Hadoop HDFS源代码深度解析
需积分: 9 93 浏览量
更新于2024-07-27
收藏 1.84MB PDF 举报
"Hadoop源代码分析 - HDFS篇"
在深入Hadoop源代码分析之前,首先需要理解HDFS(Hadoop Distributed File System)的核心概念。HDFS是一个分布式文件系统,设计用于运行在廉价硬件上,提供了高容错性和高吞吐量的数据存储。Hadoop的源代码分析有助于开发者更好地理解其内部工作原理,从而优化性能,解决潜在问题,或者进行定制化的开发。
HDFS主要由以下几个关键组件构成:
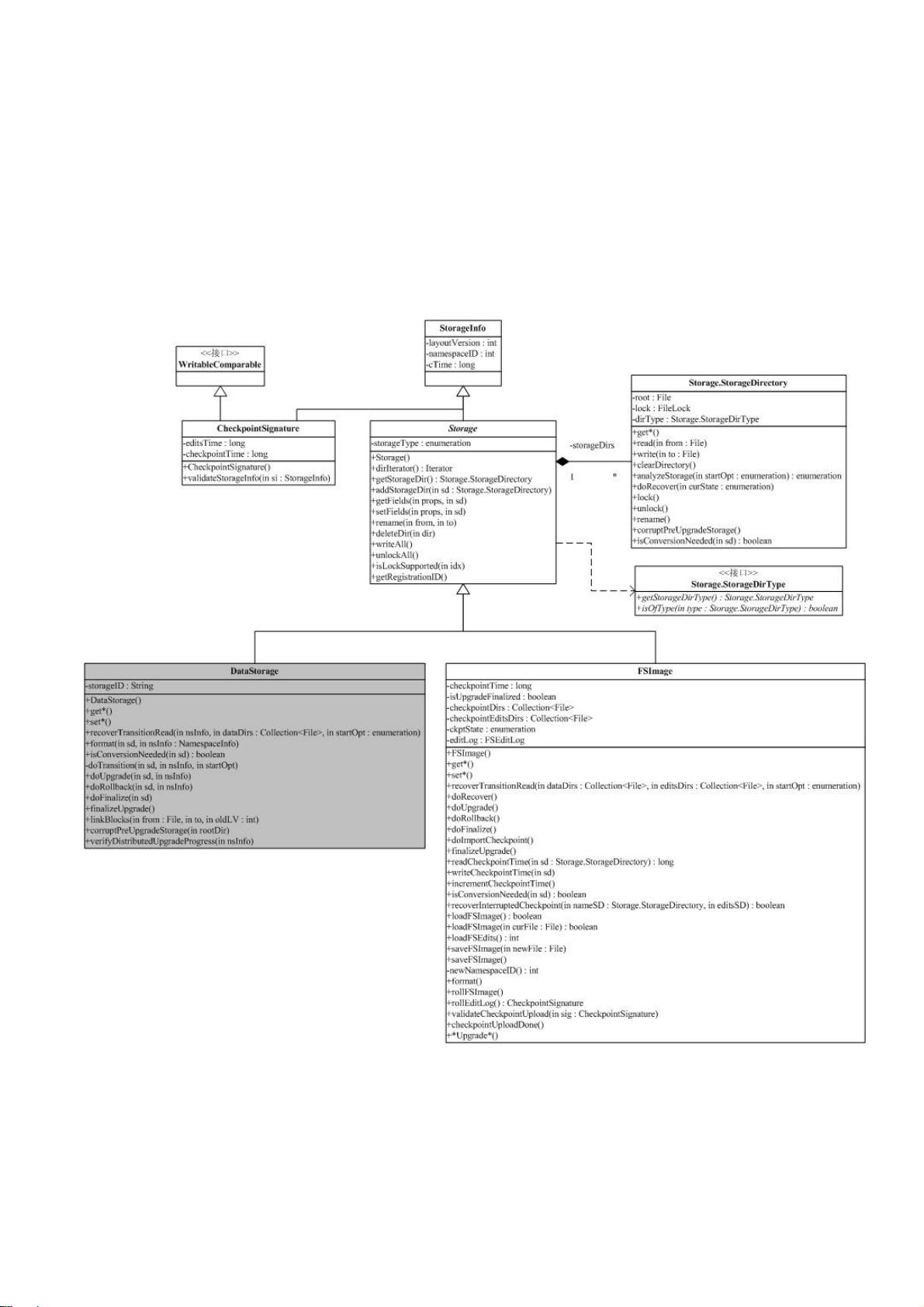
1. **NameNode**:作为元数据管理节点,NameNode负责存储文件系统的命名空间(文件和目录的树形结构)以及文件块到DataNode的映射信息。它维护的两个核心文件是`fsimage`(命名空间镜像)和`editlog`(操作日志)。
2. **DataNode**:DataNode是数据存储节点,它们存储实际的数据块,并负责向NameNode和客户端报告其状态,以及处理来自NameNode的块复制和删除指令。
3. **Secondary NameNode**:虽然不是必须的,但它是HDFS的一个辅助角色,用来定期合并NameNode的`fsimage`和`editlog`,以防止`editlog`变得过大,同时减轻NameNode的负担。
在Hadoop源代码分析中,我们关注的重点包括:
- **HDFS客户端**:客户端如何与NameNode交互以获取文件的位置信息,然后与DataNode通信来读写数据。客户端库实现了这些通信协议和逻辑。
- **NameNode的启动和状态管理**:理解NameNode如何加载和保存元数据,以及如何处理客户端请求。
- **Block Placement Policy**:研究HDFS如何决定新数据块的放置位置,以确保数据冗余和负载均衡。
- **MapReduce与HDFS的集成**:MapReduce框架如何利用HDFS进行数据分发和结果收集,尤其是在任务分配和数据局部性方面的优化。
- **故障检测和恢复机制**:当DataNode失败时,HDFS如何检测并恢复,以及NameNode如何处理心跳和块报告。
- **副本策略**:HDFS如何确保数据的高可用性,包括何时创建新的副本,以及如何处理过期或丢失的副本。
在分析Hadoop源代码时,应遵循以下步骤:
1. **了解基本架构**:首先,熟悉Hadoop的整体架构和组件,明确它们的功能和交互方式。
2. **阅读源码**:从高层次的接口开始,如客户端API,然后深入到内部实现,如NameNode和DataNode的处理逻辑。
3. **调试与实验**:通过修改源代码并运行测试实例,验证和理解代码的运行过程。
4. **学习设计决策**:理解为何选择特定的设计决策,以及这些决策如何影响系统的性能和可扩展性。
5. **查阅文档和博客**:结合已有的技术文章和官方文档,加深对Hadoop源代码的理解。
通过对Hadoop源代码的深入分析,我们可以获得对分布式计算和存储的深刻洞察,这对于开发、维护或优化Hadoop集群至关重要。同时,这也为研究和开发新的分布式系统提供了基础。

