GMM-HMM语音识别原理详解:构建与应用
需积分: 0 123 浏览量
更新于2024-08-05
收藏 1.44MB PDF 举报
GMM-HMM语音识别原理1深入讲解了基于隐马尔可夫模型(Hidden Markov Model, HMM)和高斯混合模型(Gaussian Mixture Model, GMM)的语音识别技术。首先,让我们了解什么是HMM。HMM是一种概率模型,它假设系统状态随时间变化遵循马尔可夫过程,即当前状态只依赖于前一状态,而不考虑更早的状态。HMM在语音识别中的关键应用在于解决三个问题:
1. **Likelihood (似然性)**:通过计算观察序列(如语音信号)在给定HMM模型下的概率,来衡量该模型与实际语音数据的匹配程度。
2. **Decoding (解码)**:在接收到新的语音信号后,找出最有可能产生该序列的HMM状态序列,即声学模型的路径搜索问题。
3. **Training (训练)**:针对一组已知的语音样本,确定HMM的参数,包括初始状态概率、状态转移概率和输出概率。这通常通过 Expectation-Maximization (EM) 算法进行,目标是最大似然估计(Maximum Likelihood Estimation, MLE)。
接下来,GMM在语音识别中的作用是估计单个音素(phoneme)的概率分布。GMM将音素的声音特征表示为多个高斯分布的线性组合,每个高斯分布代表一种可能的特征值组合。通过GMM,我们可以计算出一个特定音素出现的概率,这在声学建模中至关重要。
GMM-HMM语音识别方法的结合主要体现在两个阶段:
3.1 **识别(Recognition)**:在新的语音输入上,首先用GMM对每个可能的音素建模,然后利用HMM的状态转移和输出概率找到最可能的音素序列,从而实现语音识别。
3.2 **训练(Training)**:
- **GMM参数训练**:针对每个音素,通过统计大量语音样本的特征向量,计算各高斯分量的均值、方差和混合系数,形成GMM模型。
- **HMM参数训练**:对于每个音素对应的HMM,确定初始状态概率、状态转移矩阵和输出概率,这需要根据语音样本中的状态序列和观测到的特征进行调整。
由于作者本身从事视觉领域而非语音处理,但在面临需求压力下研究了GMM-HMM,并参考了语音组老夏的资料,本文尝试用最简洁的方式解释了复杂的技术细节。尽管可能存在一定的误差,但文章提供了一个基础框架,适合初学者理解和应用。如果有任何错误,欢迎读者指正。
2016/12/14
