RNN在自然语言处理中的应用详解
需积分: 0 23 浏览量
更新于2024-08-04
收藏 203KB DOCX 举报
"周报-0726-覃春桃1"
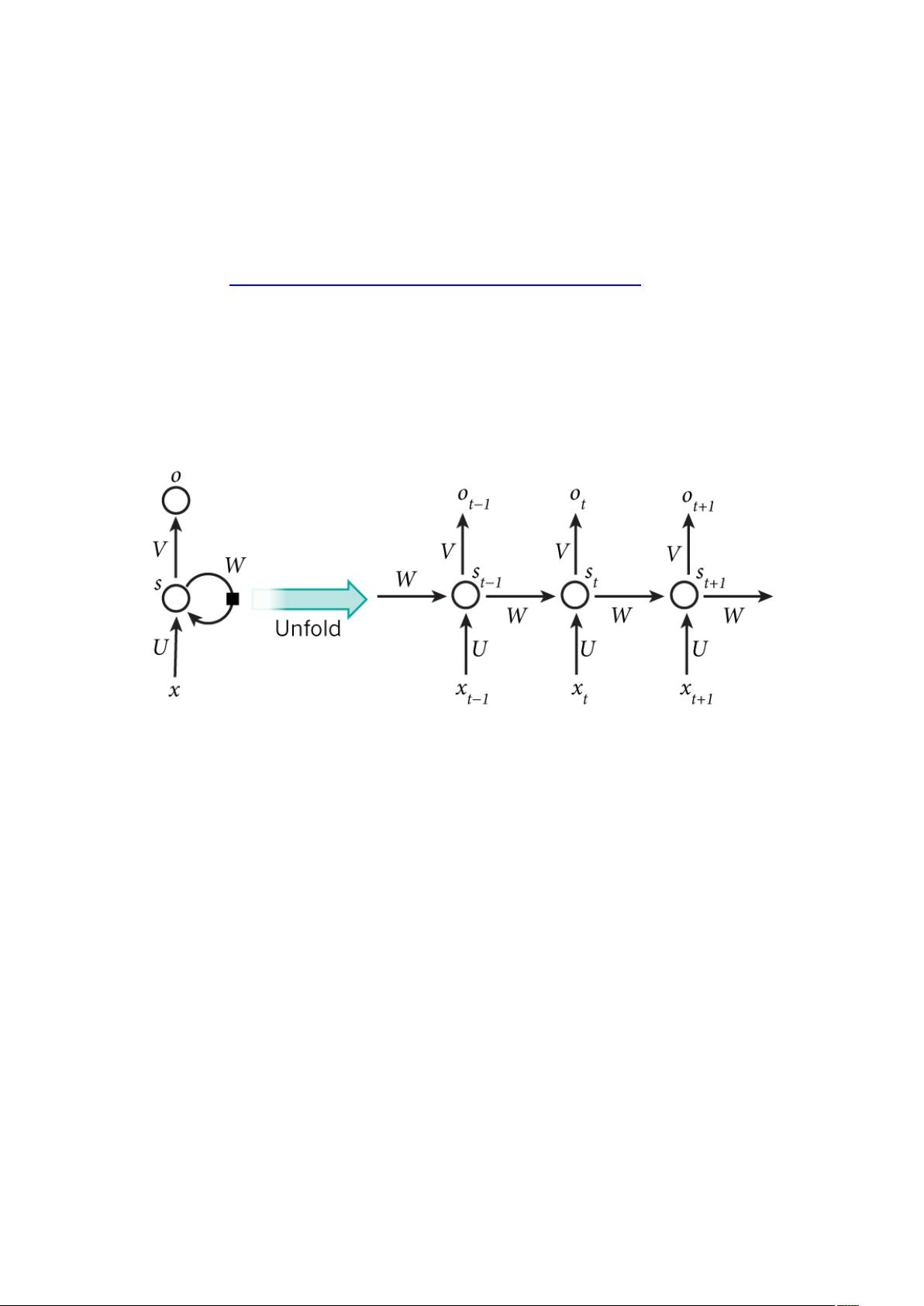
本周的学习重点围绕着循环神经网络(RNN)及其在语言模型中的应用展开。循环神经网络是一种特殊的神经网络结构,它允许信息在时间轴上流动,因此特别适合处理序列数据,如自然语言。在自然语言处理中,RNN被用来构建语言模型,其目标是根据已知的一段文本预测下一个可能出现的词汇。
传统的语言模型如N-Gram模型,存在明显的局限性,即只能依赖有限的历史上下文(N-1个词)来预测下一个词,无法捕捉更复杂的依赖关系。随着N值增大,内存需求增加,但实际效果提升有限。相比之下,RNN通过其循环结构,理论上可以考虑任意长度的上下文信息,从而在预测时更加准确。
在构建RNN语言模型的过程中,首先需要将词汇转化为向量表示。这里常用的方法是one-hot编码,即将每个词映射为一个长为词典大小的向量,仅有一个元素为1,其余为0。例如,如果词典包含六个词,则每个词可以用六个维度的向量表示,对应位置的1表示该词。
RNN的输入和输出都是向量形式。在处理序列数据时,每次输入一个词的one-hot向量,RNN会更新其内部状态,然后预测下一个词的向量。预测阶段,通常会使用Softmax层,它能将神经网络的输出转换为各个可能词汇的概率分布。Softmax函数将输入向量的元素转换为归一化的概率值,确保所有概率之和为1。
通过训练RNN,我们可以让模型学习到语言的统计规律,从而在给定一段文本后,模型能够计算出每个词出现的概率,并选择概率最高的词作为预测结果。这样的模型在自动文本生成、机器翻译、语音识别等领域有着广泛的应用。
总结而言,本周的学习深入探讨了RNN如何利用其内在的反馈机制处理时间序列数据,特别是在语言模型中的应用,以及如何通过one-hot编码和Softmax层实现词汇的向量化和概率预测。这种理解有助于进一步掌握深度学习在自然语言处理中的核心原理和技术。
周报二
一、参考文献:《基于 RNN 的语言模型》
二、网址:https://www.zybuluo.com/hanbingtao/note/541458
三、关键词:机器学习;深度学习入门;RNN;语言模型
四、收获:
(1)RNN 被应用于自然语言处理的原因
循环神经网络(RNN)既有前馈通路,又有反馈通路,因此在语音识别中可以有效