replication)
生成该块的元数据,BlockInfo 类型的对象。
DatanodeDescriptor
getDatanode(int index)
获得该块的第 index 个 Datanode 的信息,返回
DatanodeDescriptor 类型的对象
private int ensureCapacity(int
num)
private int getCapacity()
获的块的所有的副本个数,因为可能会增大副本个数
private int ensureCapacity(int
num)
多增加 num 个单元
上面的图,给出了类型是 object 的 triplets 数组,如果一个块设置的副本个数是 3,那么该块的 3 个相
应的元数据信息 BlockInfo 可以通过 triplets[index*3]来访问。
BlockInfo 类写得好像很怪异,不知道为什么这么写?应该很简单,用一个 list 结构保存块的所有的元数据
信息就可以了,好像在实现上用了一个内部的数组来实现链表的功能?
BlockMap 类
成员变量与方法 含义
private Map<Block, BlockInfo> map = new
HashMap<Block, BlockInfo>()
哈希表,key 是 block,value 是 BlockInfo,即块的元
数据。
类(从上到下依次继承) 用途 位置
DatanodeID 配置信息 org.apache.hadoop.hdfs.protocol 包下
DatanodeInfo 进一步,增加了一些动态信息 org.apache.hadoop.hdfs.protocol 包下
DatanodeDescriptor 再进一步,包含了 DataNode 上一
些 Block 的动态信息。
org.apache.hadoop.hdfs.server.namenode
包下
DatanodeDescriptor 类
保存指定 DataNode 的状态(如可用的存储空间大小、上次的更新时间等)、维护 DataNode 上的块。
内存中的数据结构,并不持久化到 fsImage 中,并且只在 NameNode 内部使用。
DatanodeDescriptor 类内部有两个内部类:BlockTargetPair 和 BlockQueue
BlockTargetPair 保存 Block 和对应 DatanodeDescriptor 的关联
成员变量 含义
public final Block block
public final DatanodeDescriptor[]
targets
BlockQueue 是 BlockTargetPair 队列。
private final Queue<BlockTargetPair> blockq = new LinkedList<BlockTargetPair>();
www.linuxidc.com
Linux公社(LinuxIDC.com) 是包括Ubuntu,Fedora,SUSE技术,最新IT资讯等Linux专业类网站。

剩余45页未读,继续阅读
2022-03-12 上传
2014-12-01 上传
2011-05-21 上传
107 浏览量
2024-11-22 上传
2024-11-22 上传
2024-11-22 上传

xq0804200134
- 粉丝: 0
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
