网络爬虫入门指南:自己动手轻松抓取数据
需积分: 9 88 浏览量
更新于2024-07-20
收藏 2.47MB PDF 举报
网络爬虫教程深入剖析了如何自己动手编写网络爬虫,特别是对于初次接触者来说,提供了全面的入门指南。首先,章节1介绍了网络爬虫的基本原理,通过搜索引擎巨头如百度、Google的运作机制,让读者明白为何即使这些大公司已经处理大部分信息,个人或企业依然需要自己编写爬虫,因为定制化的信息整合需求广泛存在。在网络爬虫的核心操作——抓取网页方面,该章节详细讲解了如何从URL入手,理解URL的本质,它是一种通用资源标识符(URI),由访问机制、主机名和资源名称三部分构成。
在实际操作中,抓取网页的过程涉及客户端与服务器端通信,用户通过浏览器发送HTTP请求,获取服务器上的文件。教程提供了一个用Java编写的抓取网页示例,让学习者能够实践基本的网络爬虫技术。同时,处理HTTP状态码也是关键环节,因为不同的状态码反映了请求的响应结果,比如200表示成功,404表示未找到等。
深入理解URL的重要性在于,它不仅包括协议(如http或https)、域名和路径,还包括查询参数,这些都是爬虫解析和抓取网页时需要关注的元素。通过查看源代码,不仅可以了解网页结构,还能学习如何构造和解析URL以实现更精准的数据抓取。
网络爬虫教程旨在帮助读者掌握基础技能,从概念理解到实战应用,让每个人都能具备抓取互联网上所需信息的能力,无论是用于数据分析、商业智能还是个人兴趣爱好。随着教程的逐步深入,读者不仅能学会如何编写简单的爬虫,还能应对更复杂的抓取策略和数据处理挑战。
12
1
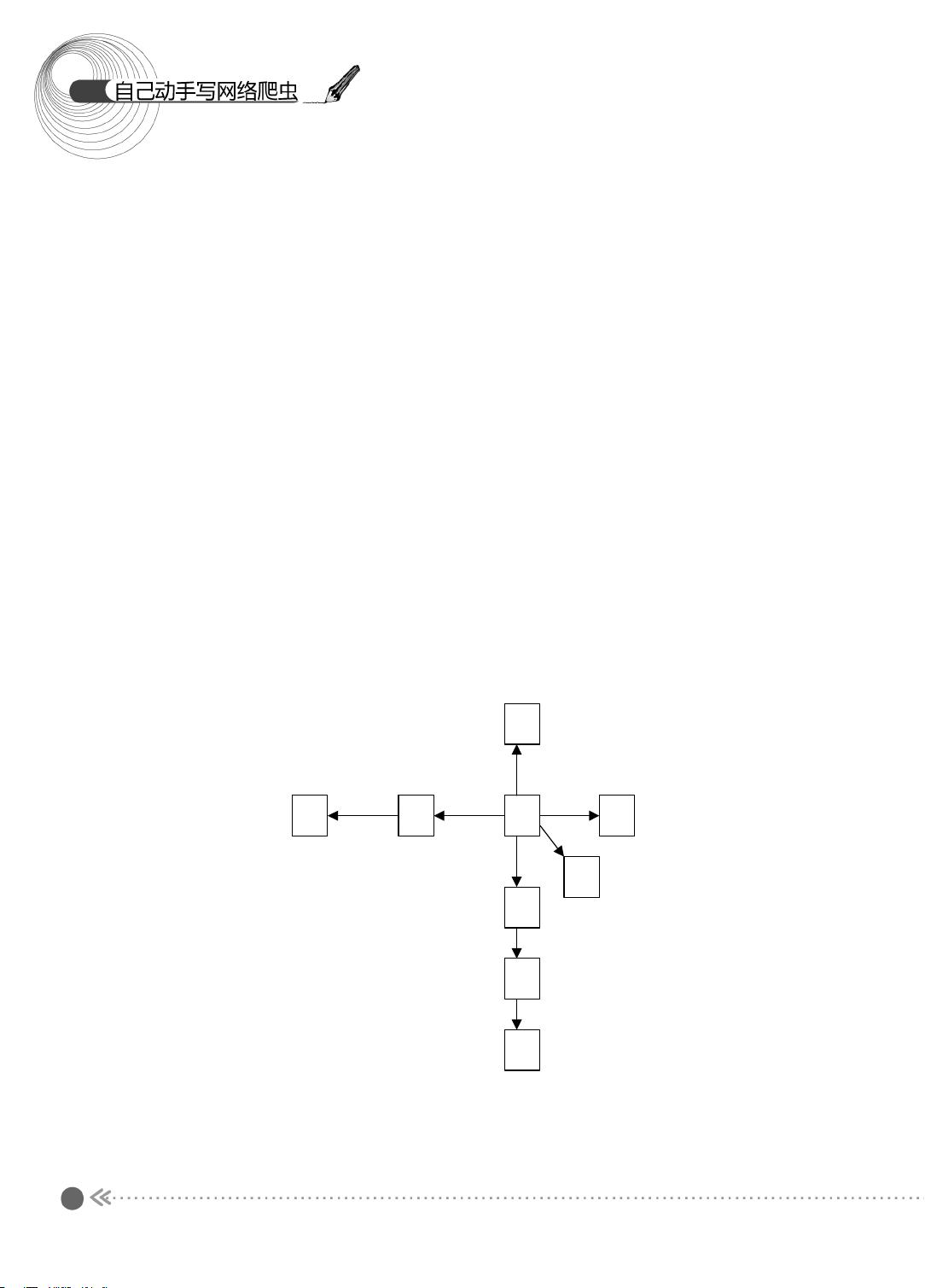
的遍历的方式对互联网这个超级大 “ 图 ” 进行访问。图的遍历通常可分为宽度优先遍历和
