Python实现微信公众号爬虫:自动化数据采集与分析
需积分: 13 24 浏览量
更新于2024-07-16
收藏 3.09MB PDF 举报
"Python-实现微信公众爬虫.pdf"是一份针对Python编程爱好者和微信公众号运营者撰写的教程文档,它详细探讨了如何利用Python编写脚本来爬取微信公众号的文章数据,以便进行数据分析和优化公众号运营策略。这份教程填补了市场上的空白,因为虽然网络上普遍有关于网页爬虫的教程,但专门针对微信公众号的并不多,尤其缺乏针对搜狗微信这类平台的完整教程,而搜狗数据的不稳定性(如文章链接不可靠和缺乏关键指标)限制了其实际应用价值。
文档首先介绍了爬虫的基本原理,它是自动化数据采集工具,通过发送HTTP请求与目标服务器交互,获取并处理服务器响应的数据。爬虫的工作流程可以概括为:用户输入URL,客户端解析服务器地址,建立TCP连接,发送HTTP请求(包括请求方法、路径和协议版本),接收服务器的响应(含状态码、头部信息和可能的响应体),解析并提取数据,最后进行数据清洗和存储。
在HTTP协议方面,文档详细讲解了请求和响应的结构。HTTP请求通常包括请求行(方法、路径和协议版本)、请求头(如User-Agent标识客户端类型)以及可选的请求体(如登录凭证)。HTTP响应则有响应行(版本、状态码和说明)、响应头和响应体,后者可能包含所请求数据。
作者特别强调了HTTP请求和响应格式的重要性,它们确保了客户端和服务器之间的有效通信。例如,GET请求通常不包含请求体,而POST请求则需要携带数据。登录豆瓣网时的HTTP POST请求展示了这一概念的实际应用。
通过学习这份教程,读者不仅能掌握如何使用Python实现微信公众号爬虫,还能理解HTTP协议在爬虫中的核心作用,从而更好地进行数据抓取和分析,提升公众号运营的效果。无论是对于Python开发者还是社交媒体营销人员,这都是一份实用且具有价值的资源。
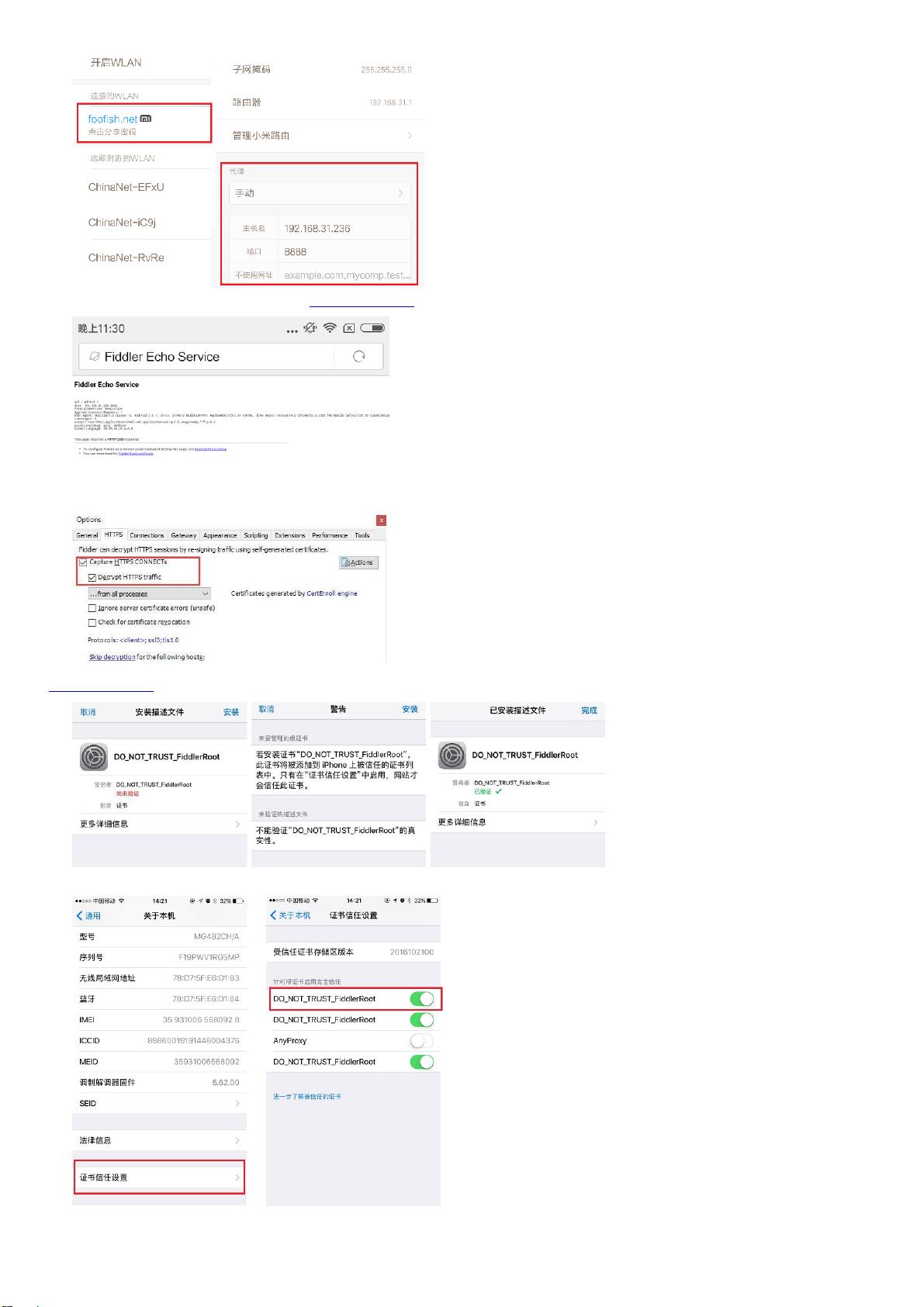
测试代理有没有设置成功可以在⼿机浏览器访问你配置的地址:http://192.168.31.236:8888/会显⽰Fiddler的回显页⾯,说明配置成功。
现在你打开任意⼀个HTTP协议的⽹站都能看到请求会出现在Fiddler窗⼜,但是HTTPS的请求并没有出现在Fiddler中,其实还差⼀个步骤,需要在Fiddler中激活HTTPS抓取设置。在Fiddler选择
