Kafka分布式流平台:消息队列的优势与工作模式解析
143 浏览量
更新于2024-08-30
收藏 463KB PDF 举报
"Kafka框架基础概念,包括其作为分布式流平台的角色、消息队列的优势、消息队列的两种模式(点对点和发布/订阅),以及Kafka的消费者和生产者概念及其工作流程中的offset管理变化。"
Kafka是Apache开发的一个开源分布式流处理平台,设计目标是提供高吞吐量的实时处理能力。它被广泛用于大数据处理领域,特别是在网站动作流数据的处理上。Kafka作为一个消息队列系统,具备以下关键特点:
1. **灵活性与峰值处理能力**:消息队列允许系统在面临突发流量时保持稳定,避免因过载而导致服务崩溃。通过将请求缓存于队列中,关键组件得以缓解压力。
2. **解耦**:Kafka使得生产者和消费者可以独立发展,只需确保两者遵循相同的协议,这增强了系统的可维护性和可扩展性。
3. **异步通信**:消息的处理不需即时完成,用户可以将消息放入队列并在需要时处理,提高了系统效率。
4. **可恢复性**:通过消息队列,即使部分组件故障,也不会影响整个系统的运作,因为消息可以在系统恢复后继续处理。
5. **缓冲作用**:当生产和消费速度不匹配时,消息队列可以作为缓冲,避免数据丢失或系统瓶颈。
Kafka的消息队列有两种基本模式:
- **点对点模式**:每个消息仅被一个消费者消费,保证了数据处理的顺序,适合需要独占处理的数据场景。
- **发布/订阅模式**:一个消息可以被多个消费者消费,支持广播式的数据分发,适用于需要多点同步的情景。
在Kafka的工作流程中,消费者的offset(表示消费位置)管理经历了变化。在Kafka 0.9之前的版本,offset存储在Zookeeper中;从0.9版本开始,offset被存储在Kafka内的一个特殊topic "__consumer_offsets",这简化了offset的管理和提供了更高效的性能。
- **Producer**:负责生成消息并发送给Kafka集群的客户端。
- **Consumer**:消息的消费者,负责从Kafka集群中获取并处理消息。
理解这些基本概念是掌握Kafka的关键,对于构建高效、可靠的分布式数据处理系统至关重要。
Kafka框架基础概念框架基础概念
Kafka是一个分布式流平台,高吞吐量的分布式发布/订阅模式的消息队列(系统),它可以处理消费者在网站中的所有动作流数
据,应用于大数据处理领域。
消息队列的好处:消息队列的好处:
1.灵活性&峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨
大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
2.解耦:
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
3.异步通信:
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理
