Spark SQL与Hive性能比较:智能电网应用与MapReduce、Spark 1.6、2.0深度解析
需积分: 10 75 浏览量
更新于2024-07-17
收藏 3.28MB PDF 举报
在2016年的Hadoop Summit上,Yusuke Furuyama 和 Yang Xie 发表了一篇名为《Spark SQL与Hive的比较》的演讲,该研究主要聚焦于云计算背景下智能电表数据的应用和性能评估。他们以电力公用事业为例,探讨了两个关键的技术栈:MapReduce和Spark 1.6,以及更进一步的Spark 2.0版本。
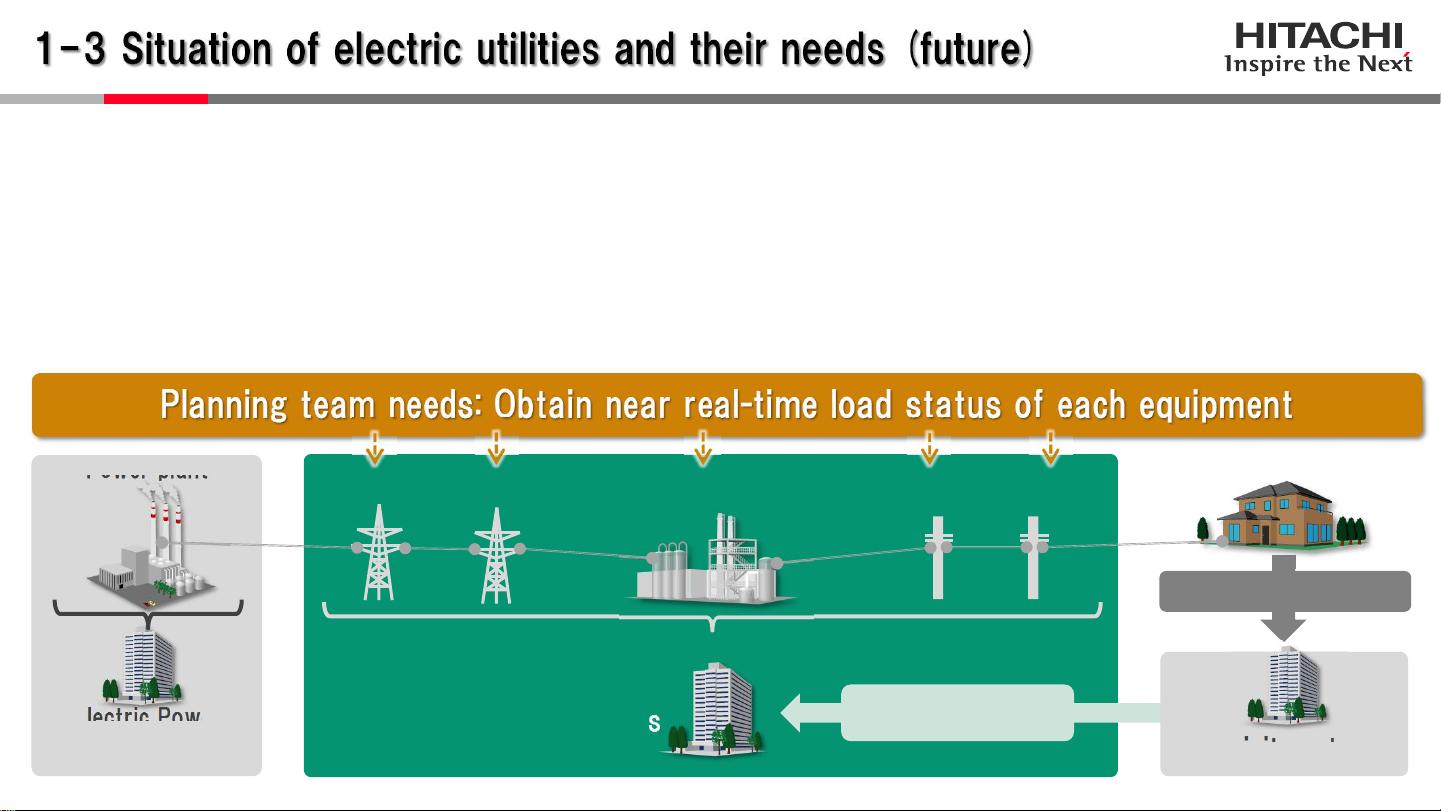
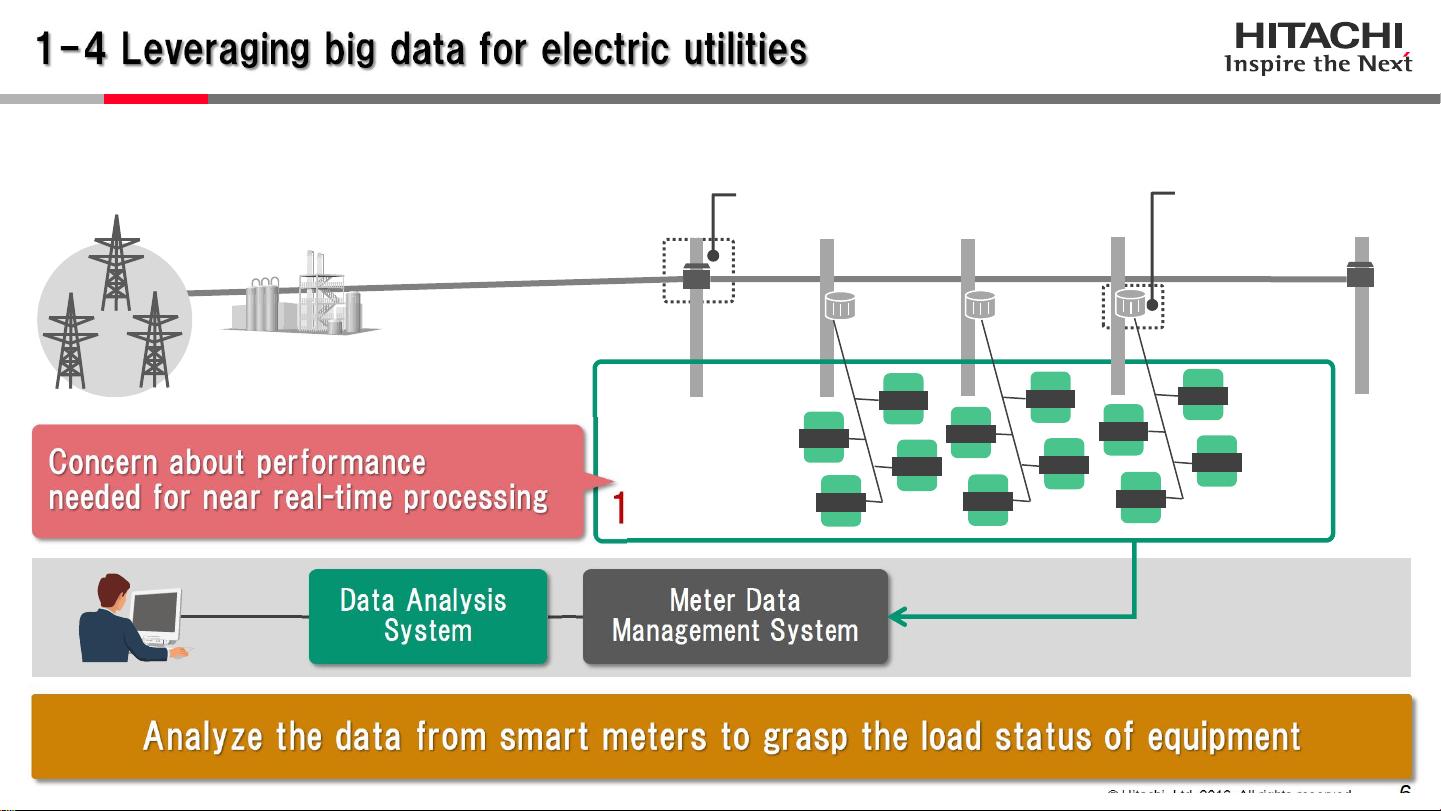
演讲的第一部分讨论了如何利用智能电表数据,这是一个实际的公用事业场景,旨在优化电力系统的运营效率。随着市场竞争加剧,电力公司面临降低电力传输费用的压力,政府也推动了零售电力市场的自由化。为了应对这些挑战,公用事业公司需要降低成本,包括对传输和分发设备的维护和更新。过去,设备更换决策通常是基于设备状况,但通过引入大数据技术,如Spark SQL和Hive,可以更有效地处理和分析大量数据,从而决定何时更换设备,降低运维成本。
第二部分是性能对比,对MapReduce和Spark 1.6进行了深入的评估。在这个环节,演讲者通过实际的智能电表数据处理案例,展示了Hive作为Hadoop生态系统中的查询语言在数据仓库中的作用,同时对比了Spark SQL,作为Apache Spark的SQL接口,其在数据处理速度、内存管理和计算性能上的优势。通过对比,观众可以了解到在处理大规模数据集时,Spark SQL能够提供更高的吞吐量和更快的查询响应时间。
