机器学习基石:过拟合的危害与理解
需积分: 0 64 浏览量
更新于2024-08-05
收藏 1.04MB PDF 举报
"林轩田《机器学习基石》课程笔记13 -- Hazard of Overfitting1"
过拟合(Overfitting)是机器学习中一个关键的问题,它指的是模型在训练数据上表现极好,但在未见过的测试数据或新数据上表现糟糕的现象。过拟合通常发生在模型过于复杂,过度学习了训练数据中的噪声和细节,导致模型失去了对一般规律的捕捉能力。
一、什么是Overfitting?
过拟合(Overfitting)是模型在训练数据上拟合得过于紧密,以至于模型对训练数据中的随机噪声和异常点过于敏感,丧失了对新数据的泛化能力。这种情况下,模型在训练集上的误差很低,但在验证集或测试集上的误差较高。
二、噪声与数据量的作用
噪声是指数据中与目标变量无关的信息,它可能存在于输入特征中或者目标变量的测量误差中。数据量的大小直接影响模型是否容易过拟合。少量数据更容易导致过拟合,因为模型有机会学习到数据中的噪声,而大量的数据可以帮助模型更好地学习到数据的普遍规律,减少过拟合的风险。
三、确定性噪声
确定性噪声指的是数据中存在的固定不变的不准确部分,它与输入特征无关,但会影响模型的预测。在有限的数据集上,过于复杂的模型可能会过度关注这些噪声,从而导致过拟合。
四、模型复杂度与Vapnik-Chervonenkis维数(VC维)
Vapnik-Chervonenkis维数(VCDimension)是衡量模型复杂度的一个重要概念,它表示模型能划分的最多不同数据点的集合的大小。VCDimension越大,模型越复杂,过拟合的风险越高。VC曲线显示了模型复杂度与训练误差和泛化误差的关系。在某个最优的VCDimension下,模型能达到最小的泛化误差。
过拟合和欠拟合(Underfitting)之间的区别在于,欠拟合是模型无法捕获数据的基本模式,表现为模型对训练和测试数据的误差都较大。而过拟合则是模型过度学习了训练数据,训练误差低但测试误差高。
过拟合的原因包括但不限于:
1. 模型过于复杂,如使用高阶多项式或深度神经网络。
2. 训练数据量不足,不足以支撑复杂模型的学习。
3. 数据噪声过大,模型过度关注噪声而忽视了主要趋势。
4. 正则化不足,没有适当限制模型参数的自由度。
防止过拟合的方法包括:
1. 增加数据量,引入更多样化的样本。
