GAIN:利用生成对抗网络进行缺失数据填充解析
需积分: 50 115 浏览量
更新于2024-07-15
收藏 1.53MB PPTX 举报
"GAIN论文解读PPT,介绍了一种使用生成对抗网络(GAN)进行缺失数据填充的方法,GAIN(Generative Adversarial Imputation Nets)。该资源涉及到自然语言处理(NLP)、深度学习和GAN技术,并引用了2018年ICML会议的相关工作。"
在数据科学领域,数据缺失是一个常见的问题,它可能由于各种原因如记录错误、设备故障或数据丢失等造成。处理缺失数据的方法有很多种,其中GAIN是一种基于生成对抗网络的新颖方法,由Jung-Su Yoon等人在2019年的ICML会议上提出。GAIN的目标是利用生成模型来填补缺失值,从而提高数据分析的准确性和完整性。
首先,我们需要了解数据缺失的类型。根据数据缺失的机制,可以分为三种类型:
1. MCAR(Missing Completely At Random):数据缺失完全随机,与任何已知的观测值无关。
2. MAR(Missing At Random):数据缺失虽不完全随机,但只依赖于可观察到的变量。
3. MNAR(Missing Not At Random):数据缺失依赖于未观察到的变量,这是最复杂的情况。
传统的缺失数据处理方法包括判别式方法,如MICE(Multiple Imputation by Chained Equations)和MissForest,以及矩阵完成等。这些方法通常基于已有的数据模式来估计缺失值,但它们可能无法捕捉到复杂的数据结构。
GAIN则引入了生成对抗网络(GANs)的概念,这是一种深度学习模型,由两部分组成:生成器和判别器。生成器负责生成假数据,而判别器的任务是区分真实数据和生成的数据。在GAIN中,生成器被用来生成缺失数据的估计值,而判别器试图区分这些估计值和真实数据。通过两者的对抗训练,生成器可以逐渐改进其生成缺失数据的能力,直到判别器无法区分真假。
具体流程如下:
1. 首先,生成器尝试填充缺失值。
2. 然后,判别器对填充后的数据进行评估,试图找出真实值和估计值的区别。
3. 通过反向传播,生成器根据判别器的反馈更新其参数,以更好地模仿真实数据的分布。
4. 这个过程持续进行,直到生成器生成的缺失值足够逼真,使得判别器难以区分。
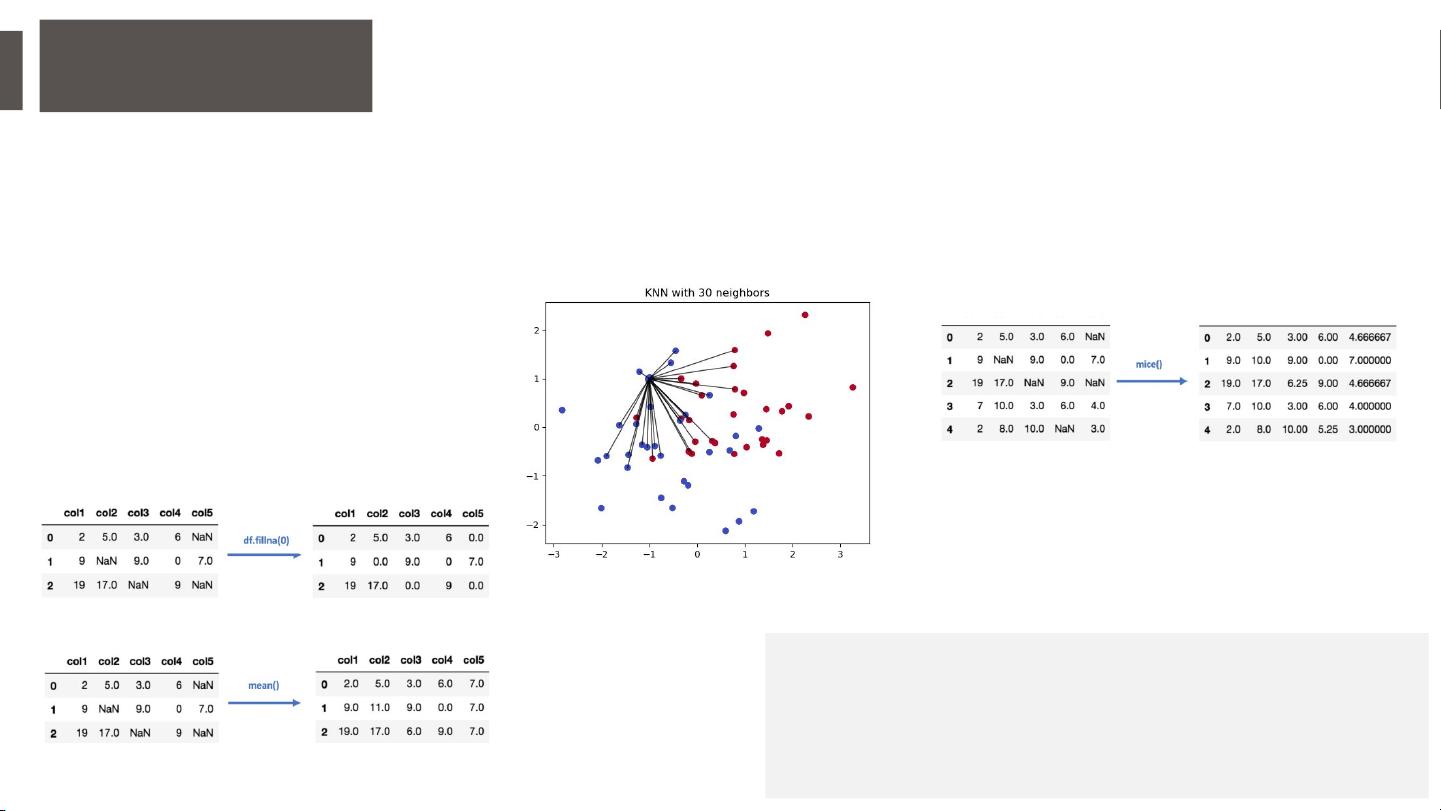
除了GAIN,还有其他数据填充技术,如基于统计值(均值、中位数、众数)的简单插补、K-最近邻(K-NN)方法、多重插补(MICE)等。MICE是一种迭代方法,通过多次估计和替换缺失值来考虑不确定性。此外,还有一些其他技术,如随机回归插补、外推和内插、热卡牌插补,以及使用自动编码器(如VAE、DAE)进行数据重建。
