Cloudera Impala指南:快速Hadoop数据分析
"Impala Guide"
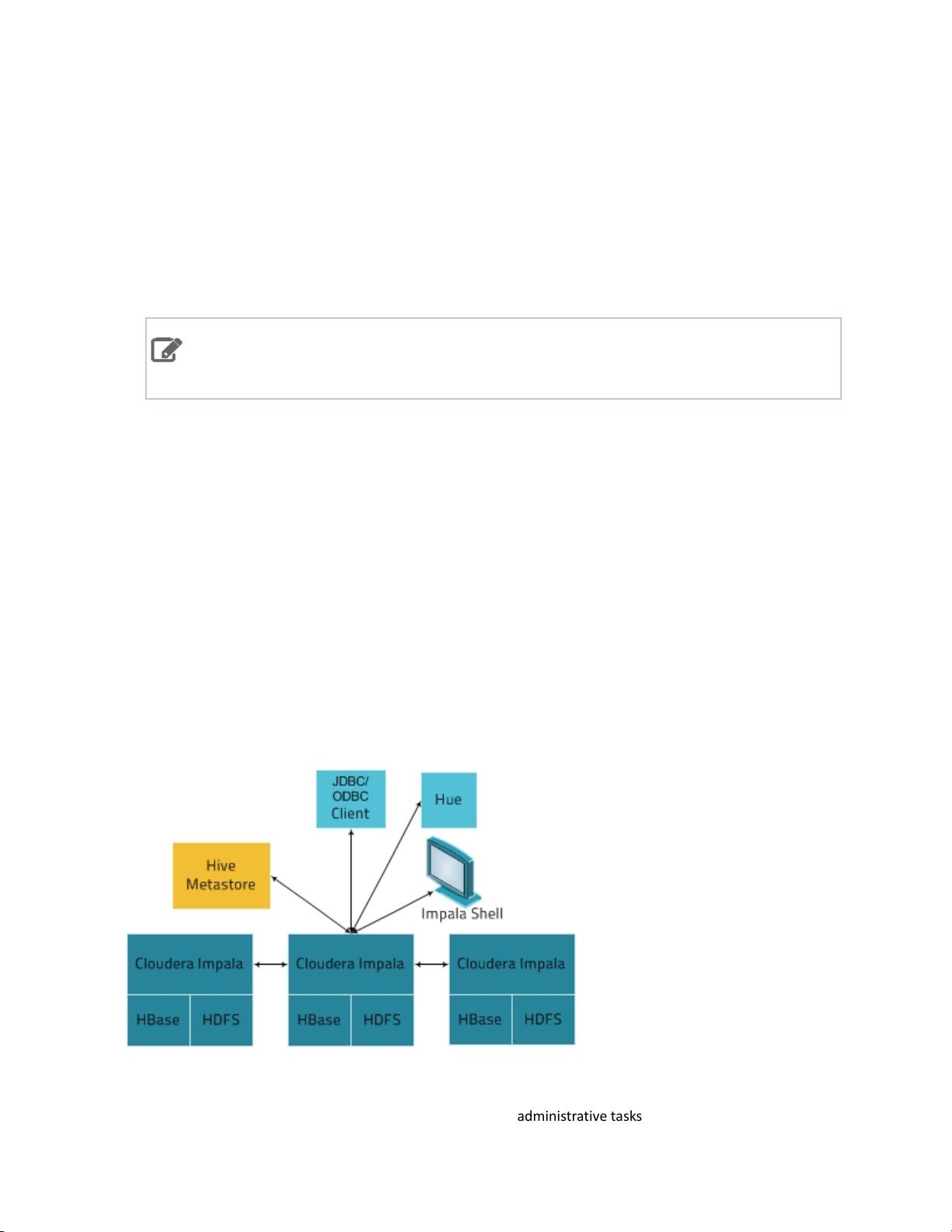
Cloudera Impala是一款针对Apache Hadoop数据的快速、交互式SQL查询系统,它能够直接处理存储在HDFS(Hadoop分布式文件系统)、HBase或Amazon S3上的数据。Impala的核心优势在于,它不仅与Hadoop的数据存储平台统一,而且共享了相同的元数据、SQL语法(基于Hive SQL)、ODBC驱动程序以及用户界面(如Hue中的Impala查询UI),这使得用户可以在实时查询和批处理查询之间无缝切换,提供了一个熟悉且统一的平台。
Impala的设计目标是解决传统Hadoop系统中数据分析速度较慢的问题,通过优化查询执行引擎和内存管理,实现了低延迟的查询性能。它可以处理大规模的数据集,适合大数据分析和商业智能应用。此外,由于与Hive的高度兼容性,Impala使得已经投资于Hive的企业无需进行大规模重构,就能享受到更高效的查询性能。
在Impala中,用户可以通过编写SQL查询来获取数据洞察,这些查询可以运行在分布式计算集群上,充分利用多节点并行处理能力。Impala的架构包括协调节点(Cordinator Node)和数据节点(Data Node),协调节点负责解析和优化查询,分配任务给数据节点,而数据节点则执行实际的数据处理工作。
Impala支持多种数据格式,如Parquet、Avro、Text和SequenceFile等,其中Parquet因其列式存储和压缩特性,通常能提供最佳的查询性能。同时,Impala还支持复杂的查询操作,如JOIN、GROUP BY、窗口函数等,这对于复杂的数据分析任务至关重要。
在安全方面,Impala可以与Hadoop的权限管理系统(如Kerberos)集成,实现细粒度的访问控制。此外,Impala还可以与其他Hadoop组件,如Hive、HBase、Sentry等协同工作,形成一个完整的数据处理和分析生态。
值得注意的是,虽然Impala和Hive在很多方面相似,但它们有各自的设计哲学和优化重点。Impala专注于交互式查询,而Hive更适合长时间运行的批处理作业。因此,选择使用Impala还是Hive,通常取决于具体的应用场景和性能需求。
Impala是Hadoop生态系统中的一员,为大数据分析提供了快速响应的SQL查询能力,使得企业能够更加灵活地处理和分析海量数据,同时保持与现有Hadoop工具的兼容性。在使用Impala时,应遵循相关的版权法律法规,尊重并保护知识产权。