的处理时间序列的上下文信息,可以做到联系上下文,因而 RNN 最先是在自然语言处
理领域被运用起来,RNN 可以为语言模型来建模,何为语言模型?通俗的说就是给定一
句话的前半部分,预测接下来的词是什么,也就是说对一种语言的特征进行建模。
在使用 RNN 前,采用的是 N-Gram:是一种语音识别中常用的语言模型,该模型的特点是第
n 个词的出现只与前面 N-1 个词相关,而与其它任何词都不相关,例子:我今天吃饭____,如果
采用 2-Gram 进行建模,在电脑预测时只会看见前面的【了】字,电脑只会在语料库中找出在
【了】后面与之匹配度最大的概率,显然错误率会很大,而提升 N 值的大小是没有实用性的,N
越大,所占用的内存空间就会越大。因此才用 RNN 具有反馈的特性,理论上可往前或往后看任
意多个词来用于语言模型
下载后可阅读完整内容,剩余4页未读,立即下载
2024-12-26 上传
2024-12-26 上传
2024-12-26 上传
2024-12-26 上传

LauraKuang
- 粉丝: 23
- 资源: 334
 我的内容管理
展开
我的内容管理
展开







最新资源
- ok:K5编程语言的开源解释器
- vue-tiny-loading-overlay:vue.js 2x的任何元素的微小轻量级加载叠加指令
- baseview:音频插件UI的低级窗口系统界面
- cnn_gru-regression-master.zip
- 毕业设计&课设--大学毕业设计.zip
- 数据分析
- Excel模板00固定资产管理台帐.zip
- emgo:恩戈
- stop-words:支持合并的 code.google.compstop-words 的分支
- 毕业设计&课设--大学毕业设计(Web系统),企业人力资源管理系统(小型),前端采用Bootstrap框架,后端使用.zip
- unSAFE_MODE:SAFE_MODE系统更新程序的3DS用户级二次利用。 这实际上是一个相当安全的hax(͡°͜ʖ͡°)
- Excel模板企业公司部门预付款申请表单模板.zip
- holoclean:一种用于数据丰富的机器学习系统
- YANADU_DICT:The Conlang YANADU字典自动程序
- plex-api-graphql:用于Plex API的非官方GraphQL服务器
- mayorleaguec12:Basi HTML页面
