模式识别与机器学习:AdaBoost与模型选择
需积分: 0 147 浏览量
更新于2024-08-04
收藏 700KB DOCX 举报
"PRML_2016-2017-郭立东1"
这篇资料涉及了机器学习中的多种核心概念,包括模式识别、监督与非监督学习、欠拟合与过拟合、数据独立性、No Free Lunch Theorem、Occam's Razor原则以及AdaBoost算法的详细解释。接下来,我们将深入探讨这些知识点。
首先,模式识别是机器学习的基础,它关注的是如何从数据中提取有意义的结构或模式。模式不仅限于具体的物体,而是代表了信息的分布,强调了可观察性、可区分性和相似性。模式识别的关键在于从数据中发现规律并进行区分。
监督学习和非监督学习是两种主要的学习方式。监督学习是一种概念驱动的方法,它依赖于带有标签的数据来构建模型,例如支持向量机(SVM)。在处理欠拟合时,可以通过增大正则化参数(如SVM中的C值)来减少误分类的样本。反之,当模型出现过拟合时,降低C值可以提高模型的泛化能力。
非监督学习则是数据驱动的,它在无标签数据中寻找内在结构,例如聚类。在这种情况下,演绎假说是从数据中推断出潜在的模式或类别。
No Free Lunch Theorem指出,在所有问题平均分配且权重相等的情况下,任何算法的预期性能都是相同的。这意味着不存在一种通用的最佳算法,每个算法在特定问题上的表现会有所不同。因此,选择算法时应考虑其在特定问题上的适用性。
Occam's Razor原则主张在多个解释中选择最简洁的那个,因为更复杂的模型容易导致过拟合,降低泛化能力。在机器学习中,这意味着我们倾向于选择结构简单、参数较少的模型。
AdaBoost算法是一种集成学习方法,它通过组合多个弱分类器来构建一个强分类器。在每次迭代中,AdaBoost会赋予前一轮分类错误的样本更高的权重,使得后续的弱分类器更关注这些难分样本,从而提升整体分类性能。最终,这些弱分类器通过加权投票形成强分类器。
此外,资料还提到了最大似然估计(MLE)、EM算法以及最小错误率和最小风险贝叶斯的判别模型。最大似然估计是一种参数估计方法,通过最大化观测数据的概率来估计未知参数。EM(Expectation-Maximization)算法常用于处理含有隐藏变量的模型,它通过迭代更新来逐步优化参数估计。最小错误率贝叶斯和最小风险贝叶斯方法则是在决策理论框架下,以最小化错误率或期望风险为目标来构建判别函数。
这篇资料涵盖了模式识别的基本概念,以及监督学习、非监督学习、过拟合与欠拟合的处理,特别是AdaBoost算法的工作原理,最后介绍了最大似然估计和贝叶斯决策理论。这些知识构成了机器学习领域的重要基石。
i. 广义的说,存在于时间和空间中可观测的物体,如果我们可以区别它们是否相同或
