深度学习驱动的高效立体匹配方法
需积分: 9 19 浏览量
更新于2024-09-07
收藏 3.61MB PDF 举报
"这篇论文提出了一种利用深度学习框架解决立体匹配问题的方法,重点关注典型立体匹配方法的第一阶段——匹配成本计算和最后一阶段——视差精炼。通过深度局部和上下文信息来提高匹配效率和准确性,尤其针对弱纹理、边缘不连续、光照差异和遮挡等问题。文章详细介绍了两个基于补丁的网络设计,用于计算匹配成本,并采用一种深度自适应上下文聚合模块进行视差修复。此外,论文还讨论了训练策略和实验结果,证明了该方法在多个数据集上的优越性能。"
本文探讨的是立体视觉匹配中的关键问题,即如何有效地利用深度的局部信息和上下文信息来提升匹配效率和精度。立体匹配是计算机视觉领域的重要研究课题,它涉及到两个不同视角的图像(左右视图)之间的对应像素寻找,以重建三维空间信息。在实际应用中,如自动驾驶、机器人导航等,立体匹配的准确性和速度都至关重要。
作者提出的深度学习框架旨在克服常见的挑战,如弱纹理区域的匹配困难、图像边缘的不连续性、光照条件变化导致的匹配干扰以及遮挡物体的处理。在匹配成本计算阶段,他们设计了两个基于补丁的网络,这些网络可以捕捉到局部特征并进行比较,从而估算出像素间的相似度,即匹配成本。这种局部信息的处理有助于提高匹配的鲁棒性。
同时,考虑到上下文信息对提升匹配精度的作用,论文引入了一种深度自适应上下文聚合模块。这个模块能够整合更广泛的上下文信息,帮助识别和修复可能的错误匹配,尤其是在处理遮挡和光照差异时显得尤为重要。通过这样的视差精炼步骤,可以进一步优化初始匹配结果,提高最终的立体匹配质量。
论文还提到了其研究得到的国家自然科学基金的支持,并给出了相应的训练策略和实验结果分析。实验部分对比了提出的算法与其他经典和现代方法在多个标准数据集上的表现,证明了该方法在减少错误匹配和提高匹配精度方面的优势。
这篇论文为立体匹配问题提供了一个创新的深度学习解决方案,强调了深度局部和上下文信息的结合在提高匹配质量和效率上的潜力。这不仅有助于推动立体视觉领域的理论研究,也为实际应用中的立体匹配算法优化提供了新的思路。
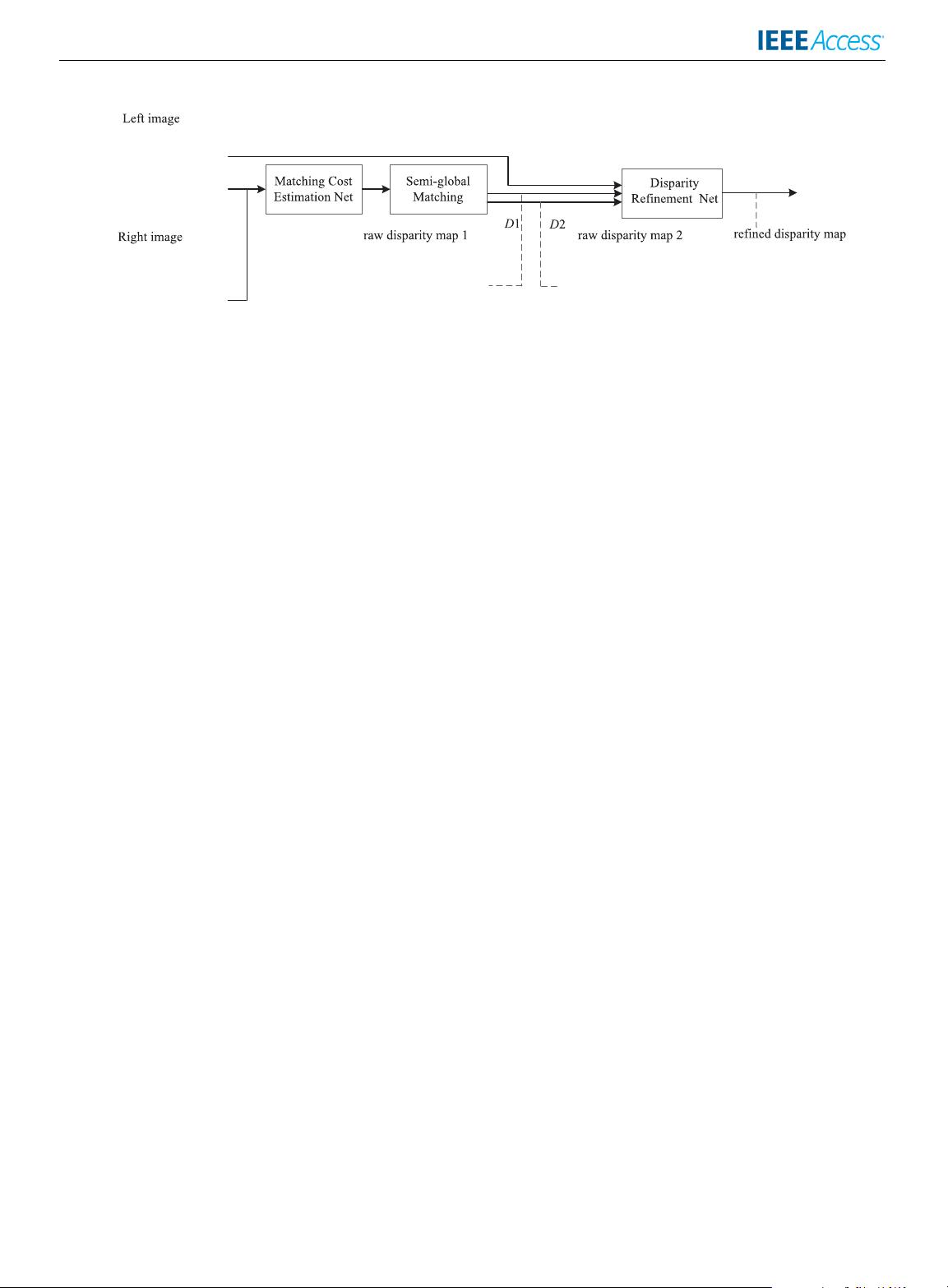
X. Ye et al.: Efficient Stereo Matching Leveraging Deep Local and Context Information
FIGURE 1. Overview of the proposed approach. The framework consists of two key parts: (1) matching cost estimation net and (2) disparity
refinement net. D
1
and D
2
denote the raw disparity maps related to the minimum and second minimum aggregated cost.
B. DISPARIT Y REFINEMENT
Despite of the previous steps, the raw disparity map gained
directly by WTA still contains many outliers, especially
in occlusions, textureless regions and disparity disconti-