2. 使用正则化技术,如L1和L2正则化,限制模型参数的权重。
3. 早停策略,监控验证集误差,在验证误差开始上升时停止训练。
4. 数据增强,通过对原始数据进行旋转、缩放等操作生成新的训练样本。
5. 使用集成学习方法,如随机森林或梯度提升机,减少单个模型的过拟合风险。
总结来说,过拟合是机器学习中的重要挑战,理解和解决这个问题对于构建具有优秀泛化能力的模型至关重要。通过合理选择模型复杂度、应用正则化技术以及充分利用数据,可以有效地避免过拟合,提高模型在实际应用中的性能。
作者:红色石头 公众号:AI有道(id:redstonewill)
上节课我们主要介绍了非线性分类模型,通过非线性变换,将非线性模型映射到另一
个空间,转换为线性模型,再来进行分类,分析了非线性变换可能会使计算复杂度增
加。本节课介绍这种模型复杂度增加带来机器学习中一个很重要的问题:过拟合
(overfitting)。
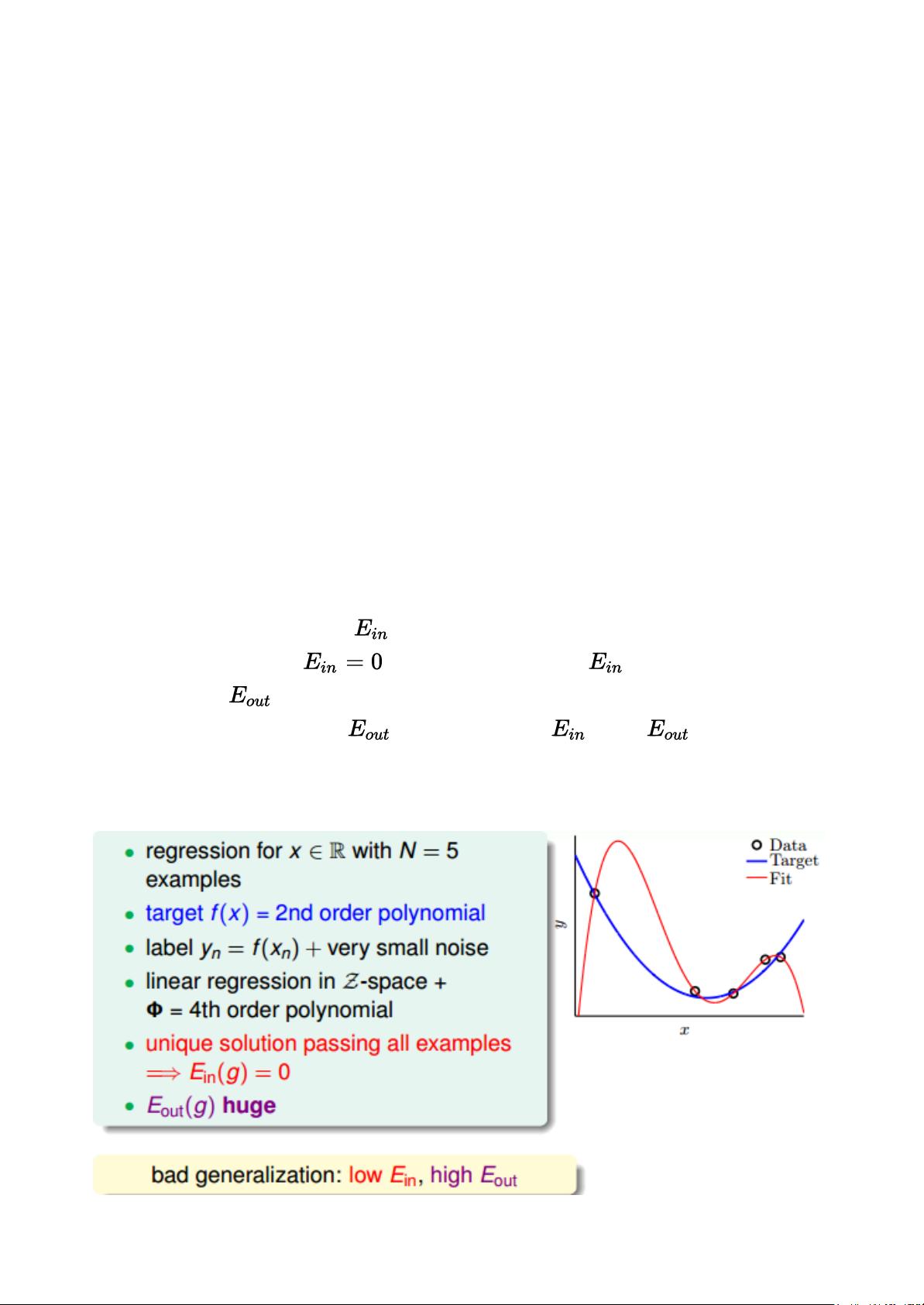
首先,我们通过一个例子来介绍什么badgeneralization。假设平面上有5个点,目标
函数f(x)是2阶多项式,如果hypothesis是二阶多项式加上一些小的noise的话,那么这
5个点很靠近这个hypothesis, 很小。如果hypothesis是4阶多项式,那么这5点会
完全落在hypothesis上, 。虽然4阶hypothesis的 比2阶hypothesis的要好
很多,但是它的 很大。因为根据VCBound理论,阶数越大,即VCDimension越
大,就会让模型复杂度更高, 更大。我们把这种 很小, 很大的情况称之
为badgeneration,即泛化能力差。
我们回过头来看一下VC曲线:
林轩田《机器学习基石》课程笔记13Hazardof
Overfitting
一、WhatisOverfitting?
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-10-21 上传
2021-04-27 上传
2021-05-26 上传
2018-11-06 上传
2020-02-16 上传
2021-06-21 上传

陌陌的日记
- 粉丝: 18
- 资源: 318
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