GAIN的优势在于它能够捕捉数据的非线性关系和复杂结构,特别是对于高维和非结构化数据,如图像、文本或序列数据。然而,它也面临一些挑战,比如训练的稳定性、对大规模数据的处理效率,以及对MNAR情况的处理能力。
GAIN提供了一个创新的解决方案,利用深度学习的力量来处理缺失数据,这对于NLP和各种领域的数据科学任务具有重要的实际应用价值。
点击添加相关标题文字
缺失数据的估值
!!"#$%#&'())*+)',-
.)/)'0)&1)''$)&23)
4+%553)))$$$*5673)-$*+)1*8()&
))*+)'39)*+&6 :$) ;;:
),%4+%55*+-)$55*)59*&
<8
只需让算法去处理缺失的数据,例如在
= 、 8# 中可以使用训练
损失的减少来学习缺失数据的最佳输入
值
>8)''$)&)&
基于统计信息的估值方法,使用均值、
中位数、众数等数值代替缺失的部分。
>8<<
使用特征相似性来预测任何缺
失部分的数据点的值
#.
通过多次估计缺失的数据来实现,它能更
好地度量缺失值的不确定性
•
$)'$8*+)'
•
9)+&)')+&)'
•
?$@*+)'
剩余22页未读,继续阅读
2021-01-01 上传
2018-11-28 上传
2019-08-16 上传
2008-04-21 上传
2021-06-02 上传
2022-07-15 上传
2021-05-10 上传
2021-02-10 上传

Forlogen
- 粉丝: 382
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- radio-pomarancza:Szablon PHP,HTMLCSS pod广播互联网
- mini-project-loans:Lighthouse Labs迷你项目,用于创建简单的贷款资格API
- 行业分类-设备装置-可远程控制的媒体分配装置.zip
- 密码战
- Python库 | OT1D-0.3.5-cp39-cp39-win_amd64.whl
- Reactivities
- VB仿RealonePlayer播放器的窗体界面
- symfony_issuer_40452
- healthchecker
- 行业分类-设备装置-可编程多媒体控制器的编程环境和元数据管理.zip
- dosmouse:只是为了好玩:是我在汇编程序I386中编写的一个程序,用于在MsDOS控制台上使用鼠标(在Linux上,类似的程序称为gpm)
- Python库 | os_client_config-1.22.0-py2.py3-none-any.whl
- HERBv1
- BuzzSQL-开源
- show-match:一个允许用户从特定频道搜索电视节目并保存该列表以供将来参考的应用
- ETL-Project:该项目将利用ETL流程