nuities. To achieve higher accuracy, various refinement
approaches are harnessed to identify and correct outliers.
Left-right consistency check [1] is widely undertaken to
detect outliers. Weighted median filtering [24] based on
guided image [25] and bilateral weights [26] are employed
to refine aggregated results. Segmentation-based and plane
fitting [15], [27] methods handle weakly-textured regions
well but are time-consuming and subject to the quality of
segmentation. Instead of treating outliers uniformly, multi-
step processing [13], [28]–[30] achieves more competitive
results. Hirschmuller [15] distinguished occlusions from
mismatches by epipolar line, nevertheless, it will fail in
large mismatched area with weak texture, where a pixel
can still be marked as correct even if it has wrong dis-
parities on both maps. Besides, it produces threadlike out-
liers due to its discrete characteristic. Neighboring nearest
and minimal valid disparity were assigned to mismatched
and occluded points respectively based on support region
voting [11] or scanline interpolation [31]. Zhan et al. [13]
performed four-direction propagation to correct inner outliers
and took account of the variation of circumjacent dispar-
ities when handling the leftmost outliers. Concerning the
occlusions, Huq et al. [32] studied the theories and experi-
ments of occlusion filling. Yamaguchi et al. [33] proposed a
slanted plane model for jointly recovering an image segmen-
tation, a dense depth estimate as well as occlusion boundary.
