NIPS 2016: David Blei的变分推理教程
需积分: 9 117 浏览量
更新于2024-07-18
收藏 24.85MB PDF 举报
"NIPS 2016 Variational Inference Tutorial by David Blei"
NIPS (Neural Information Processing Systems) 是一个国际知名的机器学习和计算神经科学会议,每年都会聚集全球顶尖的研究人员和从业者,分享最新的研究成果和技术。2016年的NIPS大会上,David Blei、Rajesh Ranganath和Shakir Mohamed共同进行了一个关于变分推断(Variational Inference)的教程。变分推断是统计学和机器学习领域中的一种重要方法,尤其在处理高维复杂数据时,如主题模型、贝叶斯网络和深度学习模型中。
变分推断是一种近似推理技术,用于解决贝叶斯框架下的后验概率计算问题。在实际应用中,我们通常面对的是无法解析求解的后验分布,而变分推断通过寻找一个易于处理的分布家族来逼近这个复杂的后验分布。这种方法通常涉及将目标函数(例如,证据下界ELBO,Evidence Lower Bound)最大化,以找到最接近真实后验的变分分布。
在NIPS 2016的这个教程中,他们可能探讨了变分推断的基本原理,包括变分分布的选择、优化算法以及在各种模型中的应用。例如,他们可能提到了Gopalan和Blei在2013年PNAS发表的工作,该工作展示了如何使用变分推断在370万节点的美国专利网络中发现社区结构。
此外,变分推断的应用广泛,涵盖了从自然语言处理(NLP)到图像分析的多个领域。例如,它可以用于主题模型(如Latent Dirichlet Allocation, LDA),帮助分析文本数据中的隐藏主题;在游戏分析中,可以理解团队表现和球员影响力;在金融市场预测中,可以估计股票市场动态和投资者行为;在社会科学研究中,可以探索政治派别和选举趋势;在影视行业中,可以预测电影和电视节目的成功;甚至在房地产领域,用于房地产开发和市场趋势的建模。
教程可能还涵盖了现代变分推断的方法,比如自动差异化变分推断(Automatic Differentiation Variational Inference, ADVI)、变分自编码器(Variational Autoencoders, VAEs)和黑盒变分推断(Black Box Variational Inference),这些方法大大扩展了变分推断的适用范围,并增强了其在深度学习模型中的应用。
通过深入理解变分推断,研究人员和工程师能够更有效地处理不确定性,进行有效的参数估计,并在有限的计算资源下构建复杂的模型。NIPS 2016的这个教程对于希望掌握这一关键工具的AI专业人士来说,无疑是一份宝贵的资源。
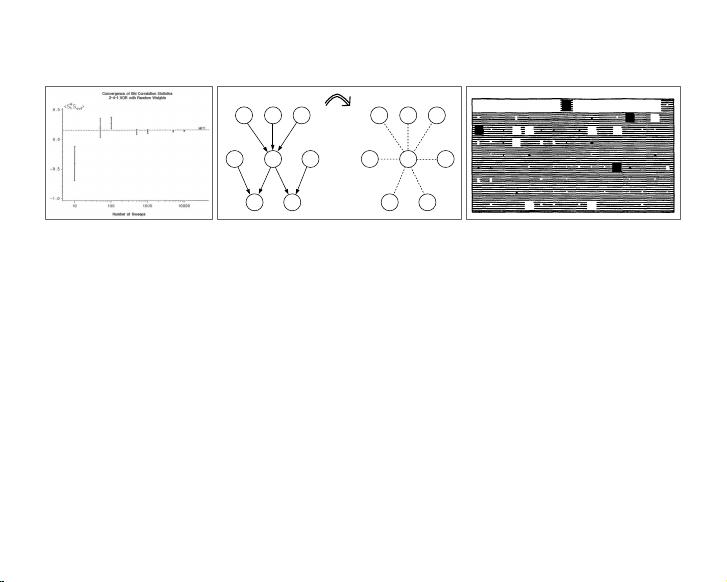
History
1006
Carsten Peter son and J ames R . An derson
Coovergence 0 1 eM ColTeia llon Sta
bile
s
2-
04
-1 XOR wilh Random
WetgltJ
0
.0
- 0. 5
'0
' 0 0
1000 10000
t.\ntler
01 SWe8plll
Figure
5: {sf'Bo ut} a nd
vt
v
out
from th e B M
and
MFT
respec t ively
as fu
nct
ionsof
Nsweep
o For detailson archite ct ure, an nealing sche d ule ,
an d
Ti
j values, see figure 3.
