开放通道SSD上的LSM-Tree键值存储优化设计
需积分: 8 8 浏览量
更新于2024-08-05
收藏 4.66MB PDF 举报
"Open-Channel SSD on LSM.pdf"
这篇论文探讨了在开放通道固态硬盘(Open-Channel SSD)上实现基于LSM-Tree(Log-Structured Merge Tree)的键值存储(Key-Value Store)的高效设计与实现。LSM-Tree是一种常见的用于非易失性存储的数据结构,它通过消除随机写入并保持良好的读取性能,特别适合大数据和互联网服务的数据管理。
首先,我们需要理解LSM-Tree的基本原理。LSM-Tree将数据分批写入磁盘,通过合并操作(Merge)将小的写入操作合并成大的顺序写入,从而减少对闪存的随机访问,因为顺序写入在SSD上比随机写入更有效率。它通常由内存中的数据结构(例如内存表和压缩块)和磁盘上的数据结构(如SSTables)组成。当内存表满时,数据会被写入到磁盘,并对磁盘上的数据进行排序和合并。
然而,传统的SSD被设计为黑盒设备,操作系统和文件系统看不到内部的物理块管理和写入放大问题。而Open-Channel SSD则打破了这种模式,它允许应用程序直接控制闪存的读写操作,提供了更高的灵活性和性能潜力。论文中提到,这种直接控制可以更好地利用SSD的特性,例如减少不必要的写入放大,优化垃圾回收(Garbage Collection)过程,以及更有效地利用SSD的带宽。
论文作者们提出了一种新的设计方案,该方案针对Open-Channel SSD的特点,优化了LSM-Tree的结构和操作。他们可能包括以下关键点:
1. **块分配策略**:由于Open-Channel SSD允许直接管理块,因此可以设计更有效的分配策略来减少写入放大,比如预分配空间以避免频繁的块迁移。
2. **读取优化**:由于没有内置的缓存机制,读取操作可能需要更多的优化,例如通过维护更有效的索引结构来加速查找。
3. **写入合并**:在Open-Channel SSD上,可以更精细地控制写入合并,使得顺序写入更加高效。
4. **垃圾回收**:由于对硬件的直接访问,可以设计更高效的垃圾回收策略,减少不必要的读写操作,提高SSD的寿命。
5. **性能监控与调优**:通过直接访问SSD的统计信息,可以实时监控SSD的状态,动态调整工作负载以适应SSD的性能特征。
论文还可能涉及实际系统实现的细节,包括如何处理错误恢复、并发控制以及在大规模部署中的扩展性问题。通过这样的设计,论文的目标是实现一个在Open-Channel SSD上运行的LSM-Tree键值存储系统,它能够充分利用SSD的性能优势,同时减少由传统SSD设计带来的性能瓶颈。
这篇论文是关于如何在开放通道SSD上构建高效、低延迟的LSM-Tree键值存储的深度研究,对于理解如何优化非易失性存储设备上的数据管理系统具有重要的理论和实践价值。通过这种方式,可以为大数据中心提供更高性能和更低延迟的存储解决方案。