Issues Fixed in the 2.1.4 Release / CDH 5.3.4.....................................................................................................................724
Issues Fixed in the 2.1.3 Release / CDH 5.3.3.....................................................................................................................725
Issues Fixed in the 2.1.2 Release / CDH 5.3.2.....................................................................................................................726
Issues Fixed in the 2.1.1 Release / CDH 5.3.1.....................................................................................................................727
Issues Fixed in the 2.1.0 Release / CDH 5.3.0.....................................................................................................................727
Issues Fixed in the 2.0.5 Release / CDH 5.2.6.....................................................................................................................728
Issues Fixed in the 2.0.4 Release / CDH 5.2.5.....................................................................................................................728
Issues Fixed in the 2.0.3 Release / CDH 5.2.4.....................................................................................................................728
Issues Fixed in the 2.0.2 Release / CDH 5.2.3.....................................................................................................................729
Issues Fixed in the 2.0.1 Release / CDH 5.2.1.....................................................................................................................729
Issues Fixed in the 2.0.0 Release / CDH 5.2.0.....................................................................................................................730
Issues Fixed in the 1.4.4 Release / CDH 5.1.5.....................................................................................................................731
Issues Fixed in the 1.4.3 Release / CDH 5.1.4.....................................................................................................................731
Issues Fixed in the 1.4.2 Release / CDH 5.1.3.....................................................................................................................732
Issues Fixed in the 1.4.1 Release / CDH 5.1.2.....................................................................................................................732
Issues Fixed in the 1.4.0 Release / CDH 5.1.0.....................................................................................................................733
Issues Fixed in the 1.3.3 Release / CDH 5.0.5.....................................................................................................................734
Issues Fixed in the 1.3.2 Release / CDH 5.0.4.....................................................................................................................734
Issues Fixed in the 1.3.1 Release / CDH 5.0.3.....................................................................................................................735
Issues Fixed in the 1.3.0 Release / CDH 5.0.0.....................................................................................................................736
Issues Fixed in the 1.2.4 Release........................................................................................................................................738
Issues Fixed in the 1.2.3 Release........................................................................................................................................739
Issues Fixed in the 1.2.2 Release........................................................................................................................................739
Issues Fixed in the 1.2.1 Release........................................................................................................................................740
Issues Fixed in the 1.2.0 Beta Release................................................................................................................................741
Issues Fixed in the 1.1.1 Release........................................................................................................................................741
Issues Fixed in the 1.1.0 Release........................................................................................................................................742
Issues Fixed in the 1.0.1 Release........................................................................................................................................742
Issues Fixed in the 1.0 GA Release.....................................................................................................................................744
Issues Fixed in Version 0.7 of the Beta Release..................................................................................................................746
Issues Fixed in Version 0.6 of the Beta Release..................................................................................................................747
Issues Fixed in Version 0.5 of the Beta Release..................................................................................................................748
Issues Fixed in Version 0.4 of the Beta Release..................................................................................................................748
Issues Fixed in Version 0.3 of the Beta Release..................................................................................................................749
Issues Fixed in Version 0.2 of the Beta Release..................................................................................................................749



剩余749页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-03-28 上传
2020-03-25 上传
2019-09-15 上传
2019-03-24 上传
2018-06-14 上传
2018-11-01 上传

PyQter
- 粉丝: 14
- 资源: 39
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