Corw
flfOOOC
ll 01
L4e
an
Ca
relallon Oi
llerence
2-4 -1 XOR with Random Welltll l
J
•
•
•
•
•
•
_ _ _
' 0 ' 0 0
1000 10000
tbnber
01 SWeepli
Figure 6 :
Do
as defined in equa tion (3 .17) as a fu n ctio n of N
stKeep
•
For
detai lson architec t u re, a nne ali ng sched ule, and
T ij values, see figure
3.
[Peterson and Anderson 1987]
(a)
(b)
S
i
i
µ
S
j
j
µ
Figure 22: (a) A node S
i
in a sigmoid belief network machine with its Markov blanket. (b)
The mean field equations yield a deterministic relationship, represented in the figure with
the dotted lines, between the variational parameters µ
i
and µ
j
for no des j in the Markov
blanket of node i.
atractablelowerboundontheloglikelihoodandthevariationalparameterξ
i
can be
optimized along with the other variational parameters.
Saul and Jordan (1998) show that in the limiting case of networks in which each hidden
node has a large number of parents, so that a central limit theorem can be invoked, the
parameter ξ
i
has a probabilistic interpretation as the approximate exp ectation of σ(z
i
),
where σ(·)isagainthelogisticfunction.
For fixed values o f the paramete rs ξ
i
,bydifferentiating the KL divergence with respect
to the variational parameters µ
i
,weobtainthefollowingconsistencyequations:
µ
i
= σ
⎛
⎝
#
j
θ
ij
µ
j
+ θ
i0
+
#
j
θ
ji
(µ
j
−ξ
j
)+
#
j
K
ji
⎞
⎠
(67)
where K
ji
is the derivative of −ln
&
e
−ξ
j
z
j
+ e
(1−ξ
j
)z
j
'
with respect to µ
i
.AsSaul,etal.
show, this term depends on node i,itschildj,andtheotherparents(the“co-parents”)of
node j.Giventhatthefirsttermisasumovercontributionsfromtheparentsofnodei,
and the second term is a sum over contributions from the children of node i,weseethatthe
consistency equation for a given node again involves contributions from the Markov blanket
of the node (see Fig. 22). Thus, as in the case of the Boltzmann machine, we find that the
variational parameters are linked via their Markov blankets and the consistency equation
(Eq. (67)) can be interpreted as a local message-passing algorithm.
Saul, Jaakkola, and Jordan (1996) and Saul and Jordan (1998) also show how to update
the variational parameters ξ
i
.Thetwopapersutilizetheseparametersinslightlydifferent
ways and obtain different update equations. (Yet another related variational approximation
for the sigmoid b elief network, including b oth upper and lower bounds, is presented in
Jaakkola and Jordan, 1996).
Finally, we can compute the gradient with respect to the parameters θ
ij
for fixed vari-
ational parameters µ and ξ.TheresultobtainedbySaulandJordan(1998)takesthe
39
[Jordan et al. 1999]
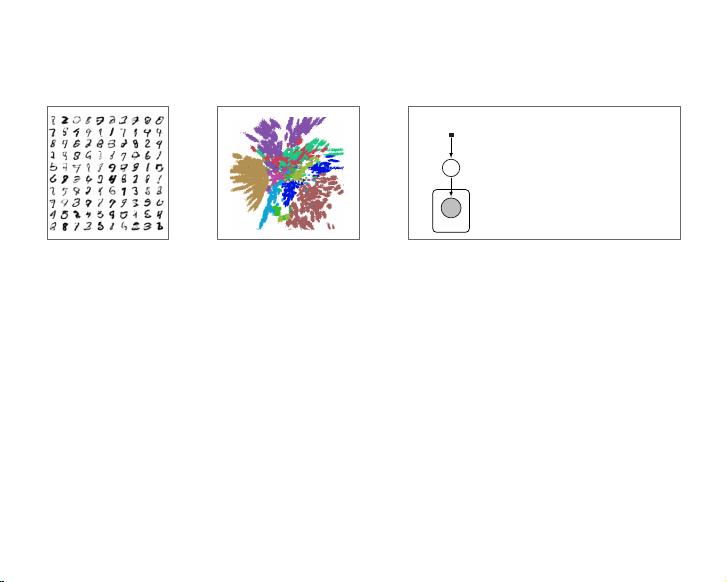
Figure 2: The final weights of the network. Each
large block represents one hidden unit. The small
black or white rectangles represent negative or
positive weights with the area of a rectangle rep
resenting the magnitude of the weight. The bot-
tom 12 rows in each block represent the incoming
weights of the hidden unit. The central weight at
the top of each block is the weight from the hidden
unit to the linear output unit. The weight at the
top-right of a block is the bias of the hidden unit.
