

238 Introduction
We call those ranking methods that have the following two properties
learning-to-rank methods.
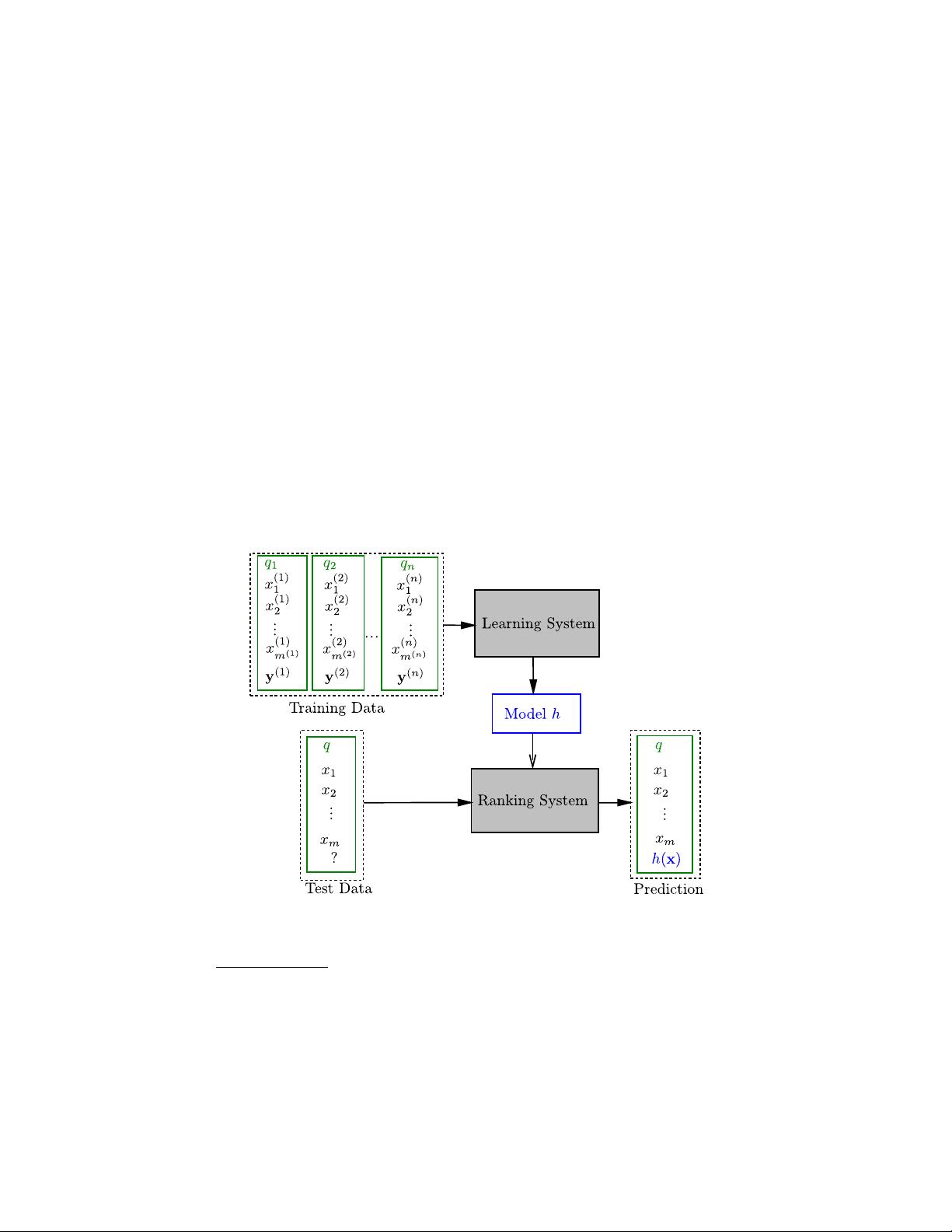
Feature based: All the documents under investigation are represented
by feature vectors,
12
reflecting the relevance of the documents to the
query. That is, for a given query q, its associated document d can be
represented by a vector x =Φ(d,q), where Φ is a feature extractor.
Typical features used in learning to rank include the frequencies of the
query terms in the document, the BM25 and PageRank scores, and the
relationship between this document and other documents. If one wants
to know more about widely used features, please refer to Tables 6.2
and 6.3 in Section 6.
Even if a feature is the output of an existing retrieval model, in
the context of learning to rank, one assumes that the parameter in the
model is fixed, and only the optimal way of combining these features is
learned. In this sense, the previous work on automatically tuning the
parameters of existing models [60, 120] is not categorized as “learning-
to-rank” methods.
The capability of combining a large number of features is a very
important advantage of learning to rank. It is easy to incorporate any
new progress on the retrieval model by including the output of the
model as one dimension of the features. Such a capability is highly
demanding for real search engines, since it is almost impossible to use
only a few factors to satisfy complex information needs of Web users.
Discriminative training: The learning process can be well described
by the four components of discriminative learning as mentioned in the
previous subsection. That is, a learning-to-rank method has its specific
input space, output space, hypothesis space, and loss function.
In ML literature, discriminative methods have been widely used to
combine different kinds of features, without the necessity of defining a
probabilistic framework to represent the objects and the correctness of
prediction. In this sense, previous works that train generative ranking
12
Note that, hereafter in this tutorial, when we refer to a document, we will not use d any
longer. Instead, we will directly use its feature representation x. Furthermore, since our
discussions will focus more on the learning process, we will always assume the features
are pre-specified, and will not purposely discuss how to extract them.



剩余108页未读,继续阅读

suiyuan4325
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


