Python爬虫学习:XPath解析HTML实战——好段子爬取
需积分: 13 201 浏览量
更新于2024-08-30
收藏 1.27MB PDF 举报
"学习爬虫,理解XPath,以及在HTML中解析数据的方法,通过实例操作讲解XPath的常用路径表达式,并介绍如何在浏览器中安装XPath插件进行辅助定位。"
XPath,全称为XML Path Language,是一种在XML(以及HTML)文档中查找信息的语言。虽然XML主要用来传输和存储数据,具有自定义标签的特性,但HTML同样可以视作一种XML的变体,用于网页内容的展示。XPath被设计用来方便地选取XML或HTML文档中的节点,如元素、属性等。通过XPath,我们可以高效地定位到我们需要的数据。
XPath的路径表达式是其核心部分,下面列举了一些常见的表达式及其含义:
1. `/`: 选取根节点。
2. `//`: 不考虑位置的查找,选取文档中匹配表达式的任何节点。
3. `./`: 从当前节点开始往下查找。
4. `..`: 从当前节点的父节点开始查找。
5. `@`: 选取属性。
这些表达式可以结合其他条件,如索引、函数等,来精确定位我们需要的节点。例如:
- `/bookstore/book`: 选取根节点`bookstore`下的所有直接子节点`book`。
- `//book`: 选取文档中任意位置的`book`节点。
- `bookstore//book`: 选取`bookstore`下面所有的`book`节点,不论它们是否是直接子节点。
- `//@lang`: 选取所有名为`lang`的属性的标签。
- `/bookstore/book[1]`: 选取属于`bookstore`子元素的第一个`book`元素。
- `/bookstore/book[last()]`: 选取`bookstore`下的最后一个`book`元素。
- `/bookstore/book[last()-1]`: 选取`bookstore`下的倒数第二个`book`元素。
- `/bookstore/book[position()<3]`: 选取`bookstore`下的前两个`book`元素。
- `//title[@lang]`: 选取所有拥有名为`lang`的属性的`title`元素。
- `//title[@lang='eng']`: 选取所有`lang`属性值为`eng`的`title`元素。
- `/bookstore/book[price>35.00]`: 选取`bookstore`下的所有`price`属性值大于35.00的`book`元素。
- `/bookstore/book[price>35.00]//title`: 选取`price`属性值大于35.00的`book`下的所有`title`元素。
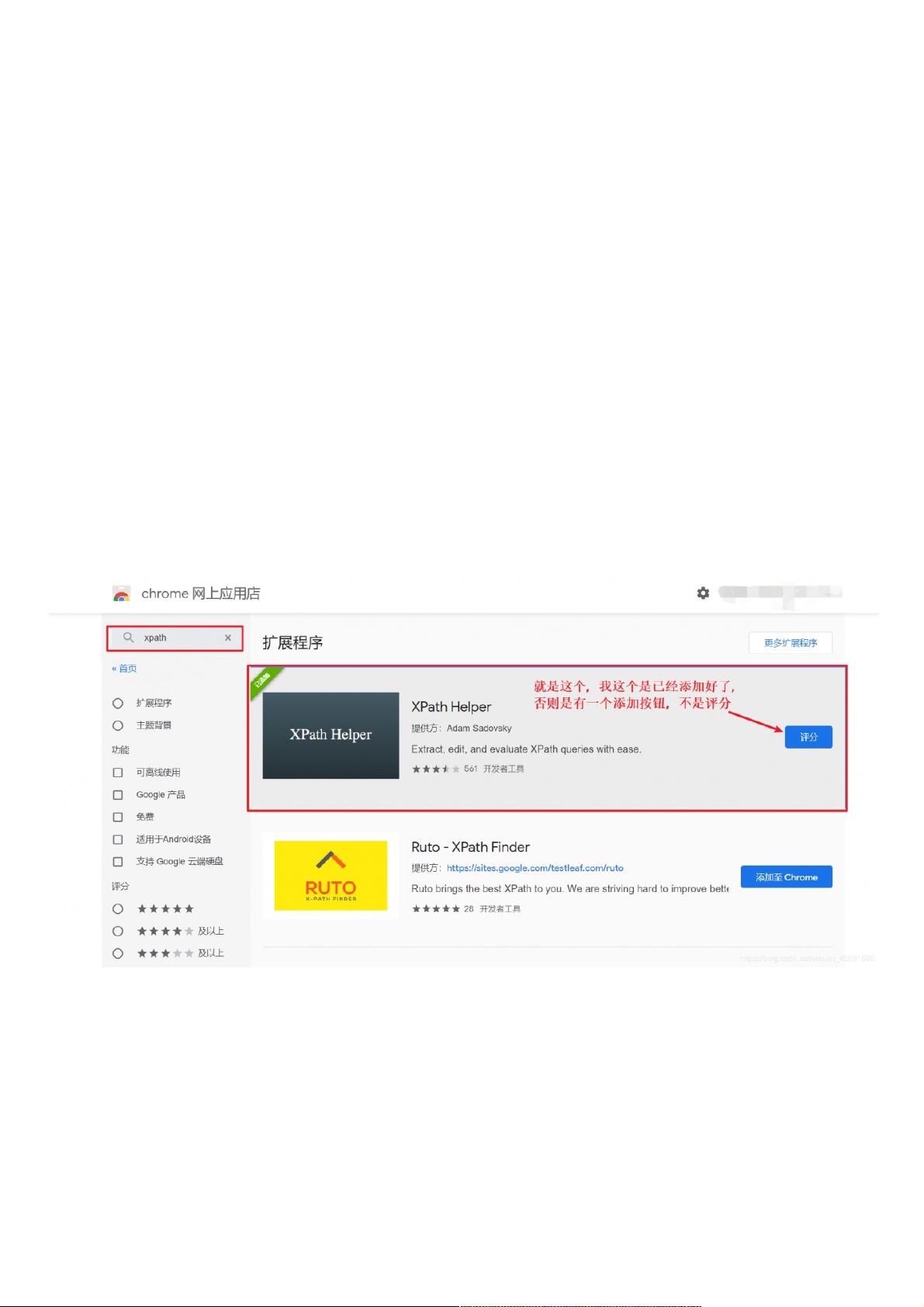
在学习和实践XPath时,使用浏览器插件可以帮助我们直观地查看选取的节点。例如,在谷歌浏览器中,可以安装XPath插件(如XPath Helper),通过输入路径表达式实时查看匹配的结果。在安装后,通常可以通过快捷键(如Ctrl+Shift+X)快速启动和关闭插件。在实际操作中,可以在像www.baidu.com这样的网页上尝试定位不同元素,以此来加深对XPath的理解和应用。
在爬虫实践中,XPath常用于提取网页数据,配合Python的库如BeautifulSoup或lxml,可以高效地解析和抽取所需信息。掌握XPath能够显著提高爬虫的编写效率,使数据抓取更为精准和便捷。通过每天30分钟的学习,逐步理解和熟练运用XPath,将对爬虫技术的掌握大有裨益。
每天每天30分钟分钟 一起来学习爬虫一起来学习爬虫——day10(解析数据(解析数据 之之 xpath,实例:好段子爬取),实例:好段子爬取)
文章目录文章目录xpath 解析网页什么是xpath ?常用的路径表达式:实例:安装xpath插件到浏览器。看代码中的使用:爬取好段子
