Spark入门与高效实践: RDD核心与使用模式详解
Spark使用总结与分享
在IT领域中,Spark是一种广泛应用于大数据处理的开源框架,特别受到数据科学和机器学习团队的青睐。本文主要针对初学者和项目组成员,总结了作者在使用Spark过程中积累的经验和关键知识点。
首先,Spark的核心组件是RDD(弹性分布式数据集),它是Spark架构的基础。RDD是一个不可变、分布式的数据结构,它封装了诸如map、filter、reduce等基本数据操作,提供了一种高效的数据共享抽象。与其他大数据处理框架如MapReduce、Pig、DryadLINQ和Hive相比,RDD的优势在于其数据共享的能力,使得它更适用于通用的数据处理任务。
在Spark的工作流程中,操作主要分为两类:转换(Transformation)和动作(Action)。转换是对数据进行操作但不立即产出结果,而是返回一个新的RDD,例如filter或map,这利用了懒加载的策略,即只在实际需要时才执行计算。动作则相反,它们直接产出结果,如count或collect,这些操作会触发真正的数据计算。
使用RDD时,推荐遵循一定的模式:首先加载外部数据并创建RDD,然后根据需求进行转换,如筛选或变换数据,接着对重要的数据进行缓存以提高性能,最后通过动作触发并行计算。这种模式有助于简化逻辑,避免在MapReduce中因过度优化导致代码复杂。
Spark的性能卓越,官方声称在某些特定场景下其计算效率可达Hadoop的20倍。这得益于RDD的高效设计,如数据的分区和并行计算能力,以及惰性执行策略。然而,实际效能的提升还取决于具体的应用场景、数据规模和硬件配置。
理解并熟练运用RDD是掌握Spark的关键。通过遵循正确的使用模式,结合Spark的高效特性,可以极大地提升大数据处理的效率和代码的可读性。对于团队协作来说,分享这样的经验能够帮助新成员更快地融入和成长。
Spark使用总结与分享使用总结与分享
背景
使用spark开发已有几个月。相比于python/hive,scala/spark学习门槛较高。尤其记得刚开时,举步维艰,进展十分缓慢。不
过谢天谢地,这段苦涩(bi)的日子过去了。忆苦思甜,为了避免项目组的其他同学走弯路,决定总结和梳理spark的使用经
验。
Spark基础
基石RDD