Very recently, Gidaris et al. [10] introduced a deep structured
model to decompose the task into three sub-blocks. It took
advantage of deep CNNs to identify and correct outliers with
the information of left color image and left initial disparity
map.
In contrast to previous works that employ various refine-
ment algorithms singly to the initial disparity map obtained
by WTA, we also take advantage of the sub-optimal disparity
map corresponding to the second minimum cost, since it
contains favorable information that is not reflected in the
WTA-oriented disparity map. Inspired by [10], rather than
constructing a black box architecture, we decompose the
problem into a sequence of subtasks under the guidance of
our understanding.
III. MATCHING COST COMPUTATION ARCHITECTURE
The proposed approach mainly focuses on the matching cost
computation and the disparity refinement step. We achieve
this by two independent networks rather than a blind end-
to-end network because we believe that the typical pipeline
of solving stereo problems can explicitly guide the process.
An overview of our approach is illustrated in Fig. 1. The
output of the first network is used to initialize the matching
cost and is then aggregated by semi-global matching. Next the
disparity labels associated with two smallest costs are chosen
and employed in the follow-up refinement network.
The baseline work [3] adopts a Siamese network to com-
pute the similarity by simple dot product or fully-connected
layers, corresponding to the fast and accurate networks. The
two sub-networks each takes in a small patch extracted
from left and right images and outputs two feature vec-
tors by passing through several convolutional layers with
shared weights. An overview of baseline Siamese network is
depicted in Fig. 2(a). Note that the patch size in [3] is con-
strained to 11 × 11 with the exclusion of pooling unit. This is
because the conventional strided pooling reduces resolution
and could cause the loss of fine details, which is unsuitable
for dense correspondence estimation. As a result, the baseline
work [3] merely learns relatively local knowledge. To enlarge
the receptive field without losing resolution, a pyramid pool-
ing module is appended to the end of the fully connected
layers in [16] to learn multi-scale information (see Fig. 2(b)).
To obtain the similarity score, the pooling module in [16]
as well as the fully-connected modules have to be recom-
puted for each possible disparity, causing D
max
times’ extra
computation, where D
max
is the maximum disparity level.
The training procedure takes as long as several weeks and
the testing process is more than four times slower compared
to [3].
In contrast, we introduce a multi-size and multi-layer pool-
ing module with stride equals to one and append this module
before the fully-connected layers, which only needs to be
VOLUME 5, 2017 18747
剩余10页未读,继续阅读
4512 浏览量
753 浏览量
4521 浏览量
314 浏览量
1452 浏览量
2010-06-20 上传

皮皮君
- 粉丝: 287
- 资源: 23
 我的内容管理
展开
我的内容管理
展开







最新资源
- playn-swt-java-1.8.zip
- smartdove:SMARTDOVE PHPLaravel SDK
- 易语言外形框模仿进度条
- 功能强大的万年历源码 v1.0
- Craftassist:Minecraft中的虚拟助手机器人
- RYUTO:龙人
- My-Personal-Pertfolio-Project
- Disk2vhd安装包
- 7yuvrj.rar
- uploadfiles-maven-plugin-1.0.1.zip
- HDP-GPL-3.1.4.0-centos7-gpl.tar.gz
- 222个科技、数字产品相关图标 .fig素材下载
- aws-k8s-provision:轻松地在AWS上部署kubernetes
- microbium-app:吸引新世界
- 直流电机原理动画.zip
- ApkToolkit.zip