xpath 解析网页解析网页
什么是什么是xpath ??
xml: 可扩展标记语言,用来传输和存储数据。他的标签没有预定义,要自己定义标签。 与html的区别: html是用来显示数据的,html的标签是固定的
xpath: 是一门在xml 文档中查找信息的语言,这里,我们可以用xpath来查找html文档,它是一种路径表达式
常用的路径表达式:常用的路径表达式:
表达式表达式 含义含义
// 不考考虑位置的查找
./ 从当前节点开始往下查找
. . 从当前节点的父节点往下找
@ 选取属性
实例:实例:
表达式表达式 含义含义
/bookstore/book 选取根节点 bookstore 下的所有 直接子节点 book
//book 选取任意位置的 book 节点
bookstore//book
选取 bookstore 下面所有的book 节点,不管是不是直接子节
点。
//@lang 选取所有名为 lang 的属性的标签
/bookstore/book[1] 选取属于 bookstore 子元素的第一个 book 元素。
/bookstore/book[last()] 选取 bookstore 下的最后一个 book 元素。
/bookstore/book[last()-1] 选取
/bookstore/book[position()< 3] 选取bookstore下的最前面的两个book 元素。
//title[@lang] 选取所有拥有名为 lang 的属性的 title 元素。
//title[@lang=‘eng’] 选取所有 lang 属性值为 eng 的 title 元素
/bookstore/book[price>35.00] 选取 bookstore 下的所有 price属性值大于 35.00的 book
/bookstore/book[price>35.00]//title
选取 bookstore 下的所有 price属性值大于 35.00的 book 下的
title
安装安装xpath插件到浏览器。插件到浏览器。
安装成功后,启动和关闭。ctrl+shift+x
左边是路径表达式,右边是结果,如果路径写对了的话就会显示。
下载后可阅读完整内容,剩余4页未读,立即下载
135 浏览量
254 浏览量
2021-06-06 上传
2021-06-06 上传
356 浏览量
149 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38731979
- 粉丝: 5
- 资源: 897
 我的内容管理
展开
我的内容管理
展开







最新资源
- i茅台app自动预约,每日自动预约
- MYSQL5.6版本安装包
- 易语言-hook实现某些特殊控件显示Unicode
- Sunsets HD Wallpapers Sunrise New Tab Theme-crx插件
- Flask实战视频教程下载2022
- django-oauth-toolkit:Djangonauts的OAuth2好东西!
- CNN-chest-x-ray-abnormalities-localization:使用CNN,转移学习和归因方法来定位X射线胸部图像上的异常
- ranikola.github.io:Github页面
- sumaVectores-MulpiplicacionComplejos
- 通用数据库操作工具UDAT
- Coursera-Princeton-assignments-1:仅供参考和提示。 请不要复制我所有的作品
- 51单片机 用74HC245读入数据(51/96/88/ARM)
- 关于车辆控制设备,车辆控制方法和车辆控制程序的介绍说明.rar
- Kendo UI在列表视图之间的拖放
- firefoxtaskmonitor:显示CPU和内存条,每个选项卡和所有任务。 Firefox用户Chrome脚本
- poynt-node:Poynt Node.js SDK
