FlinkX:企业数据入湖利器——支持多源同步与增量处理
版权申诉
FlinkX在数据入湖中的应用
FlinkX是中移(苏州)软件技术有限公司于2021年11月推出的一款专注于数据同步和处理的工具,它基于Apache Flink框架设计,旨在解决企业级数据迁移和集成过程中遇到的各种复杂需求。FlinkX的核心价值在于其分布式、实时和离线数据同步的能力,以及对多个异构数据源的支持,包括常见的关系型数据库(如Oracle、MySQL、PostgreSQL、Oracle、SqlServer等)、NoSQL数据库(如MongoDB)、键值存储(如Redis)、图形数据库(如Neo4j)以及大数据存储系统(如HDFS和S3)。
FlinkX的设计目标是克服传统数据同步工具如Sqoop和DataX在特定功能上的不足。相较于Sqoop,FlinkX提供了更现代的分布式架构,支持分布式运行模式,能够更好地应对大规模数据的处理,并具备断点续传和增量同步的能力,这对于数据仓库的持续加载和维护至关重要。此外,FlinkX还允许用户通过SQL提交任务,增强了灵活性,并且在版本1.12及以后实现了SQL支持,进一步简化了数据分析工作流程。
FlinkX的优势还包括插件丰富度较高,使得开发者可以方便地添加新的数据源支持或实现自定义操作。同时,它的消息队列集成、速度控制和监控统计功能也是一大亮点,有助于提高数据同步的稳定性和效率。社区支持方面,虽然起初FlinkX的社区评级可能稍逊于Sqoop,但随着项目的持续发展,其社区活跃度和功能完善程度正逐渐提升。
在实际的企业数据使用场景中,由于传统关系型数据库(RDBMS)如MySQL和Oracle在处理大数据量时可能存在性能瓶颈,企业往往需要将这些数据迁移到如Hadoop HDFS或Amazon S3这样的分布式存储系统(即数据湖),以便利用其分布式计算能力进行分析。FlinkX作为这个过程中的关键组件,简化了这一过程,使得企业能够更加高效地管理和利用数据,满足不同场景下的数据处理需求。
总结来说,FlinkX凭借其强大的数据同步功能、分布式架构和广泛的数据源支持,正在成为企业数据湖构建和管理中不可或缺的工具,为企业提供了一种灵活、高效的方式来整合和处理异构数据,推动大数据时代的业务创新和发展。
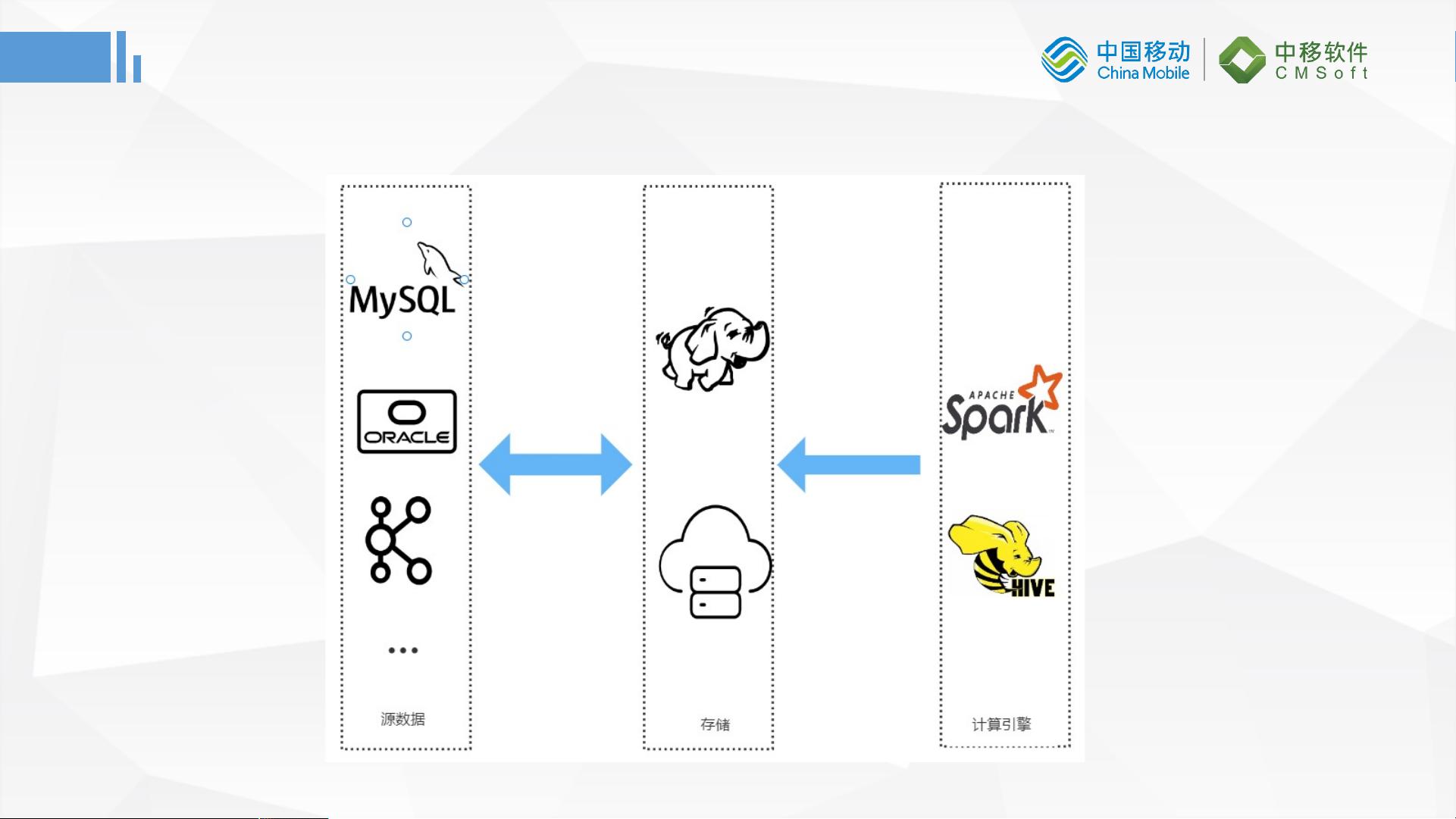
企业数据使用现状
实际情况:业务库多数是MySQL、Oracle等传统RDB,不方便进行大数据量的开发计算,通常都需要将RDB数据同步到开发平
台或者云端,利用分布式的存储计算能力。
剩余25页未读,继续阅读
2021-12-07 上传
2019-12-13 上传
2020-07-28 上传
2023-07-12 上传
2023-08-22 上传
2023-03-30 上传
2024-01-17 上传
2019-06-03 上传
2021-11-30 上传