有
道
云
笔
记
https://note.youdao.com/web/#/file/1DE562AEA3B64927BA2F6E58F868DBAA/note/CE4E97921C4C40D58F93F2107D87BFEC/ 3/11
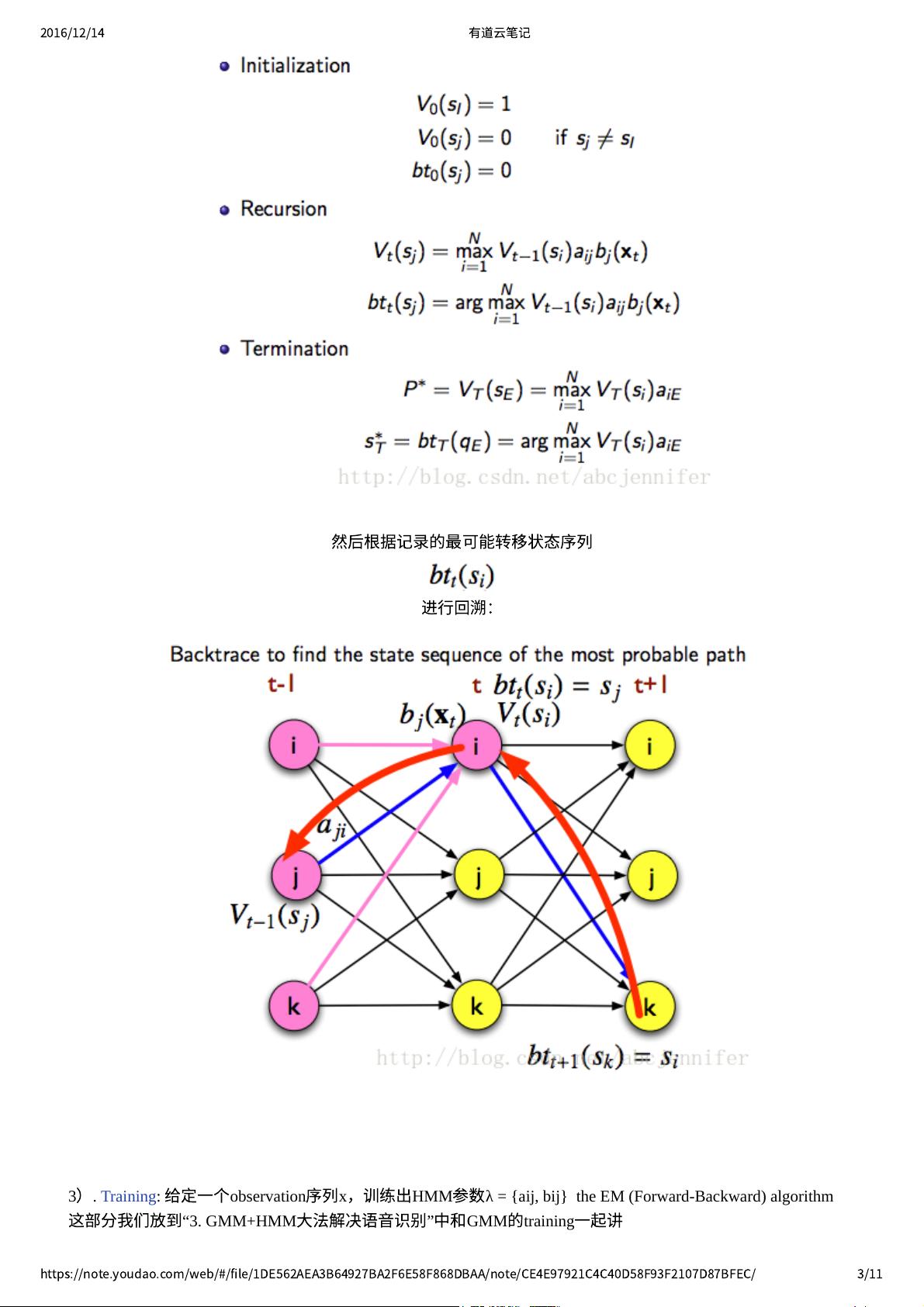
然
后
根
据
记
录
的
最
可
能
转
移
状
态
序
列
进
⾏
回
溯
:
3
)
. Training:
给
定
⼀个
observation
序
列
x
,
训
练
出
HMM
参
数
λ = {aij, bij} the EM (Forward-Backward) algorithm
这
部
分
我
们
放
到
“3. GMM+HMM
⼤
法
解
决
语
⾳
识
别
”
中
和
GMM
的
training
⼀
起
讲
剩余10页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-05-12 上传
2023-05-13 上传
2023-05-12 上传
2023-05-12 上传
2021-10-11 上传

蟹蛛
- 粉丝: 32
- 资源: 323
 我的内容管理
展开
我的内容管理
展开







最新资源
- Proxy-Table-SwiftUI:SwiftUI中的HTTPS代理列表
- ThinkMachine-Advisor:使用ThinkMachine规则的GUI
- java8stream源码-MS-Translator-Speech-HoL:MS-Translator-Speech-HoL
- LiteImgResizer-开源
- 易语言图片修改大小源码.zip易语言项目例子源码下载
- java8集合源码-bookmark:书签
- ARM开发工程师入门宝典.zip
- dgsim:SyncroSim基本软件包,用于模拟野生动物种群的人口统计数据
- TicTacToe
- Gordian Knot-开源
- react-hooks-booklist-tutorial
- 读取excel文件到高级表格.zip易语言项目例子源码下载
- TSC指令大全.rar
- java版商城源码-dev-cheat-sheet:只是一个快速工具和代码片段的汇编,以启动您的开发,主要是针对Web和API。贡献是开放的!
- BounceBall:使用SFML库用C ++编写的简单游戏
- RxSwift-main.zip
