知识图谱中的表示学习与信息融合:词向量模型与深度理解
需积分: 10 20 浏览量
更新于2024-07-19
收藏 6.17MB PDF 举报
在知识图谱的研究中,表示学习与知识获取是一项关键任务,它旨在理解和利用结构化的世界知识来解决复杂的信息处理问题。本文将深入探讨这个领域的核心概念和技术。
首先,研究对象主要关注网络结构,如用户及其关系和行为,以及媒体信息,包括文本、视频、语音等多元化的数据形式。知识图谱作为这些信息的核心载体,通过实体、属性和关系构成一个结构化的知识体系,能够捕捉实体之间的语义关联。
知识图谱面临的挑战在于信息的多源异构性,即不同来源的数据可能有不同的格式和含义,这使得建立清晰的语义关联变得困难。传统的基于符号的表示方法试图通过精确的逻辑规则来表达知识,但面对大规模、复杂的数据时显得力不从心。
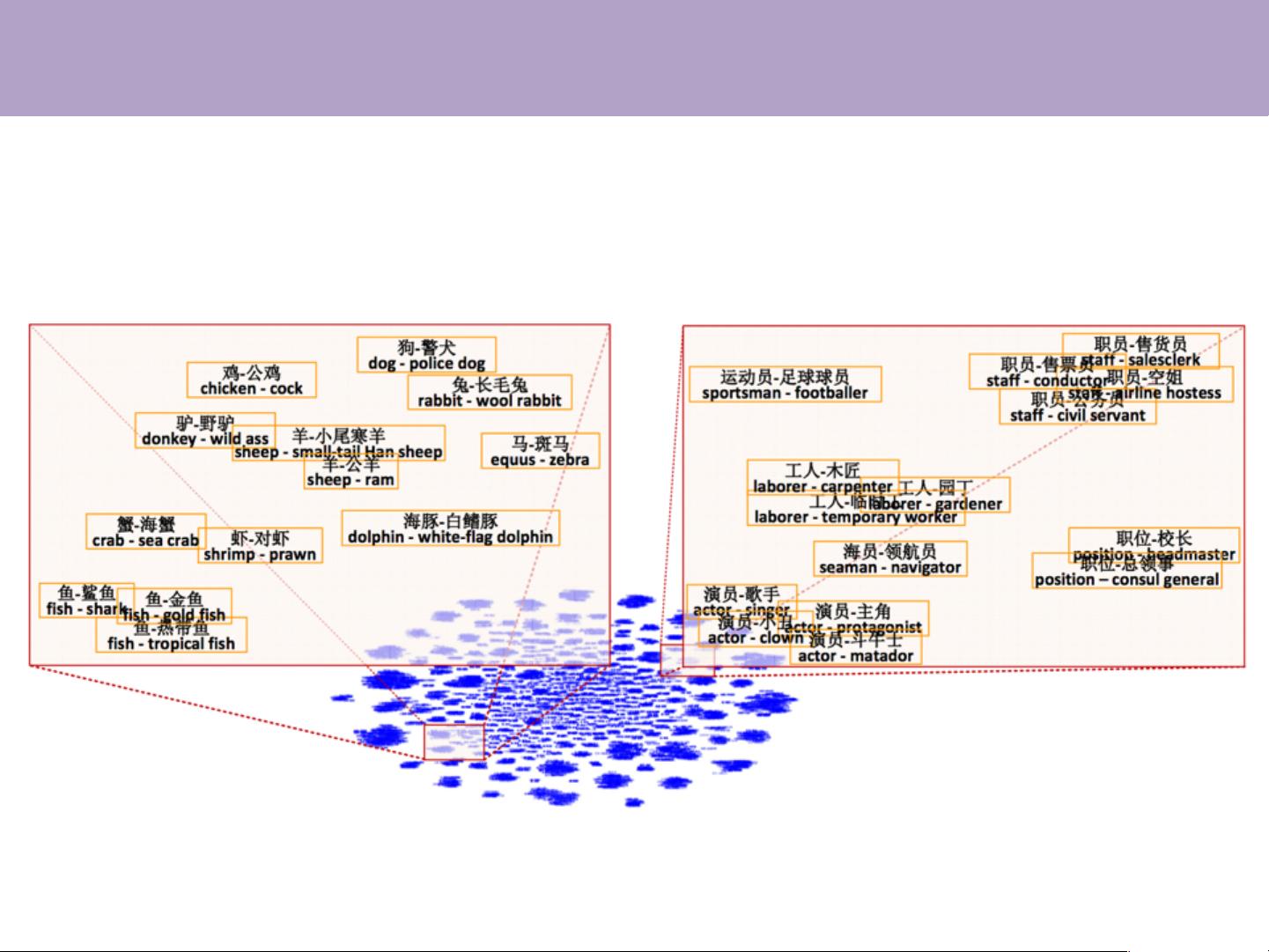
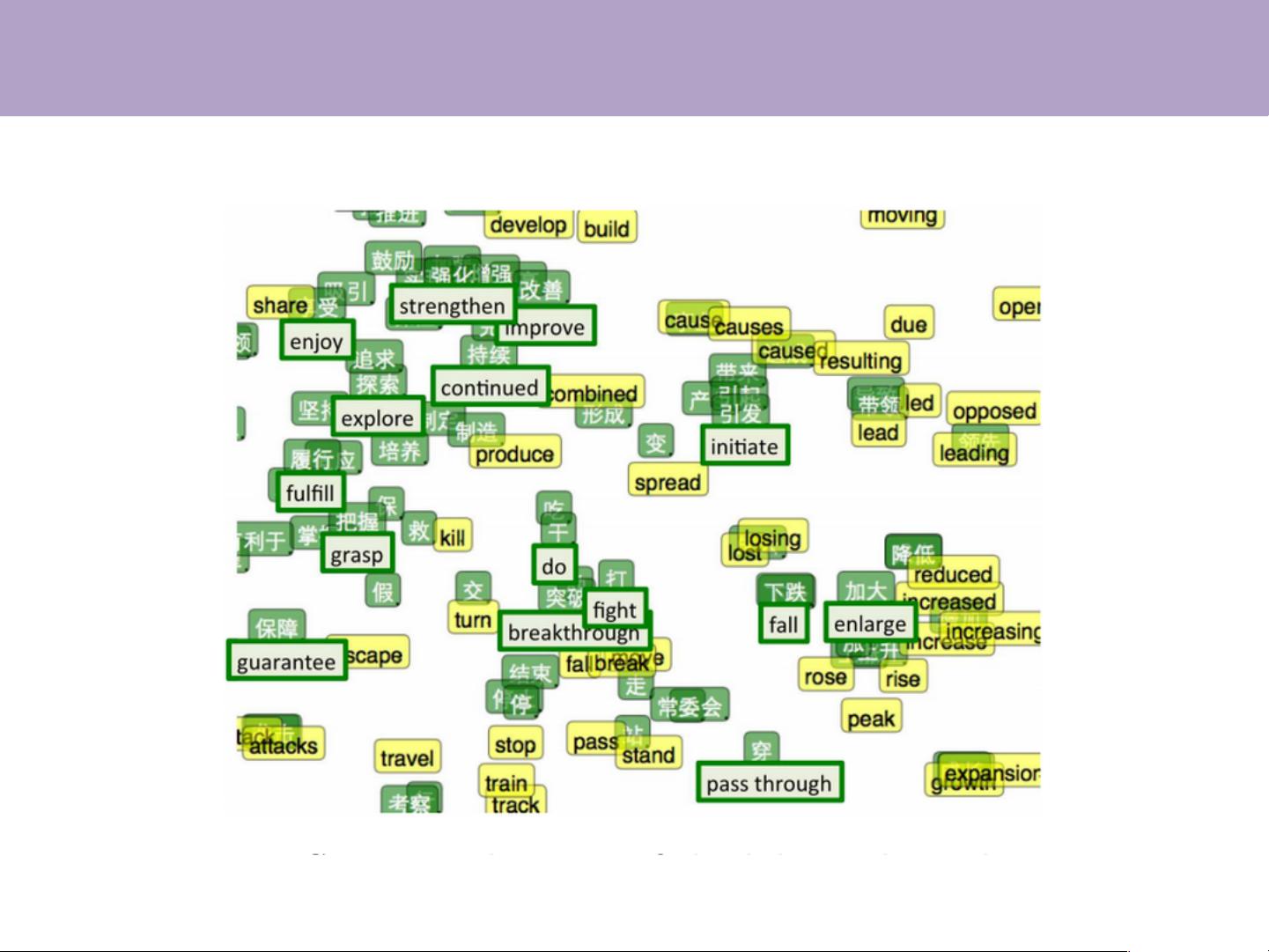
