CentOS双节点Hadoop完全分布式安装教程
需积分: 10 36 浏览量
更新于2024-09-08
收藏 156KB DOCX 举报
"本教程详细介绍了在CentOS环境下,如何搭建Hadoop的完全分布式集群,包括创建用户、配置网络、修改系统设置、设置主机名和主机映射,以及验证网络连通性。"
Hadoop完全分布式安装是一个复杂的过程,涉及到多个步骤和配置,以确保集群中的节点能够有效地协同工作。在这个过程中,我们首先需要在操作系统层面进行一些基础设置,然后配置Hadoop的相关参数,最后进行集群的验证。
1. **用户与权限设置**
创建一个新的用户`hadoop`,并使用`/bin/bash`作为默认shell。通过`passwd`命令设置该用户的密码。接着,切换到`root`用户,修改`sudoers`文件,添加新用户的sudo权限,以便在需要时以管理员身份执行命令。
2. **网络配置**
禁用IPv6以简化网络配置,避免可能出现的通信问题。在`/etc/sysctl.conf`中添加两条配置,然后执行`sysctl -p`使改动生效。通过`sestatus`检查并关闭SELinux,以防止它阻止Hadoop服务的正常运行。如果需要,可以通过修改`/etc/selinux/config`文件永久关闭SELinux。
3. **主机名与IP地址**
修改主机名,例如在Master节点上设置`HOSTNAME=Master`,在Slave1节点上设置`HOSTNAME=Slave1`。使用`ifconfig`获取每个节点的IP地址,并在`/etc/hosts`文件中记录所有节点的IP映射,包括主节点和从节点,同时删除原来的`localhost`映射。重启系统以应用这些更改。
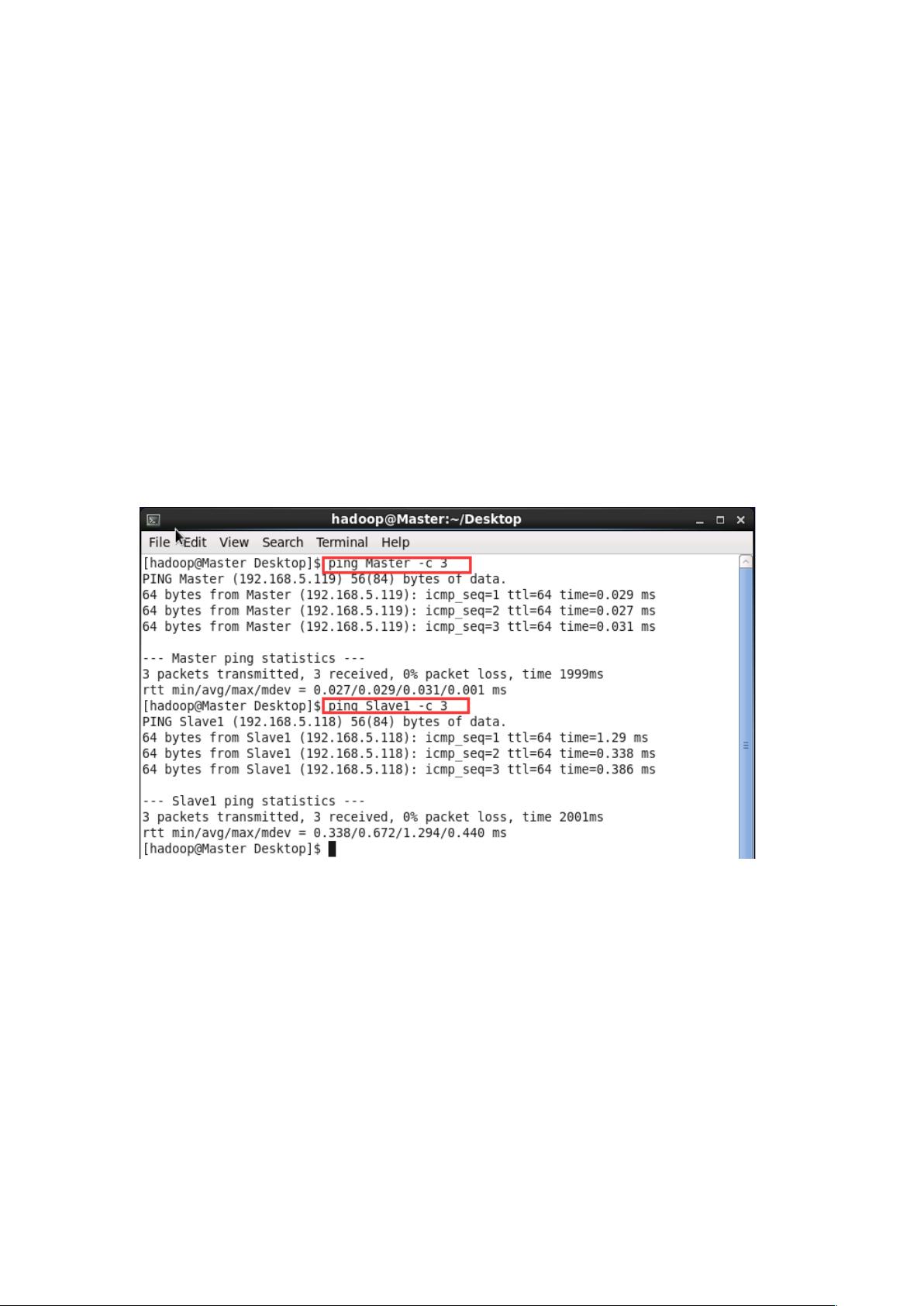
4. **网络连通性验证**
在完成上述步骤后,通过`ping`命令测试Master和Slave1之间的网络连通性。在Master节点上执行`ping Master -c 3`,在Slave1节点上执行`ping Slave1 -c 3`,确保网络通信正常。
5. **Hadoop配置**
在网络配置完成后,需要在每个节点上配置Hadoop的相关文件,如`core-site.xml`、`hdfs-site.xml`、`mapred-site.xml`和`yarn-site.xml`,定义HDFS的NameNode、DataNode、ResourceManager、NodeManager等服务的角色分配。还需要在` slaves`文件中列出所有的从节点,以便Hadoop知道在哪里启动DataNode和NodeManager。
6. **启动与测试**
启动Hadoop服务,包括`namenode`、`datanode`、`resourcemanager`和`nodemanager`,并使用Hadoop的命令行工具如`hdfs dfsadmin -report`或Web UI来检查集群状态,确认所有服务都已启动且节点状态正常。
7. **故障排查**
如果在安装过程中遇到问题,比如节点无法加入集群,可能需要检查防火墙设置、SSH配置、Hadoop日志,或者重新检查上述步骤,确保没有遗漏。
Hadoop完全分布式安装是一个涉及多步骤的过程,需要细心操作和耐心调试。一旦成功,将能构建一个强大的数据处理平台,支持大规模的数据存储和分析任务。
在 从节点上重复上述步骤
配置完成后,在 节点和 节点上都要执行:
,6
,6只 ,6 次,否则要按 7中断,,
命令用来测试主机之间网络的连通性;8完成次数9:设置完成要
求回应的次数;
,通的话会显示 ,显示的结果如图所示:
二、SSH 无密码登陆节点
在 节点的终端中执行:
:#如果没有该目录,先执行一次
#&;删除之前生成的公匙(如果有)
2*,一直按回车就可以添加 类型密码
剩余11页未读,继续阅读
2022-11-02 上传
2015-09-29 上传
2018-05-24 上传
2022-03-20 上传
2019-04-18 上传
2018-10-10 上传

Hugh_Tang
- 粉丝: 4
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