者相似,都可以称之为模式。模式所指的不是事物本身,而是从事物获得的信息。
因此模式往往指的是具有时间或空间分布的信息。
ii. 模式的直观特征:可观察性,可区分性,相似性
iii. 主要方法:
a) 监督学习:概念驱动,归纳假说。
b) 非监督学习: 数据驱动,演绎假说。
i. 欠拟合,适当的增大 C 值,减少错分样本。
ii. 过拟合,适当的降低 C 值,增加模型的泛化能力。
iii. 训练数据和测试数据不是独立同分布,建议重新采样或者 shuffle 数据。
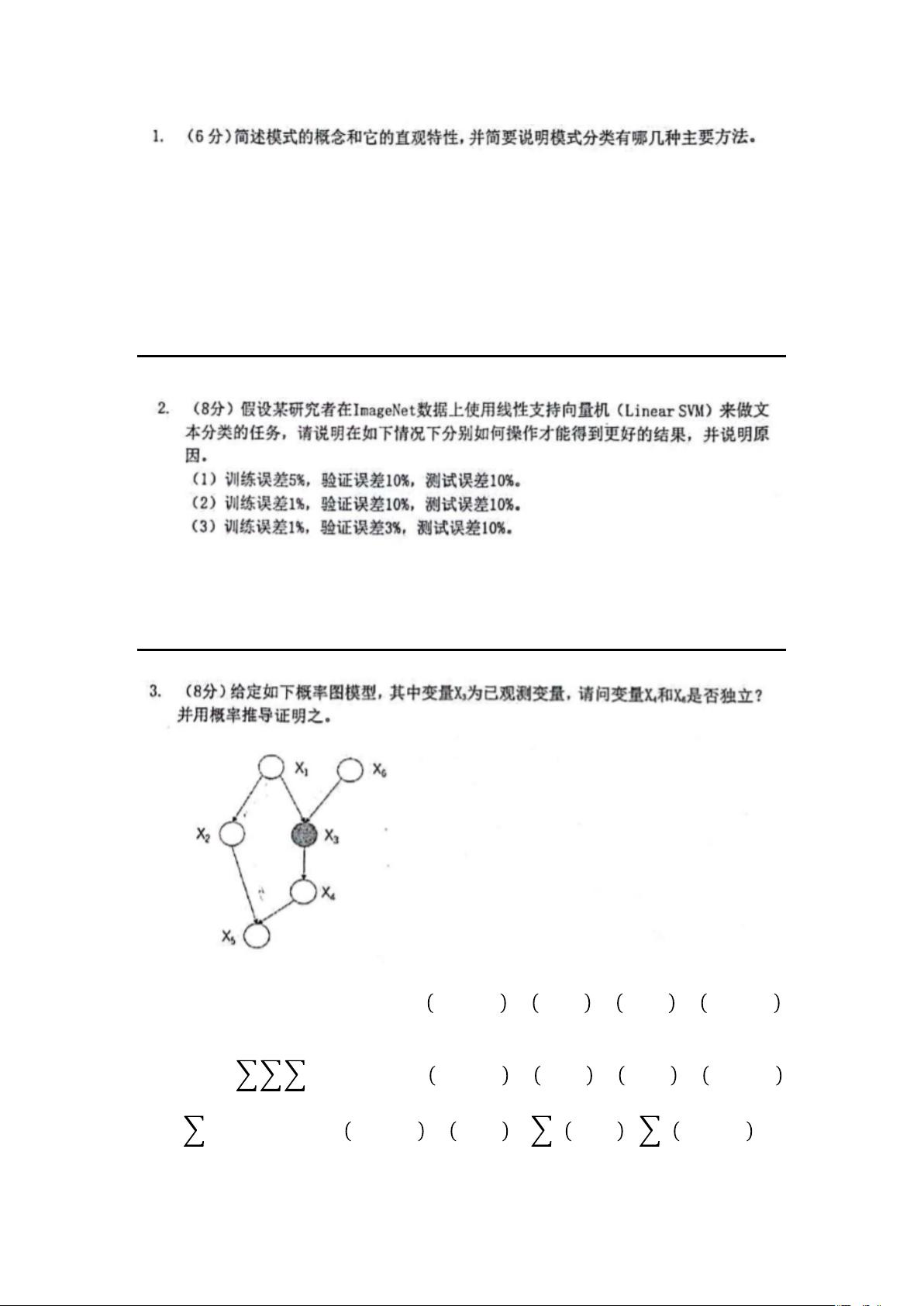
𝑝
(
𝑥1,𝑥2,𝑥3,𝑥4,𝑥5,𝑥6
)
=
𝑝
(
𝑥1
)
∗
𝑝
(
𝑥6
)
∗
𝑝
𝑥3
│
𝑥1,𝑥6
∗
𝑝
𝑥2
│
𝑥1
∗
𝑝
𝑥4
│
𝑥3
∗
𝑝
𝑥5
│
𝑥4,𝑥2
𝑝
(
𝑥3,𝑥4,𝑥6
)
=
𝑥1
𝑥2
𝑥5
𝑝
(
𝑥1
)
∗
𝑝
(
𝑥6
)
∗
𝑝
𝑥3
│
𝑥1,𝑥6
∗
𝑝
𝑥2
│
𝑥1
∗
𝑝
𝑥4
│
𝑥3
∗
𝑝
𝑥5
│
𝑥4,𝑥2
=
𝑥
1
𝑝
(
𝑥1
)
∗
𝑝
(
𝑥6
)
∗
𝑝
𝑥3
│
𝑥1,𝑥6
∗
𝑝
𝑥4
│
𝑥3
∗
𝑥2
𝑝
𝑥2
│
𝑥1
∗
𝑥5
𝑝
𝑥5
│
𝑥4,𝑥2
下载后可阅读完整内容,剩余7页未读,立即下载
2022-08-08 上传
2022-08-08 上传
2023-08-18 上传
2023-10-12 上传
2024-03-06 上传
2024-01-09 上传
2023-08-24 上传
2023-06-24 上传
2023-05-13 上传

断脚的鸟
- 粉丝: 23
- 资源: 301
 我的内容管理
展开
我的内容管理
展开







最新资源
- IPQ4019 QSDK开源代码资源包发布
- 高频组电赛必备:掌握数字频率合成模块要点
- ThinkPHP开发的仿微博系统功能解析
- 掌握Objective-C并发编程:NSOperation与NSOperationQueue精讲
- Navicat160 Premium 安装教程与说明
- SpringBoot+Vue开发的休闲娱乐票务代理平台
- 数据库课程设计:实现与优化方法探讨
- 电赛高频模块攻略:掌握移相网络的关键技术
- PHP简易简历系统教程与源码分享
- Java聊天室程序设计:实现用户互动与服务器监控
- Bootstrap后台管理页面模板(纯前端实现)
- 校园订餐系统项目源码解析:深入Spring框架核心原理
- 探索Spring核心原理的JavaWeb校园管理系统源码
- ios苹果APP从开发到上架的完整流程指南
- 深入理解Spring核心原理与源码解析
- 掌握Python函数与模块使用技巧
