"DNA元基催化与肽计算的第5修订版本V00062191"
需积分: 0 117 浏览量
更新于2023-12-29
收藏 15.15MB PDF 举报
DNA元基催化与肽计算_第5修订版本V00062191是由罗瑶光和罗荣武编写的一部中英双语PPT,无源码的教材。本书共分为多个章节,其中第一章介绍了德塔自然语言图灵系统。在此章节中,讨论了德塔分词的催化切词优化方式,以及分词、排序、神经网络索引等内容。此外,还探讨了分词在线性文本搜索中的应用以及动态POS等概念。
DNA元基催化与肽计算是一门前沿性的研究领域,涉及到生物化学、计算机科学等多个学科的知识。通过对DNA元基的催化以及肽计算的研究,可以更深入地了解生物分子在计算机模拟中的应用,进而推动生物信息学和计算机科学的发展。本教材的第5修订版本主要对DNA元基催化与肽计算进行了全面的介绍和讨论,是相关领域的学习者和研究者不可多得的参考资料。
在第一章中,德塔自然语言图灵系统是一个重要的内容。德塔分词的催化切词优化方式涉及到自然语言处理领域的技术,这对于文本处理、语义分析等方面具有重要意义。分词、排序、神经网络索引等内容则涉及到信息检索、数据挖掘等领域,这些技术对于提高文本处理的效率和准确性有重要作用。分词在线性文本搜索中的应用以及动态POS也是当前自然语言处理领域的研究热点,对于提高搜索引擎的搜索结果和用户体验具有重要意义。
本教材的第5修订版本还介绍了DNA元基催化与肽计算的基本概念和原理。DNA元基催化是指在DNA分子中发挥催化作用的元基,它对DNA的结构和功能具有重要影响。肽计算则是指利用肽链的结构和特性进行计算的一种方法,它在生物信息学和药物设计等领域有着重要的应用价值。通过对DNA元基催化与肽计算的研究,可以为生物医药领域的研究和应用提供重要的理论支持和技术手段。
总之,DNA元基催化与肽计算_第5修订版本V00062191是一部内容全面、深入的教材,涵盖了德塔自然语言图灵系统、DNA元基催化与肽计算等多个方面的知识。本教材适用于生物信息学、计算机科学等相关专业的学习者和研究者,对于推动相关领域的研究和发展具有重要的意义。希望本教材能够为广大读者带来有益的知识和启发,推动相关领域的学术交流和科研成果的产出。

DNA 元基催化与肽计算_第 5 修订版本 V0006 16
constant values, balancing of the computing sets and the discrete conditional differentiations (Demorgan, Frequency flows etc).
And now those things widely were used in Deta’s catalytic family of technical community (Parser, Word segments, Mind reading,
NLP computing etc).
