C语言实现信源熵计算
需积分: 46 180 浏览量
更新于2024-09-09
4
收藏 255KB DOCX 举报
本次任务是关于信息论中的信源熵计算,主要涉及使用C语言编程来处理文件中的字符数据,统计字符出现频率并计算信源熵。作业要求首先忽略文件中字符的大小写,统计每个字符的数量,然后根据这些数量计算每个字符的概率,最后利用信源熵的公式来求得熵的值。通过对多个文件的熵进行比较,可以分析不同文件的信息不确定性。
信源熵是信息论中的核心概念,它度量了一个信源的平均信息量或者不确定性。对于一个离散随机变量X,其可能的取值为x1, x2, ..., xn,对应的概率分别为p1, p2, ..., pn,信源熵H(X)可以通过以下公式计算:
\[ H(X) = -\sum_{i=1}^{n} p_i \log_2(p_i) \]
在这个任务中,首先需要读取文件并统计所有小写字母出现的次数。C语言代码中,定义了一个长度为26的整型数组`alpha`来存储每个小写字母的计数,同时定义了`H`来保存计算得到的信源熵。`openfile`函数用于打开用户指定的文件,而`statis`函数则负责读取文件内容,统计每个字符的出现次数,并关闭文件。在这个过程中,使用`tolower`函数将大写字母转换为小写字母,确保统计时不区分大小写。
在计算了字符概率后,可以使用上述信源熵的公式来计算熵。在给出的示例中,文件C.TXT的内容被用于演示,计算出的熵值表示了该文件字符分布的不确定性。接着,比较了a.txt、b.txt和c.txt三个文件的熵,发现H(a)>H(b)>H(c),这表明a.txt具有最高的信息不确定性,而c.txt的不确定性最低。
通过比较多个文件的熵,我们可以了解到信源熵的变化与文件内容的多样性和复杂性有关。熵较大的文件通常包含更丰富的信息或更大的不确定性,而熵较小的文件则可能更规律、结构化。
在C语言程序中,可能还需要编写一个函数来计算熵值,例如:
```c
double calculateEntropy(int* charCounts, int totalChars) {