spark的核心是RDD(弹性分布式数据集),一种通用的数据抽象,封装了基础的数据操作,如map,filter,reduce等。RDD
提供数据共享的抽象,相比其他大数据处理框架,如MapReduce,Pegel,DryadLINQ和HIVE等均缺乏此特性,所以RDD更
为通用。
简要地概括RDD:RDD是一个不可修改的,分布的对象集合。每个RDD由多个分区组成,每个分区可以同时在集群中的不同
节点上计算。RDD可以包含Python,Java和Scala中的任意对象。
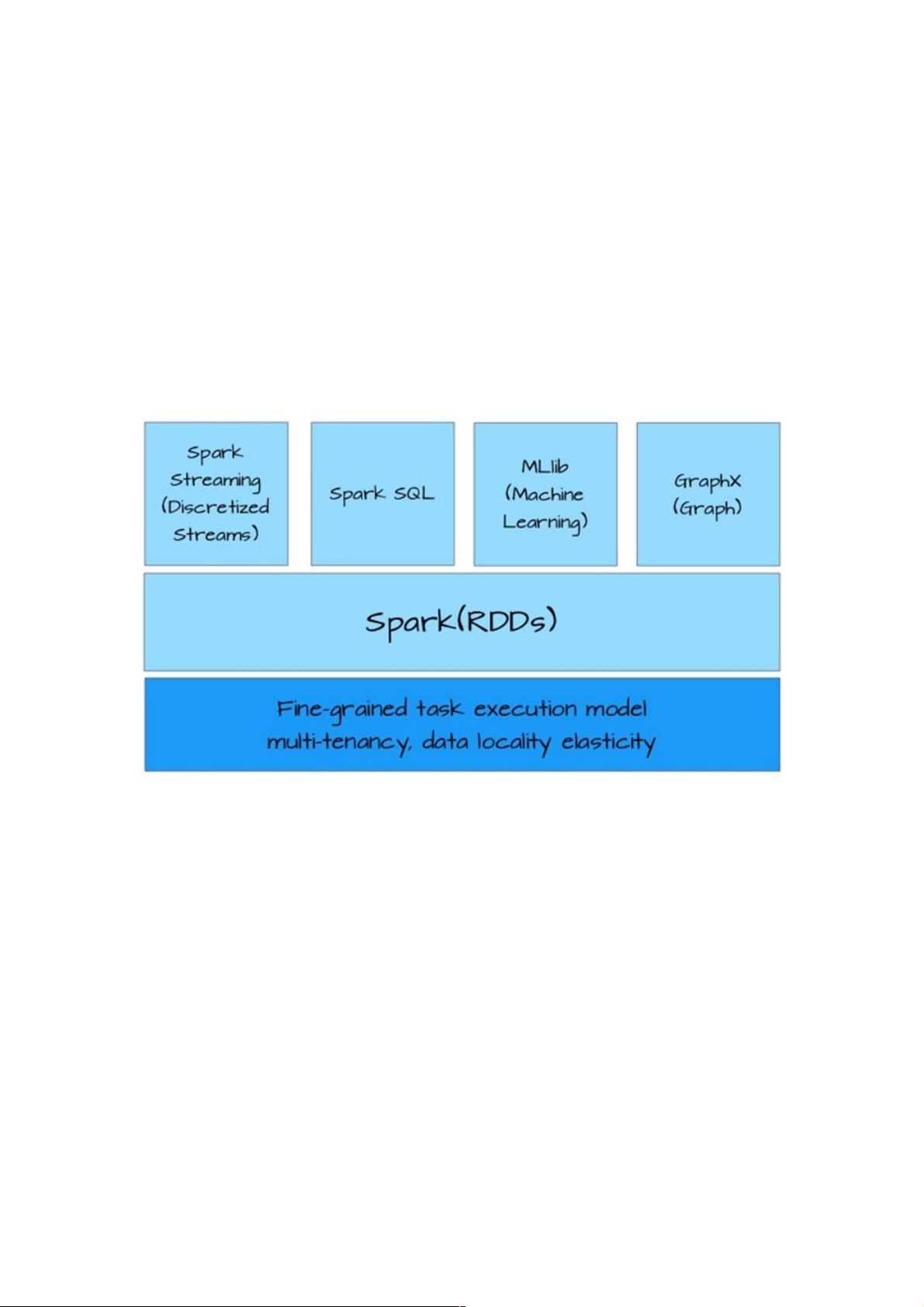
Spark生态圈中应用都是基于RDD构建(下图),这一点充分说明RDD的抽象足够通用,可以描述大多数应用场景。
RDD操作类型—转换和动作
RDD的操作主要分两类:转换(transformation)和动作(action)。两类函数的主要区别是,转换接受RDD并返回RDD,而
动作接受RDD但是返回非RDD。转换采用惰性调用机制,每个RDD记录父RDD转换的方法,这种调用链表称之为血缘
(lineage);而动作调用会直接计算。
采用惰性调用,通过血缘连接的RDD操作可以管道化(pipeline),管道化的操作可以直接在单节点完成,避免多次转换操作
之间数据同步的等待。
使用血缘串联的操作可以保持每次计算相对简单,而不用担心有过多的中间数据,因为这些血缘操作都管道化了,这样也保证
了逻辑的单一性,而不用像MapReduce那样,为了竟可能的减少map reduce过程,在单个map reduce中写入过多复杂的逻
辑。
RDD使用模式
RDD使用具有一般的模式,可以抽象为下面的几步
1.加载外部数据,创建RDD对象
2.使用转换(如filter),创建新的RDD对象
3.缓存需要重用的RDD
4.使用动作(如count),启动并行计算
RDD高效的策略
Spark官方提供的数据是RDD在某些场景下,计算效率是Hadoop的20X。这个数据是否有水分,我们先不追究,但是RDD效
下载后可阅读完整内容,剩余6页未读,立即下载
701 浏览量
2024-07-18 上传
2024-07-18 上传
2024-07-18 上传
2024-07-18 上传
371 浏览量
2024-07-18 上传

weixin_38739900
- 粉丝: 4
- 资源: 928
 我的内容管理
展开
我的内容管理
展开







