简化海量数据处理:MapReduce编程模式详解
需积分: 3 137 浏览量
更新于2024-07-29
收藏 217KB DOC 举报
MapReduce是Google提出的一种革命性的编程模型,专为大规模数据处理而设计。它简化了处理海量数据集的过程,让用户无需深入理解并发处理或分布式系统细节。核心思想是将复杂的并行计算任务分解为两个主要阶段:map和reduce。
在Map阶段,用户编写一个map函数,该函数接收键值对作为输入,通过处理这些对,生成一系列中间的键值对。这个过程可以看作是对原始数据的预处理,每个map任务独立运行,可以并行地在大量机器上执行,提高了效率。这一步骤的关键在于将数据分布到集群的不同节点,由运行时系统自动处理数据的分发和调度。
在Reduce阶段,所有具有相同键的中间键值对会被收集在一起,然后应用reduce函数进行聚合操作,如求和、计数或平均等,生成最终结果。这个阶段确保了数据的一致性和完整性,即使在有机器故障的情况下也能通过容错机制进行恢复。
MapReduce模式的应用广泛,涵盖了搜索引擎的索引构建、社交网络分析、日志处理等各种场景。例如,Google利用MapReduce对海量网页抓取数据进行处理,生成排序后的索引,或者统计用户行为数据,找出频繁搜索的关键字。它的优势在于编程模型相对简单,程序员只需关注业务逻辑,其余的并发控制、数据分布和错误处理等工作都由MapReduce框架自行处理。
Google的MapReduce系统在实践中展现出了极高的扩展性,一个普通的计算任务可能涉及上千台机器,处理的TB级数据量。这样的设计使得非分布式系统背景的开发者也能够轻松构建和部署大规模数据处理应用。至今,MapReduce已经成为大数据处理领域的标准工具,许多开源项目如Apache Hadoop等也基于此理念进行开发,进一步推动了大数据时代的到来。
本届描述了 Google 广泛使用的计算环境:用交换机网络[4]连接的,由普通 PC 构成的超大集群。
在我们的环境里:
(1) 每个节点通常是双 x86 处理器,运行 Linux,每台机器 2-4GB 内存。
(2) 使用的网络设备都是常用的。一般在节点上使用的是 100M/或者千 M 网络,一般情况下
都用不到一半的网络带宽。
(3) 一个 cluster 中常常有成百上千台机器,所以,机器故障是家常便饭。
(4) 存储时使用的便宜的 IDE 硬盘,直接放在每一个机器上。并且有一个分布式的文件系统
来管理这些分布在各个机器上的硬盘。文件系统通过复制的方法来在不可靠的硬件上保
证可用性和可靠性。
(5) 用户向调度系统提交请求。每一个请求都包含一组任务,映射到这个计算机 cluster 里的
一组机器上执行。
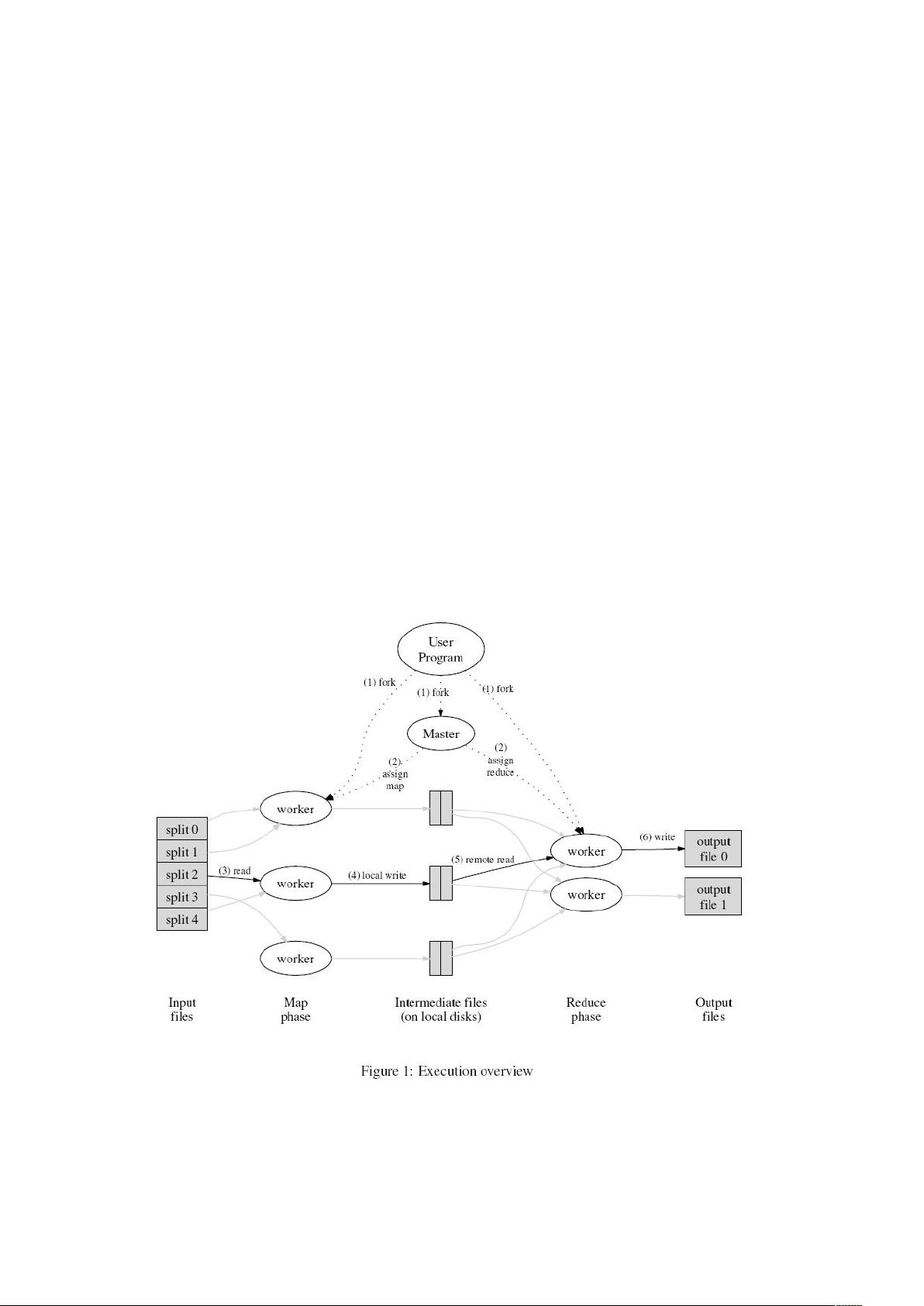
3.1 执行概览
Map 操作通过把输入数据进行分区(partition)(比如分为 M 块),就可以分布到不同的机器上
执行了。输入块的拆成多块,可以并行在不同机器上执行。Reduce 操作是通过对中间产生的 key
的分布来进行分布的,中间产生的 key 可以根据某种分区函数进行分布(比如 hash(key) mod
R),分布成为 R 块。分区(R)的数量和分区函数都是由用户指定的。
图 1 是我们实现的 MapReduce 操作的整体数据流。当用户程序调用 MapReduce 函数,就会引起
如下的操作(图一中的数字标示和下表的数字标示相同)。
第 4 页
剩余18页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2012-03-20 上传
2013-07-31 上传
2011-05-13 上传
2017-08-14 上传
2019-02-27 上传
2019-02-27 上传

liufangzhe793528089
- 粉丝: 5
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