相比之下,分布式表示方案引入了神经网络技术,将每个对象(如词汇、实体或概念)映射为稠密、实值且低维度的向量。这种方法解决了数据稀疏问题,使得知识可以在更大的上下文中进行理解和迁移,为多任务学习提供了统一的底层表示,从而提升了模型的泛化能力和适应性。
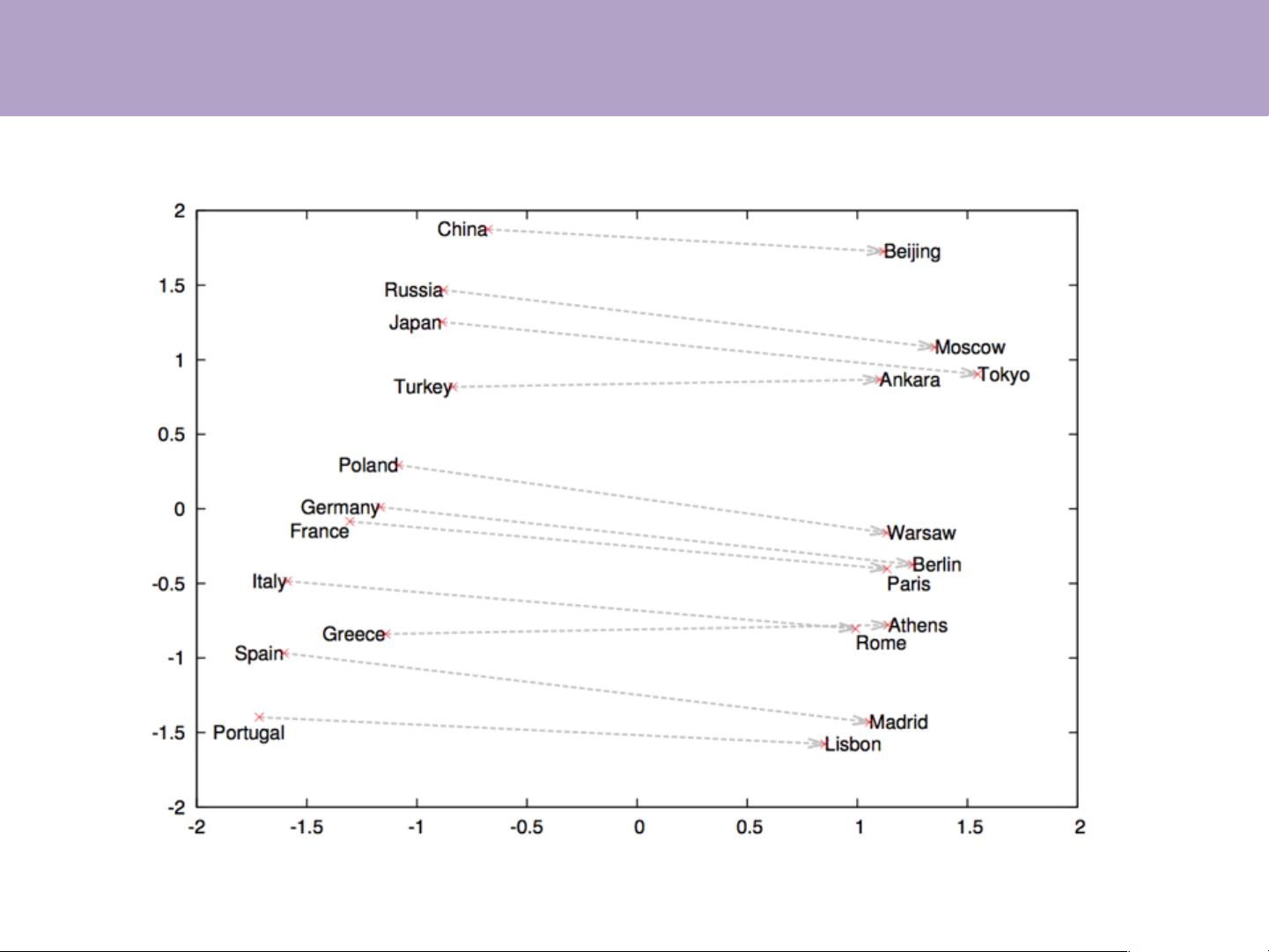
具体到表示学习,例如word2vec模型由Tomas Mikolov等人提出,通过预测上下文中的词来学习词汇的分布式表示。这种表示不仅能用于词汇相似度计算,揭示词汇间的隐含关系,比如"China"和"Beijing"与"Japan"和"Toke
2020-02-17 上传
2023-07-29 上传
2021-04-07 上传
2021-08-03 上传
2022-08-03 上传
2021-10-10 上传
2021-03-05 上传
2010-04-08 上传

dugujiujian1991
- 粉丝: 1
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索AVL树算法:以Faculdade Senac Porto Alegre实践为例
- 小学语文教学新工具:创新黑板设计解析
- Minecraft服务器管理新插件ServerForms发布
- MATLAB基因网络模型代码实现及开源分享
- 全方位技术项目源码合集:***报名系统
- Phalcon框架实战案例分析
- MATLAB与Python结合实现短期电力负荷预测的DAT300项目解析
- 市场营销教学专用查询装置设计方案
- 随身WiFi高通210 MS8909设备的Root引导文件破解攻略
- 实现服务器端级联:modella与leveldb适配器的应用
- Oracle Linux安装必备依赖包清单与步骤
- Shyer项目:寻找喜欢的聊天伙伴
- MEAN堆栈入门项目: postings-app
- 在线WPS办公功能全接触及应用示例
- 新型带储订盒订书机设计文档
- VB多媒体教学演示系统源代码及技术项目资源大全
