贝壳找房的千亿级实时计算平台:Flink与SparkStreaming的应用
11 浏览量
更新于2024-08-29
收藏 1.47MB PDF 举报
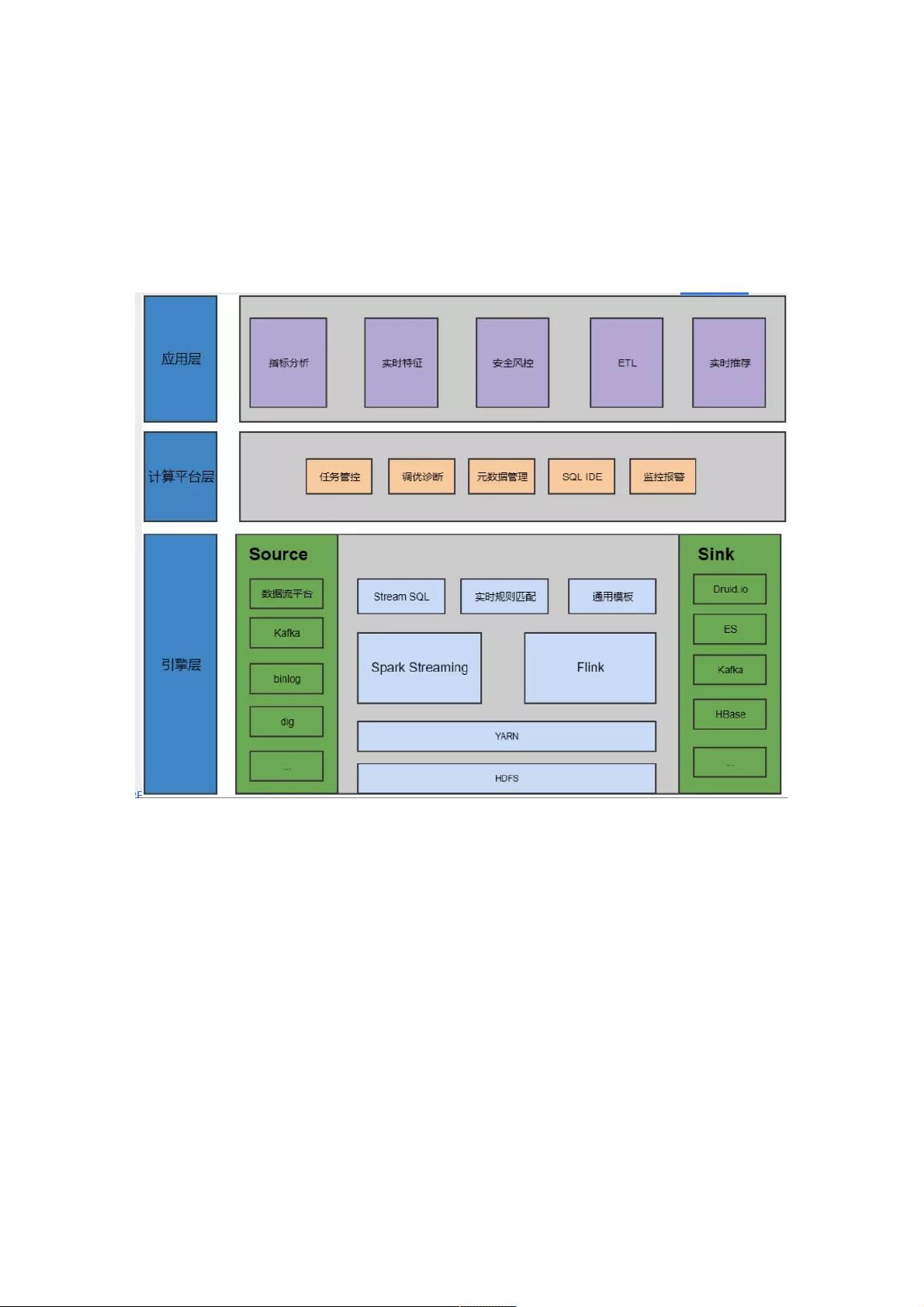
"贝壳找房使用SparkStreaming和Flink构建了强大的流式计算平台,应对日均千亿级消息的处理需求。平台集成了Kafka作为数据源,处理线上日志、埋点数据和业务数据。YARN作为资源调度器,支持Flink SQL和通用实时处理模板,输出结果可存储于ES、Kafka、Hbase等。平台提供了任务管理、资源调优、元数据管理和监控报警功能,支持业务场景如指标分析、实时特征、安全风控、ETL和实时推荐。Flink因其Exactly-Once一致性语义和丰富的窗口机制而被选中。"
在贝壳找房的技术实践中,实时计算引擎扮演了关键角色,尤其是在处理日均千亿级别的消息量时。这个平台的核心是构建了一个统一的流式计算环境,包括SparkStreaming和Flink两种广泛使用的实时计算框架。这样的平台化设计旨在降低业务部门的使用成本,减少运维和监控的复杂性。
平台采用Kafka作为主要的数据流来源,接收来自两千多个线上服务的日志数据,以及由前端埋点技术上报的经纪人和用户行为数据。此外,业务数据通过Kafka消息队列进行实时处理。使用YARN作为底层资源调度器,确保计算资源的有效分配和管理。
Flink作为平台的重点,因为它提供了Exactly-Once的一致性保证,确保了数据处理的准确性,同时其丰富的窗口机制适应了各种实时数据分析的需求。Flink还扩展了SQL能力,使得业务人员可以更方便地进行实时计算。平台还包含了一套完整的任务管理工具,如SQLIDE用于编写和调试SQL任务,以及监控报警系统,确保任务的稳定运行。
目前,这个计算平台在700多个YARN节点上运行着1000多个实时任务,每天处理的消息量达到千亿级别,高峰时单个任务的消息处理速率可达百万条/秒。这个平台不仅支持指标分析、实时特征提取、安全风控等业务应用,还涵盖了数据ETL和实时推荐等复杂任务,展示了大数据实时处理在房地产领域的强大应用能力。