double entropy = 0.0;
for (int i = 0; i < 26; i++) {
if (charCounts[i] > 0) {
double prob = (double) charCounts[i] / totalChars;
entropy -= prob * log2(prob);
}
}
return entropy;
}
```
这个函数接受字符计数数组和总字符数,计算熵并返回结果。在实际应用中,可能还需要考虑非字母字符和其他字符的情况,以及可能存在的非英文字符。
通过理解和运用信源熵的概念,我们可以量化一个信源的信息不确定性,这对于数据压缩、编码效率评估以及通信系统的优化等有着重要的理论和实践意义。
信息论与编码第一次作业
通信系统的各种信源中,离散随机信源是最基本的一种信源,信源输出是单个的符号的消
息,并且消息之间是两两互不相容的。本设计要求深刻理解信源熵的计算方法。
具体内容为:
(1)输入一个文件,首先对文件中的字符总个数进行统计(忽略大小写),然后从文本头
开始查找同一字符个数,并计算其概率最后由得出的字符概率求得信源熵。
答:已知信源熵的计算公式如下:
H ( X )=
∑
i
p( x
i
) I (x
i
)=−
∑
i
p (x
i
)log p (x
i
)
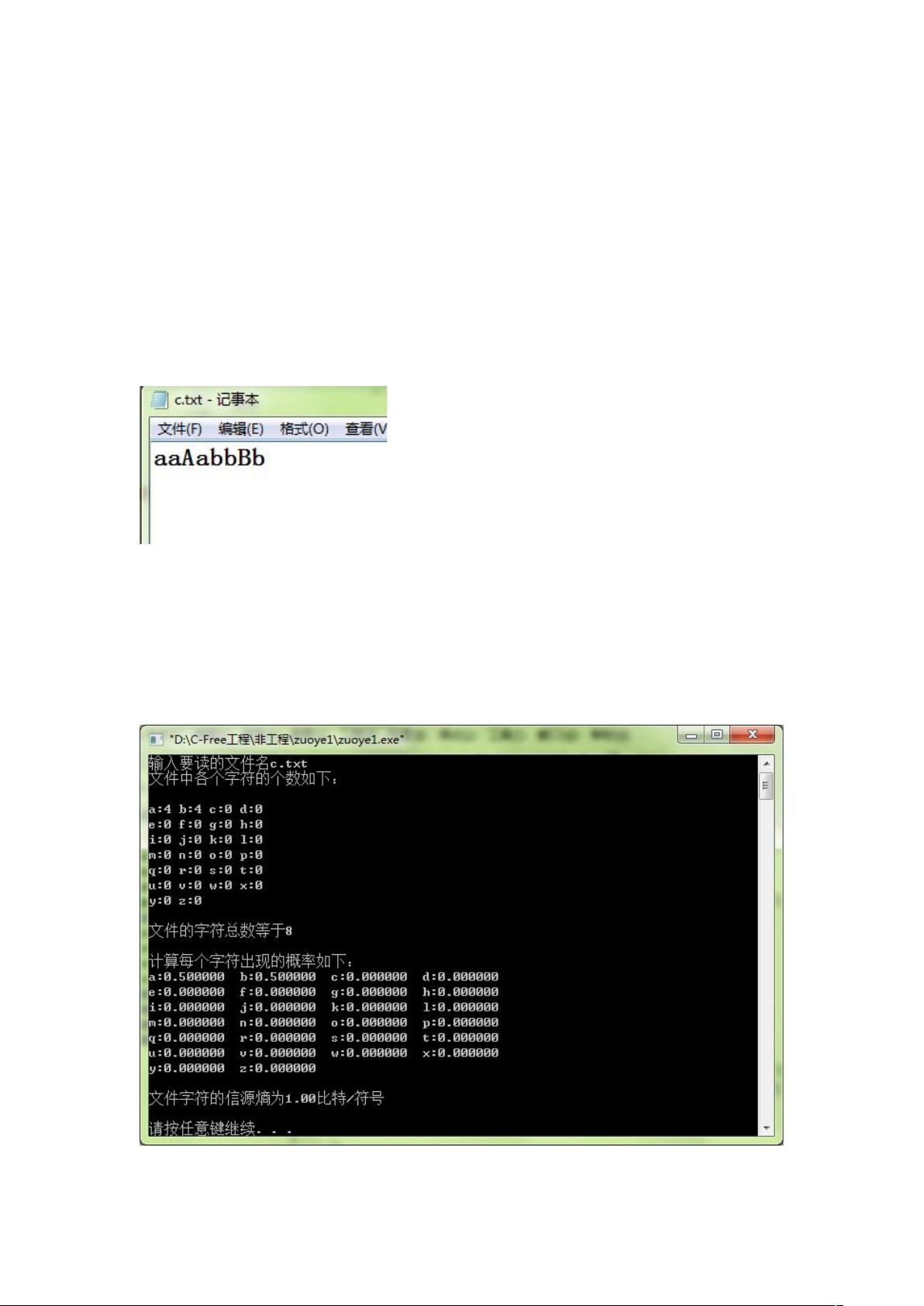
现在在文件 C.TXT 中存入如下字符:
可知:
[
Y ¿
]
¿
¿
¿¿
H (Y )=−0 .5 log0 . 5−0 . 5 log 0 .5=1比特 /符号
现在用 C 语言计算其信源熵,结果如下:
下载后可阅读完整内容,剩余4页未读,立即下载
2024-07-20 上传
2024-07-19 上传
2024-07-19 上传
2011-07-01 上传
2023-09-18 上传
2022-05-20 上传
点击了解资源详情
2013-11-30 上传
2024-05-15 上传