神经网络索引
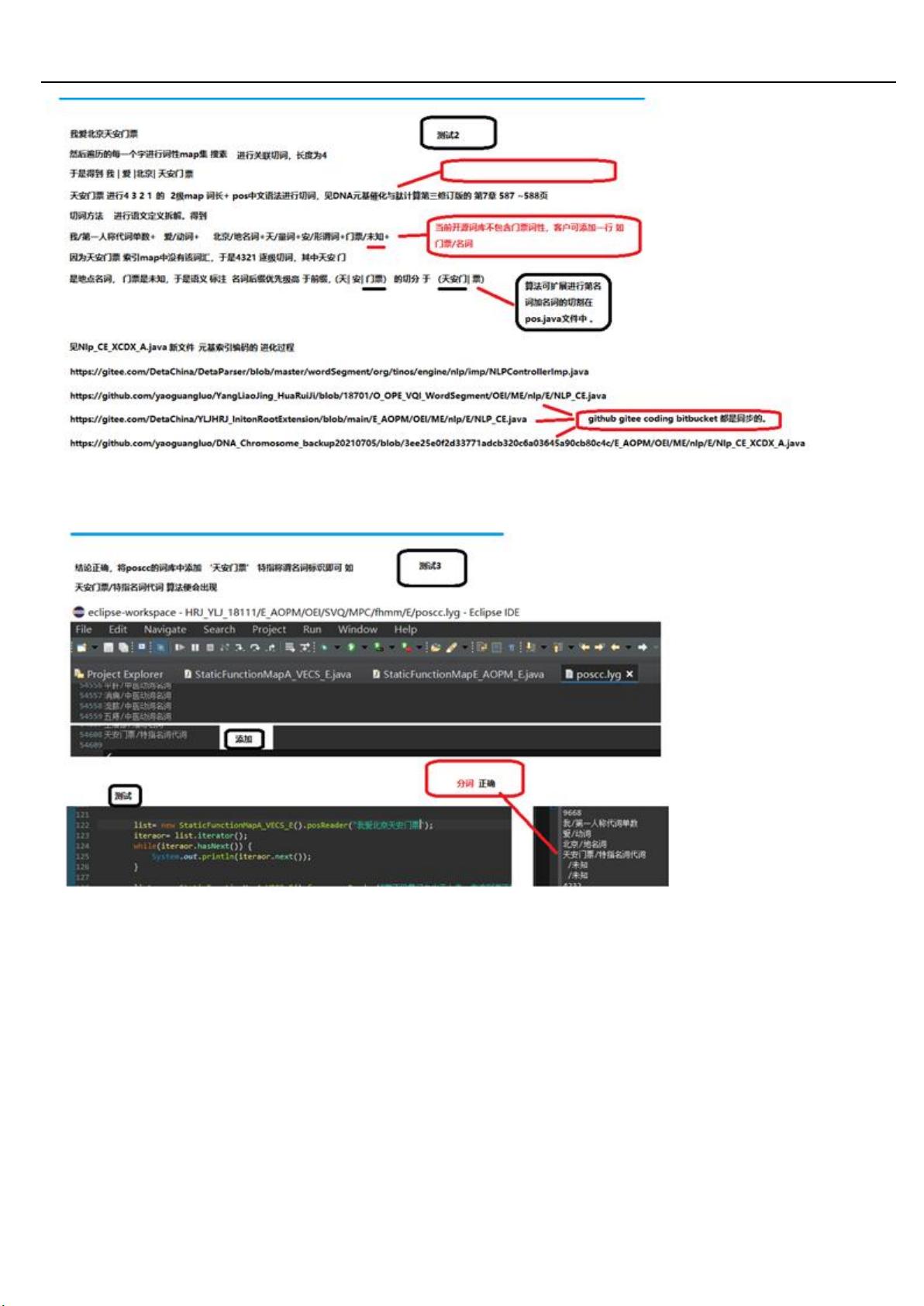
1 德塔分词的词汇字典用 map 进行索引, 因为 Jdk8+的 map 对象的 key 支持 2 分搜索, 搜索速度到了峰值. refer page,
129, 131
2 德塔分词的索引不断的将大 map 进行细化分类, 如词长 map, 词类 map, 词性 map, 让搜索再次加速. refer page 55,
3 德塔分词的索引 map 支持 2 次组合计算, 支持分布式服务器进行索引 cache. 关于 2 次组合计算作者不建议单机使用.
refer page 92,
4 德塔分词 map 的 key 用 string 的 char 对应 ASCII int 进行标识来执行 find key, 方便二分搜索存储和 StringBuilder
高速计算, 实现底层核统一. refer page 92
Nero Network Index Forest
1 Deta Parser did a word segmental indexed map by using humanoid semantic verbal dictionary, for the reason why using JDK8+
tool to do the map search logic, is that It had already integrated the binary search tree, balanced map-tree arrangement and other
technologies.
2 Deta Parser’s balanced binary search tree method made an observer mode of averaged classification with all types of the
reflection java concurrent maps, those maps included the char word length, verbal types and part of speech corpus, etc. The author
did It to accelerate the Nero-marching speedly for searching the words.
3 Deta Parser supported the secondary indexing computing combinations, this way could be suitable for the distributed cache of
searching systems. The author did not suggest this technology which be used on a single desktop.