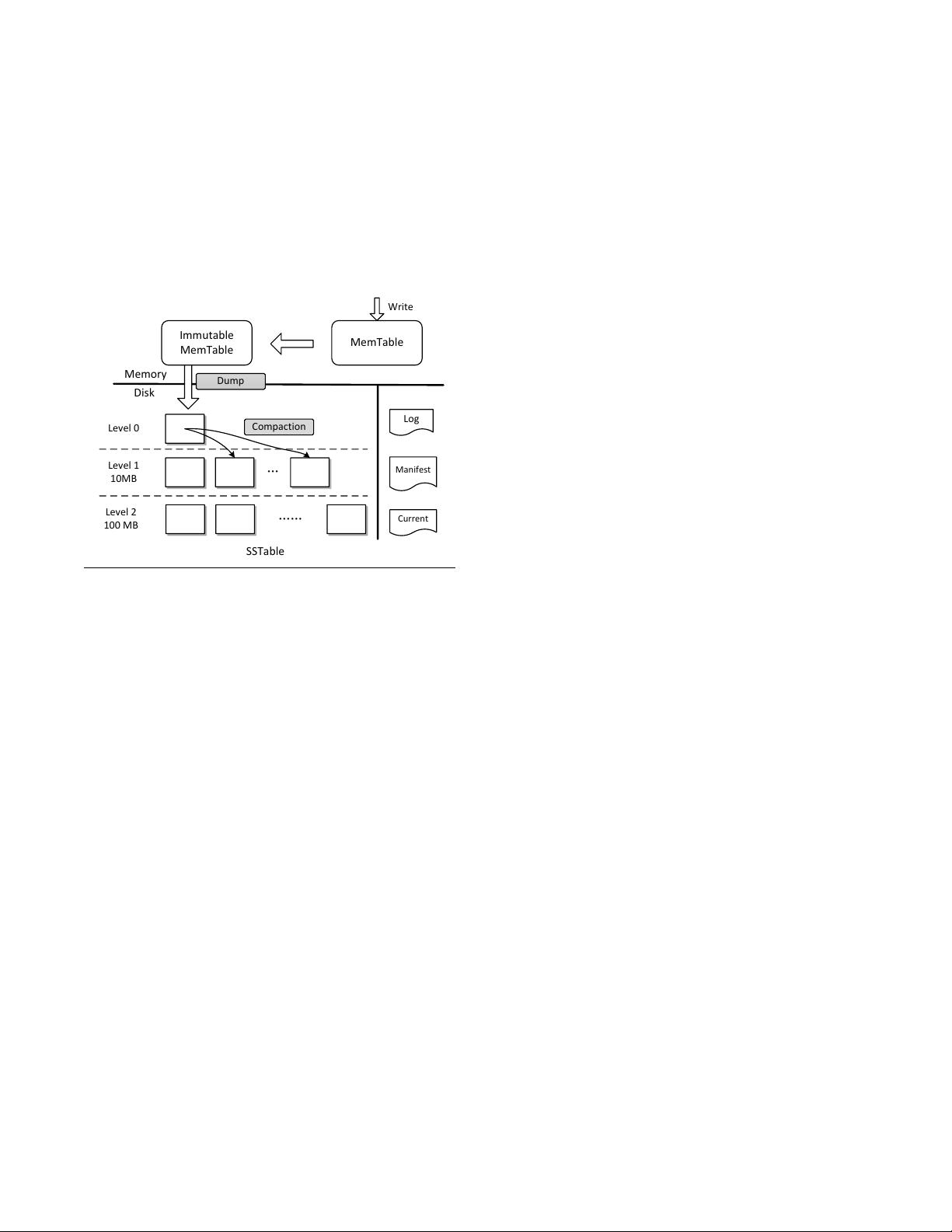
2.1 LevelDB
LevelDB is an open source key-value store that originated
from Google’s BigTable [18]. It is an implementation of
LSM-tree, and it has received increased attention in both
industry and academia [6][34][2]. Figure 1 illustrates the
architecture of LevelDB, which consists of two MemTables
in main memory and a set of SSTables [18] in the disk and
other auxiliary files, such as the Manifest file which stores
the metadata of SSTables.
MemTable
Write
Immutable
MemTable
Memory
Disk
Dump
……
…
Level 0
Level 1
10MB
Level 2
100 MB
Compaction
Log
Manifest
Current
SSTable
Figure 1. Illustration of the LevelDB architecture.
When the user inserts a key-value pair into LevelDB, it
will be first saved in a log file. Then it is inserted into a sorted
structure in memory, called MemTable, which holds the
most recent updates. When the size of incoming data items
reaches its full capacity, the MemTable will be transformed
into a read-only Immutable MemTable. A new MemTable
will be created to accumulate fresh updates. At the same
time, a background thread begins to dump the Immutable
MemTable into the disk and generate a new Sorted String
Table file (SSTable). Deletes are a special case of update
wherein a deletion marker is stored.