第三部分则聚焦于Spark 2.0的额外评估。Spark 2.0引入了更先进的特性,如DataFrame API和执行计划优化,这些改进旨在提高代码的简洁性和执行效率。演讲者可能展示了如何在Spark 2.0中使用更高效的编程模型来处理复杂的数据操作,并且强调了其在性能和开发效率方面的提升。
总结部分回顾了整个演讲的核心发现,可能包括Spark SQL相对于Hive的优势,尤其是在处理实时数据、机器学习任务和分布式计算任务中的表现。演讲者还可能分享了在实际应用中,企业如何通过选择合适的工具,如Spark SQL,来适应市场变化,提高业务敏捷性,并降低成本。
整个演讲提供了深入的见解,帮助听众理解在云计算环境下,如何利用Spark SQL这一现代技术工具,与传统Hive框架竞争,以实现电力公用事业行业的数据驱动决策和高效运营。
5
© Hitachi, Ltd. 2016. All rights reserved.
• Decreasing nuclear plant as a stable power supplier
• Increasing renewable energy supply
u Unstable power supply
u Needs for high level Demand Response
• Rates by time zone (current demand response)
• Many and small renewable energy suppliers
• Near real-time demand response for each distribution system
Electricity rate
Power plant
Transmission
Lines
Substation Distribution
Lines
Home