深度优先遍历两种方式。但是深度优先遍历可能会在深度上过 “ 深 ” 地遍历或者陷入 “ 黑
洞 ” ,大多数爬虫都不采用这种方式。另一方面,在爬取的时候,有时候也不能完全按照
宽度优先遍历的方式 , 而是给待遍历的网页赋予一定的优先级 , 根据这个优先级进行遍历
,
这种方法称为带偏好的遍历。本小节会分别介绍宽度优先遍历和带偏好的遍历。
1.2.1 图的宽度优先遍历
下面先来看看图的宽度优先遍历过程 。 图的宽度优先遍历 (BFS) 算法是一个分层搜索的
过程,和树的层序遍历算法相同。在图中选中一个节点,作为起始节点,然后按照层次遍
历的方式,一层一层地进行访问。
图的宽度优先遍历需要一个队列作为保存当前节点的子节点的数据结构。具体的算法
如下所示:
(1) 顶点 V 入队列。
(2) 当队列非空时继续执行,否则算法为空。
(3) 出队列,获得队头节点 V ,访问顶点 V 并标记 V 已经被访问。
(4) 查找顶点 V 的第一个邻接顶点 col 。
(5) 若 V 的邻接顶点 col 未被访问过,则 col 进队列。
(6) 继续查找 V 的其他邻接顶点 col ,转到步骤 (5) ,若 V 的所有邻接顶点都已经被访
问过,则转到步骤 (2) 。
下面,我们以图示的方式介绍宽度优先遍历的过程,如图 1.3 所示。
G
B
A
C
D
F
E
I
H
图 1.3 宽度优先遍历过程

剩余67页未读,继续阅读
2024-06-29 上传
2021-11-21 上传
2022-06-18 上传
2017-12-05 上传
2023-04-25 上传
2019-02-13 上传
2021-08-06 上传
点击了解资源详情

jackson-up
- 粉丝: 46
- 资源: 33
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
