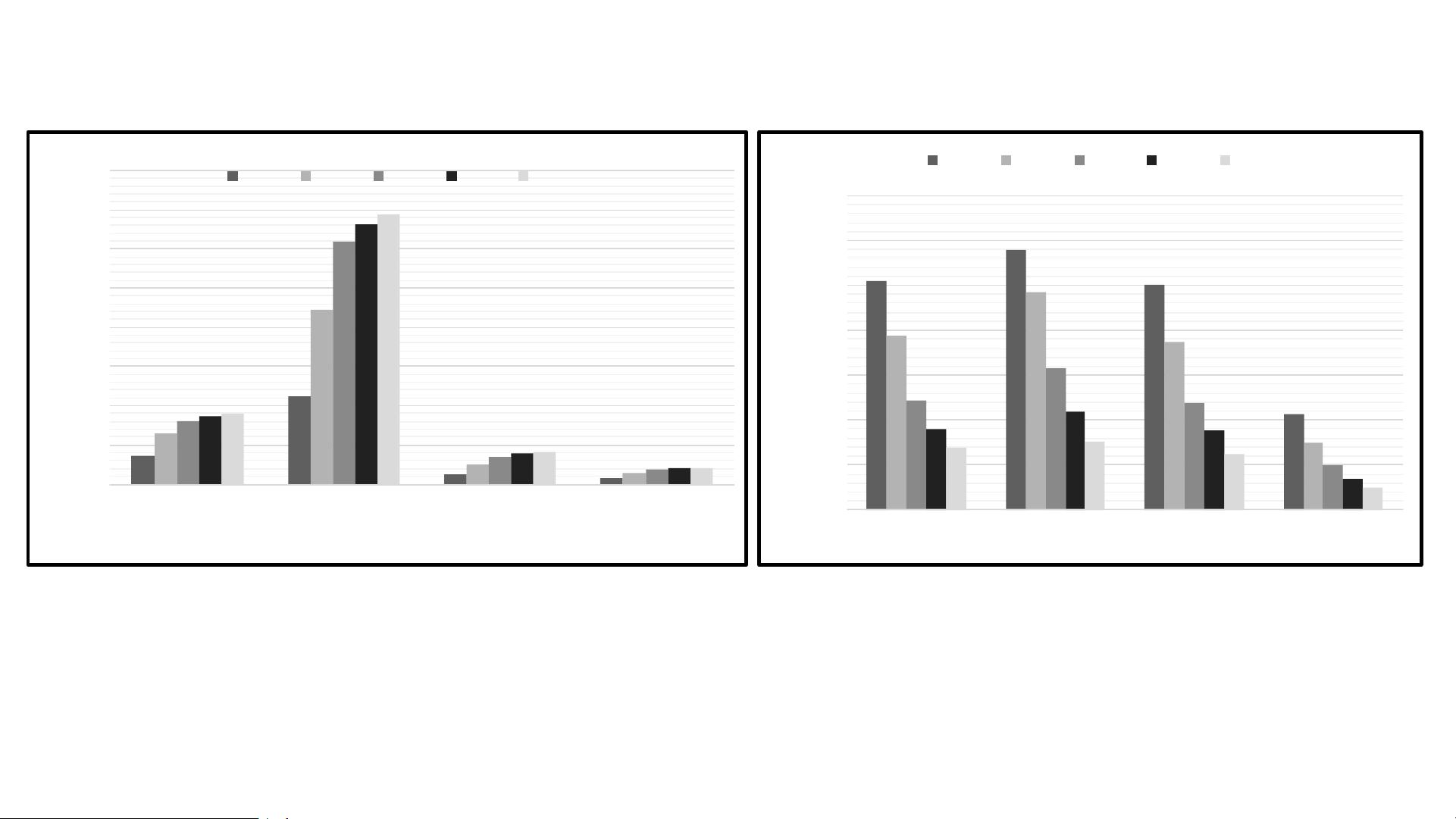
4. **测量结果**:
作者们进行了实际的性能和能效测试,这些结果可能展示了他们的设计在实际应用中的优越性,包括计算速度、能效比和对不同工作负载的适应性。
5. **比较**:
通过与其他解决方案的对比,报告可能分析了新设计相对于现有NPU的优势,如更高的性能、更低的能耗或更好的资源利用率。
这篇报告展示了在先进工艺节点上实现智能、高效且灵活的神经处理单元的最新进展,这对于推动移动设备中的AI应用具有重要意义。这种设计方法对于满足未来移动设备对高效能计算的需求,尤其是在有限的能源预算下,提供了新的思路和解决方案。
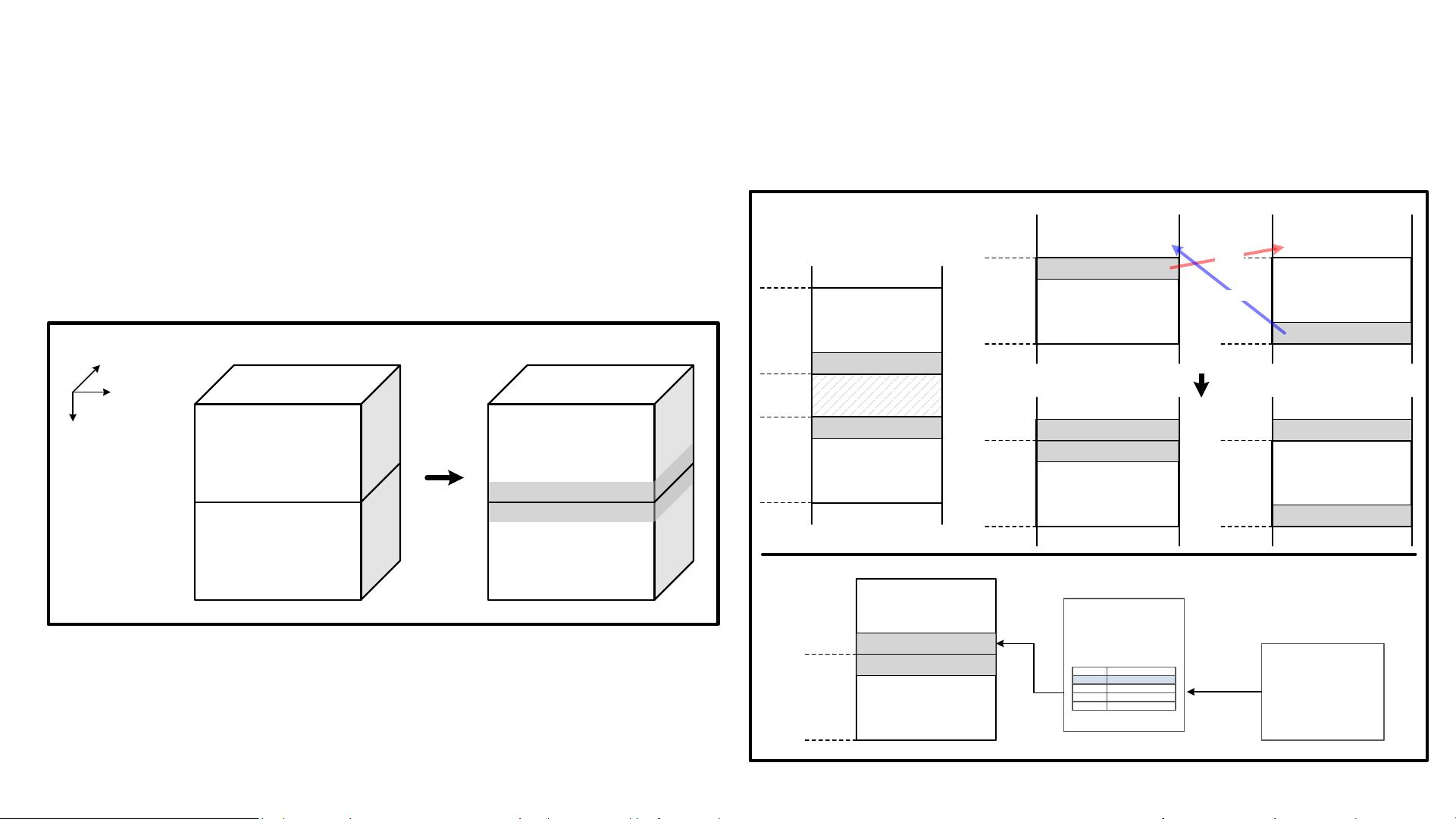
15.1: A Multi-Mode 8K-MAC HW-Utilization-Aware Neural Processing Unit with a Unified Multi-Precision Datapath in 4nm Flagship Mobile SoC
© 2022 IEEE
International Solid-State Circuits Conference
Low-latency mode
Two NPU cores process a network together for minimize latency.
Core #0
Translation
Lookaside
Buffer
ADDR remapper
0x2000
RD req
0x1000
A (halo for Core #1)
TCM
0x1800
B (halo from Core #1)
0x1900
0x1900
0x1000
A (halo for Core #1)
Reserved
0x2000
B (halo for Core #0)
Memory map:
Programming
model
0x2800
IFM #0
IFM #1
0x1800
0x1000
A (halo for Core #1)
IFM #0
0x1800
Core #0
TCM
0x2000
B (halo for Core #0)
IFM #1
0x2800
Core #1
TCM
write
write
0x1000
A (halo for Core #1)
IFM #0
0x1800
0x2000
B (halo for Core #0)
IFM #1
0x2800
B (halo from Core #1) A (halo from Core #0)
0x1900 0x2900
After data mirroring
OFM #0
OFM #1
Channel
Width
Height
Core #0
Core #1
layer (n)
IFM #0
IFM #1
A
(halo for Core #1)
B
(halo for Core #0)
layer (n+1)
12 of 19

剩余357页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-03-28 上传
2022-03-28 上传
2022-03-28 上传
2022-03-28 上传
2022-03-28 上传
2022-03-28 上传

netshell
- 粉丝: 11
- 资源: 185
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