Transmission and
Distribution Companies
Power
transmission fee
Electric Power
Generation
Companies
Electricity retailers
剩余31页未读,继续阅读
2025-01-09 上传
2025-01-09 上传
21电平MMC整流站、MMC逆变站、两端柔性互联的MATLAB仿真模型,4端柔性互联、MMC桥臂平均值模型、MMC聚合模型(四端21电平一分钟即能完成2s的工况仿真) 1-全部能正常运行,图四和图五为
2025-01-09 上传
2025-01-09 上传
2025-01-09 上传

weixin_38743506
- 粉丝: 351
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 模块化表格:用于构建模块化数据收集表格的软件包
- cordova_sample:如何将简单网站转换为移动cordova应用程序的示例
- DRColorPicker:适用于iOS的Digital Ruby,LLC颜色选择器
- LPC4330图纸-电路方案
- Poesie_Noire
- win64_11gR2_client.zip
- Project-Calculator
- ThatGeekyWeeb
- PINFuture:旨在提供最大类型安全性的Objective-C未来实现
- ddr_stress_tester_v3.00_setup.exe.zip
- 蓝桥杯嵌入式资料-电路方案
- SQLHelper快速建表工具.rar
- TIL:一直在进步。 我学到的一小堆狗屎
- WAP2.0的产品展示系统
- MVVMDemo:带有React性可可的MVVMDemo
- WAP2.0的手机网站留言板