‘~
-2 2
Figure 3: The final probability distribution that
is used for coding the weights. This distribution
is implemented by adapting the means, variances
and mixing proportions of five gauasians.
is clear that the weights form three fairly sharp clus-
ters. Figure 3 shows that the mixture of 5 Gaussians
has adapted to implement the appropriate coding-prior
for this weight distribution.
The performance of the network can be measured by
comparing the squared error it achievea on the test data
with the error that would be achieved by simply guess-
ing the mean of the correct answera for the test data:
Relative Error =
~c(dc - y.)’
~c(dc - ~)2
(27)
We ran the optimization five times using different ran-
domly chosen valuea for the initial means of the noisy
weights. For the network that achieved the lowest value
of the overall cost function, the relative error was 0.286.
This compares with a relative error of 0.967 for the same
network when we used noise-free weights and did not
penalize their information content. The best relative
error obtained using simple weight-decay with four non-
linear hidden units was .317. This required a carefully
chosen penalty coefficient for the squared weights that
corresponds to uf/a~ in equation 4. To set this weight-
decay coefficient appropriately it was necessary to try
many different values on a portion of the training set
and to use the remainder of the training set to decide
which coefficient gave the best generalization. Once the
beat coefficient had been determined the whole of the
training set was used with this coefficient. A lower er-
ror of 0.291 can be achieved using weight-decay if we
gradually increase the weight-decay coefficient and pick
the value that gives optimal performance on the test
data. But this is cheating. Linear regression gave a
huge relative error of 35.6 (gross overfitting) but this
fell to 0.291 when we penalized the sum of the squarea
of the regression coefficients by an amount that was ch~
sen to optimize performance on the test data. This is
almost identical to the performance with 4 hidden units
and optimal weight-decay probably because, with small
weights, the hidden units operate in their central linear
range, so the whole network is effectively linear.
11
[Hinton and van Camp 1993]
Variational inference adapts ideas from statistical physics to probabilistic
inference. Arguably, it began in the late eighties with Peterson and
Anderson (1987), who used mean-field methods to fit a neural network.
This idea was picked up by Jordan’s lab in the early 1990s—Tommi
Jaakkola, Lawrence Saul, Zoubin Gharamani—who generalized it to
many probabilistic models. (A review paper is Jordan et al., 1999.)
In parallel, Hinton and Van Camp (1993) also developed mean-field for
neural networks. Neal and Hinton (1993) connected this idea to the EM
algorithm, which lead to further variational methods for mixtures of
experts (Waterhouse et al., 1996) and HMMs (MacKay, 1997).


剩余161页未读,继续阅读
513 浏览量
171 浏览量
191 浏览量
742 浏览量
2025-02-26 上传
2025-01-08 上传
286 浏览量
2025-02-07 上传
321 浏览量

YongXien
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Openaea:Unity下开源fanmad-aea游戏开发
- Eclipse中实用的Maven3插件指南
- 批量查询软件发布:轻松掌握搜索引擎下拉关键词
- 《C#技术内幕》源代码解析与学习指南
- Carmon广义切比雪夫滤波器综合与耦合矩阵分析
- C++在MFC框架下实时采集Kinect深度及彩色图像
- 代码研究员的Markdown阅读笔记解析
- 基于TCP/UDP的数据采集与端口监听系统
- 探索CDirDialog:高效的文件路径选择对话框
- PIC24单片机开发全攻略:原理与编程指南
- 实现文字焦点切换特效与滤镜滚动效果的JavaScript代码
- Flask API入门教程:快速设置与运行
- Matlab实现的说话人识别和确认系统
- 全面操作OpenFlight格式的API安装指南
- 基于C++的书店管理系统课程设计与源码解析
- Apache Tomcat 7.0.42版本压缩包发布