4 For the computing logic, Finally Deta Parser functions used string builder to accelerate the searching engine.
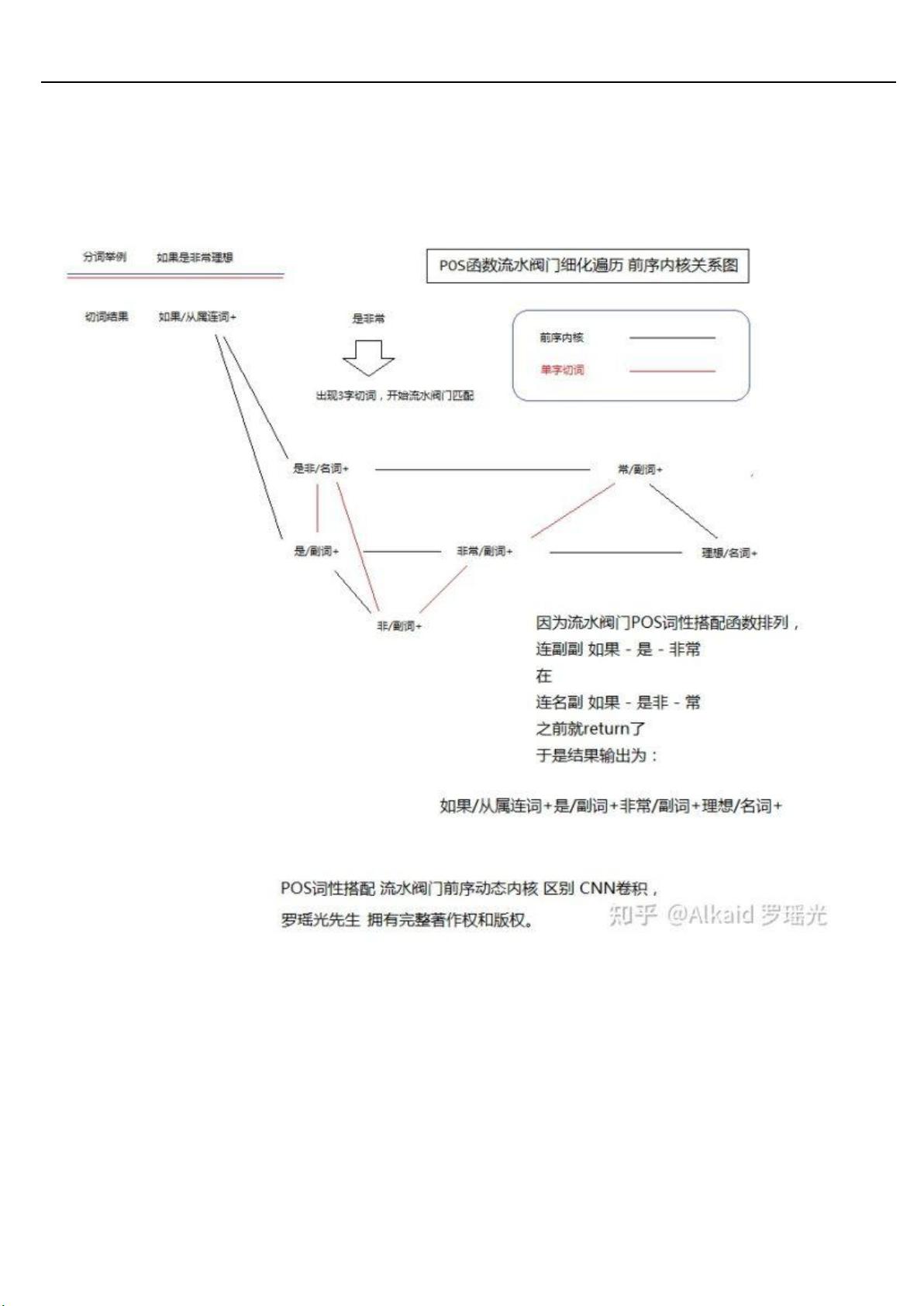
神经网络索引的价值主要体现在 2 个地方, 切词的关联索引上和 词汇 map 索引上. 切词的关联索引价值, 主要体现在将
词汇的文字进行链化提取, 这种链化计算方式将词库中本相对独立的海量词汇进行了按人类语言文学中的顶针方法进行
了有效的前后长度关联(NERO), 其价值有利于大文本的文字进行有必要关联链的 小段小段的提取(NLP), 类似挤牙膏一
样, 挤出来就刷牙用掉(POS).
词汇 map 索引价值, 主要体现在 词汇的文字进行链化合理切分, 这种链化切分方式将词库中根据不同属性的分类 map
来组合匹配按人类语言文学中的词汇词性和主谓宾搭配严谨定义来切分. 其价值在这些分类 map 可以自适应设计和多样
化扩展. 增加切词准确度和灵活度, 适应各种不同的场景, 类似牙刷机制, 挤出牙膏根据 匹配不同的牙刷和刷牙方法
(NERO + POS), 匹配适应不同的口腔环境. 描述人 罗瑶光, 稍后优化下.
The accomplishment of the neural network-index is mainly reflected in two sections, 1 for the relevanced index of word
segmentation, and 2 for the lexical indexed map. The associated and relevanced index-value of word segmentation, is mainly
reflected in the chained extraction of words. This chained calculation method effectively correlates the relatively independent of a
large number of words in the thesaurus, according to the Thimble Theory in human language and Literature (Nero). The value of
the big data documental process, splits the word chain links list into small chars-token (max 4) sections, and It is similar to a
squeezing toothpaste, and a brushing teeth (POS) after a squeezed out with the DetaParser marching engine.


剩余327页未读,继续阅读
2022-08-04 上传
2022-08-04 上传
2022-08-04 上传
2022-08-04 上传
2022-08-04 上传
2022-08-04 上传
2022-08-04 上传
2022-08-04 上传
2022-08-04 上传