它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
4.可恢复性:可恢复性:
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入
队列中的消息仍然可以在系统恢复后被处理。
5.缓冲:缓冲:
有助于控制和优化数据流经过系统的速度, 解决生产消息和消费消息的处理速度不一致的情况。
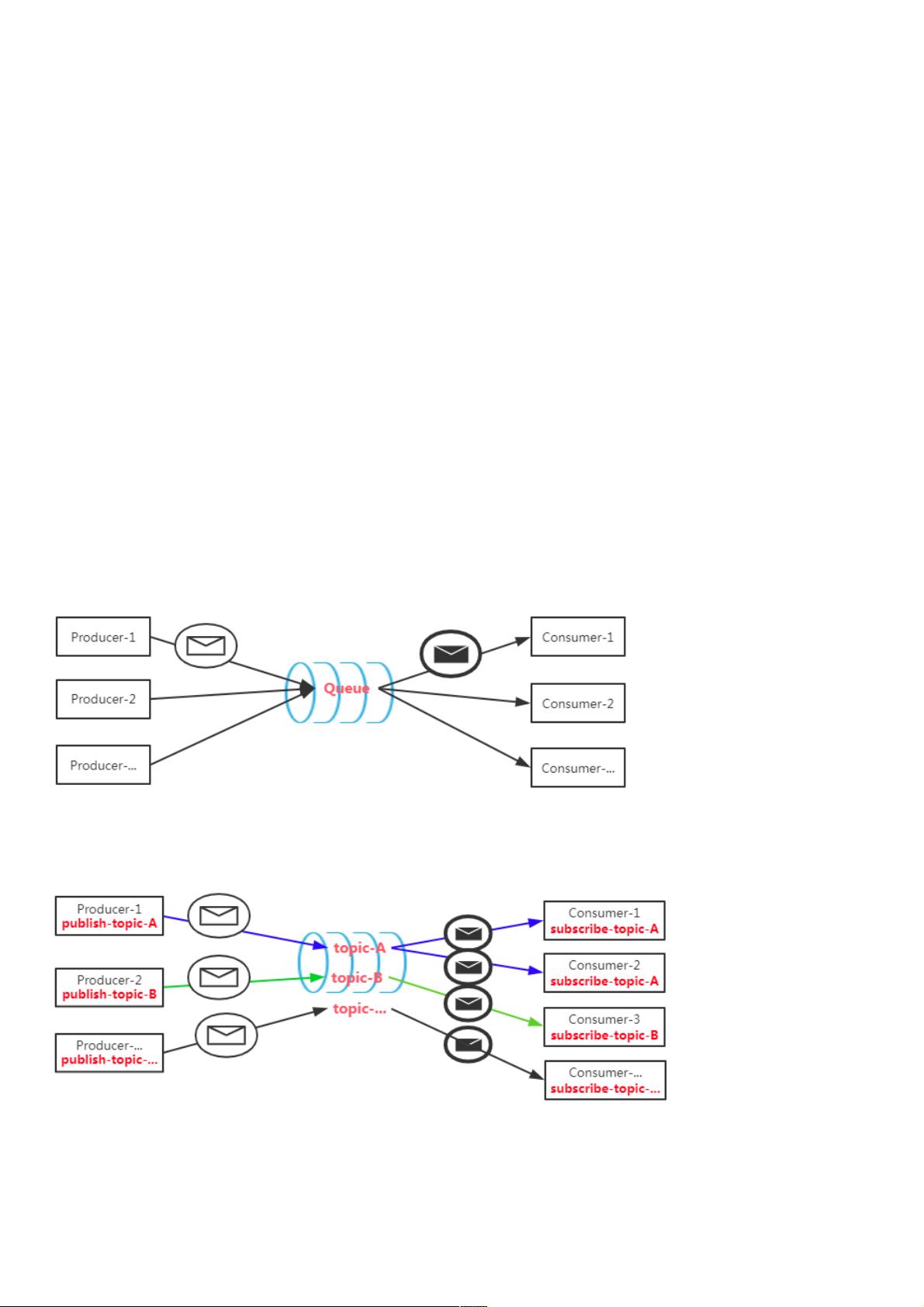
消息队列的两种模式:消息队列的两种模式:
1.点对点模式:点对点模式:一对一,消费者主动拉取数据,消费者收到数据后从队列中删除,即使有多个消费者同时消费数据,也能保证
数据处理的顺序。
如下图:生产者发送消息到如下图:生产者发送消息到Queue,只有一个消费者能收到。,只有一个消费者能收到。
2.发布发布/订阅模式:订阅模式:一对多,消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据,同一条数据可以被多个
消费者消费,数据被消费后不会立马删除。
如下图:生产者如下图:生产者发送到发送到topic的消息,消费者订阅了生产者的的消息,消费者订阅了生产者的topic才会收到消息。才会收到消息。
主动拉取数据:主动拉取数据:
1.维护长轮询
2.生产者消息来了,通知消费者根据自身条件拉取
推送消费者数据:推送消费者数据:
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
183 浏览量
点击了解资源详情
2024-04-24 上传
点击了解资源详情
2021-03-09 上传
2021-03-16 上传
点击了解资源详情
点击了解资源详情

weixin_38617602
- 粉丝: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- HaneWin DHCP Server 3.0.34:全面支持DHCP/BOOTP的服务器软件
- 深度解析Spring 3.x企业级开发实战技巧
- Android平台录音上传下载与服务端交互完整教程
- Java教室预约系统:刷卡签到与角色管理
- 张金玉的个人简历网站设计与实现
- jiujie:探索Android项目的基础框架与开发工具
- 提升XP系统性能:4G内存支持插件详解
- 自托管笔记应用Notes:轻松跟踪与搜索笔记
- FPGA与SDRAM交互技术:详解读写操作及代码分享
- 掌握MAC加密算法,保障银行卡交易安全
- 深入理解MyBatis-Plus框架学习指南
- React-MapboxGLJS封装:打造WebGL矢量地图库
- 开源LibppGam库:质子-伽马射线截面函数参数化实现
- Wa的简单画廊应用程序:Wagtail扩展的图片库管理
- 全面支持Win7/Win8的MAC地址修改工具
- 木石百度图片采集器:深度采集与预览功能