An SSTable stores a sequence of data items sorted by
their keys. The set of SSTables are organized into a series
of levels, as shown in Figure 1. The youngest level, Level 0,
is produced by writing the Immutable MemTable from main
memory to the disk. Thus SSTables in Level 0 could contain
overlapping keys. However, in other levels the key range of
SSTables are non-overlapping. Each level has a limit on the
maximum number of SSTables, or equivalently, on the total
amount of data because each SSTable has a fixed size in a
level. The limit grows at an exponential rate with the level
number. For example, the maximum amount of data in Level
1 will not exceed 10 MB, and it will not exceed 100 MB for
Level 2.
In order to keep the stored data in an optimized layout,
a compaction process will be conducted. The background
compaction thread will monitor the SSTable files. When the
total size of Level L exceeds its limit, the compaction thread
will pick one SSTable from Level L and all overlapping
ones from the next Level L+1. These files are used as inputs
to the compaction and are merged together to produce a
series of new Level L+1 files. When the output file has
reached the predefined size (2 MB by default), another new
SSTable is created. All inputs will be discarded after the
compaction. Note that the compaction from Level 0 to Level
1 is treated differently than those between other levels. When
the number of SSTables in Level 0 exceeds an upper limit
(4 by default), the compaction is triggered. The compaction
may involve more than one Level 0 file in case some of them
overlap with each other.
By conducting compaction, LevelDB eliminates over-
written values and drops deleted markers. The compaction
operation also ensures that the freshest data reside in the
lowest level. The stale data will gradually move to the higher
levels.
The data retrieving, or read operation, is more compli-
cated than the insertion. When LevelDB receives a Get(Key,
Value) request, it will first do a look up in the MemTable,
then in Immutable MemTable, and finally search the SSTa-
bles from Level 0 to higher levels in the order until a matched
KV data item is found. Once LevelDB finds the key in a cer-
tain level, it will stop its search. As we mentioned before,
lower levels contain fresher data items. The new data will be
searched earlier than old data. Similar to compaction, more
than one Level 0 file could be searched because of their data
overlapping. A Bloom filter [14] is usually adopted to re-
duce the I/O cost for reading data blocks that do not contain
requested KV items.
2.2 Open-Channel SSD
The open-channel SSD we used in this work, SDF, is a
customized SSD widely deployed in Baidu’s storage infras-
tructure to support various Internet-scale services [33]. Cur-
rently more than 3 000 SDFs have been deployed in the pro-
duction systems. In SDF, the hardware exposes its internal
channels to the applications through a customized controller.
Additionally, it enforces large-granularity access and pro-
vides lightweight primitive functions through a simplified
I/O stack.
The SDF device contains 44 independent channels. Each
flash channel has a dedicated channel engine to provide
FTL functionalities, including block-level address mapping,
dynamic wear leveling, bad block management, as well as
the logic for the flash data path. From an abstract view of
software layer, the SDF exhibits the following features.
First, SDF exposes the internal parallelism of SSD to user
applications. As mentioned previously, each channel of an
SDF has its exclusive data control engine. In contrast to the
conventional SSD, where the entire device is considered as
a single block device (e.g., /dev/sda), SDF presents each
channel as an independent device to the applications (e.g.,
from /dev/ssd0 to /dev/ssd43). With the capability of
directly accessing individual flash channels on SDF, the user
剩余13页未读,继续阅读
点击了解资源详情
677 浏览量
119 浏览量
352 浏览量
190 浏览量
144 浏览量
2021-07-13 上传
2022-07-11 上传
187 浏览量

我是新星
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- bash脚本编写教程
- WSC/ADL:Web Services组合系统体系结构描述语言
- 常用开源软件说明手册
- 高质量c++编程指南
- map reduce by google inc
- bigtable by google inc
- U-BOOT 在S3C2410的移植
- 《计算机组成原理》第一章课件
- Practical Apache Struts 2 Web 2.0 Projects.pdf
- ACM+算法集--常用ACM算法
- 华为电路设计规范,得到很多人的认可
- sq安装步骤,安装问题
- linux下建立DNS
- Arcgis开发宝典
- 是个IC资料 PDF型的
- 办公自动化EXECL(提高操作EXECL的能力)
