Spark与Scala安装步骤指南
需积分: 10 100 浏览量
更新于2024-08-05
收藏 440KB DOCX 举报
"Spark&Scala安装教程文档详细指导了如何在Ubuntu系统上安装Spark和Scala环境,适合初学者。"
Spark和Scala是大数据处理领域的重要工具,Spark作为一个快速、通用且可扩展的数据处理引擎,而Scala则是一种多范式编程语言,提供了面向对象和函数式编程的特性,是开发Spark应用的首选语言。以下是对安装教程的详细解读:
1. **Spark环境安装**
- 首先,需要在`/usr/local`目录下创建一个名为`spark`的目录,这可以通过执行`sudo mkdir /usr/local/spark`命令完成。
- 接着,从清华大学镜像站点下载Spark安装包,版本为`2.4.5-bin-hadoop2.7`,使用`wget`命令下载。
- 安装包下载完成后,使用`sudo tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz`进行解压。
- 进入解压后的目录并找到`conf`子目录,复制`spark-env.sh.template`为`spark-env.sh`。
2. **配置Spark环境变量**
- 打开`spark-env.sh`文件,设置必要的环境变量。例如:
- `SCALA_HOME`指向Scala的安装路径。
- `JAVA_HOME`指定Java SDK的路径,这里假设为`/usr/local/java/jdk1.8.0_191`。
- `HADOOP_HOME`为Hadoop的安装路径,如果未安装Hadoop,可以不设置或根据实际情况调整。
- `SPARK_MASTER_IP`设置为`localhost`,表示Spark运行在本地模式。
- `SPARK_LOCAL_DIRS`指定Spark的工作目录。
- `SPARK_DRIVER_MEMORY`设置驱动程序内存大小,这里是512MB。
3. **修改slaves文件**
- 将`slaves.template`重命名为`slaves`,但在这个安装教程中,似乎不需要修改文件内容。
4. **配置系统环境变量**
- 使用`sudo vim /etc/bash.bashrc`编辑bash配置文件,添加Spark的环境变量`SPARK_HOME`。
5. **使环境变量生效**
- 保存并退出`/etc/bash.bashrc`后,需运行`source /etc/bash.bashrc`使新配置的环境变量生效。
6. **安装Scala**
- 为了运行Spark,需要先安装Scala。类似Spark的安装步骤,下载Scala安装包(例如scala-2.12.12.tgz),解压并设置环境变量`SCALA_HOME`。
7. **验证安装**
- 安装完成后,可以启动Spark的Shell来验证安装是否成功,通过`$SPARK_HOME/bin/spark-shell`命令启动。
以上就是Spark和Scala在Ubuntu系统上的基础安装过程。对于初学者来说,理解这些步骤非常重要,因为它们构成了运行Spark应用的基础。确保每个步骤都正确执行,将有助于后续的开发和测试工作。如果遇到任何问题,建议查阅官方文档或社区资源以获取帮助。
Spark&Scala 安装教程
一、安装 Spark 环境
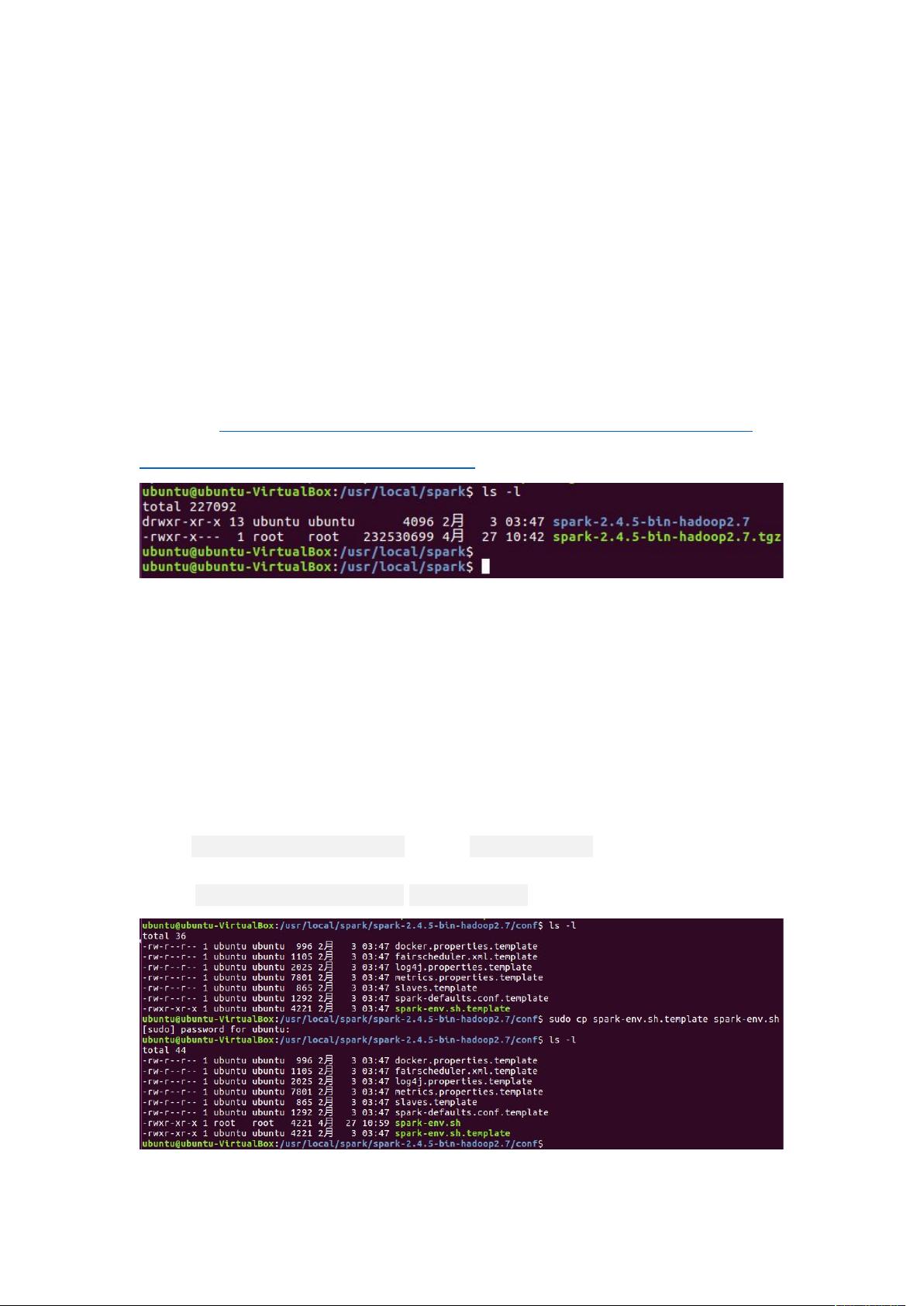
、进入 目录,操作命令 ,新建 目录,操作命
令 ,并下载 安装包
:
。
、解压 安装包,操作命令 !"
。
#、进入 安装目录,操作命令
,进入 配置文件目录,操作命令 ",并将配置文
件 ! 复制为 ! 文件,操作命令
!!。
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-07-12 上传
2024-07-12 上传
2020-10-18 上传
2021-04-05 上传

weixin_56936835
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