Tools>FiddlerOptions>HTTPS>DecryptHTTPStraffic,重启Fiddler。
为了能够让Fiddler截取HTTPS请求,客户端都需要安装且信任Fiddler⽣成的CA证书,否则会出现“⽹络出错,轻触屏幕重新加载:-1200”的错误。在浏览器打开Fiddler回显页⾯
http://192.168.31.236:8888/下载FiddlerRootcertificate,下载并安装证书,并验证通过。
iOS下载安装完成之后还要从设置->通⽤->关于本机->证书信任设置中把Fiddler证书的开关打开
Android⼿机下载保存证书后从系统设置⾥⾯找到系统安全,从SD卡安装证书,如果没有安装证书,打开微信公众号的时候会弹出警告。
剩余23页未读,继续阅读
764 浏览量
906 浏览量
160 浏览量
2023-06-07 上传
4402 浏览量

小枫小枫
- 粉丝: 1
- 资源: 33
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android MVP 快速开发框架Android-ZBLibrary-master
- subject1_raw_mri.zip
- 程序员必须知晓的11个C++要点-供大家学习研究参考
- 4.4 RT-Thread 完成对AT2402 一个字节的读写
- 欧盟GDPR新版数据跨境转移标准合同条款(SCCs)
- 基于STM32F407的TCS230颜色识别的程序
- 基因测序-利用psa方法对基因测序进行开发
- WPF房屋租售管理系统
- 基因二代测序-分别对blast和bwa比对结果进行统计比较-20230506
- 使用HTML和JavaScript编写的猜数字游戏
- 基因测序-统计扩增子引物对应数据库的不同碱基的情况-20230529
- Unity地图随机生成插件 TileWorldCreator 3 v3.1.2p1
- YOLOv8 缺陷检测之AnyLabeling标注格式转换成YOLO格式, YOLO数据集划分为训练集,验证集和测试集
- 新路由3 newifi3 d2刷老毛子Padavan固件
- 答案.rar
- Web-Design-Challenge