抗住日均千亿级消息的实时计算引擎在贝壳的应用实践抗住日均千亿级消息的实时计算引擎在贝壳的应用实践
贝壳找房目前有1000多人的产品技术团队。从实时数据应用角度,公司内主要应用的实时数据,一个是线上的日志,大概有
两千多个线上的服务,每个服务又输出了很多的日志,日志数据是流式数据应用最多的。第二部分就是埋点,在 APP、web
端上报的经纪人作业情况和 C 端用户的行为,这部分通过前端的埋点技术上报。第三部分就是业务的数据,业务用 kafka 做
消息队列产生的实时数据。
流式计算平台
1、流式计算平台
平台目前主要建设 Spark Streaming、Flink 两种在实时计算中比较常见的计算引擎。平台化的背景就是早期如果公司内有业
务想用数据流进行计算,可能需要申请客户端,自己去搭建一个客户端,然后向集群上提交实时作业。这个产生的问题就是如
果每个业务方都去自己这样做成本比较高,每个业务都需要关心自己作业的运维问题,还有监控,实时数据作业的监控建设的
水平也是参差不齐。Spark Streaming、Flink 对于业务同学直接开发也有一定的学习成本,很难直接用上大数据的能力做实时
计算。
我们计算平台流数据源主要都是用 Kafka。Kafka 数据中数据分为几类,一个是数据流,数据流指的是线上的业务日志、访问
日志等,会收集到数据流平台。Binlog 是线上 MySQL、TIDB 产生的 binlog 作为实时数据源。Dig 是内部前端埋点项目的代
号。
计算平台底层集群使用 YARN 做资源调度。再上层就是我们现在主要基于社区版 Flink、扩展了开源 Flink 的 SQL 能力。还有
提供一些通用的实时处理模板。流计算的输出要覆盖线上业务所有需要的存储分析引擎,例如 ES、Kafka、Hbase 等等。
在这些底层基础之上,首先要做的就是实时任务的管理管控,包括如何帮助平台上这些所有 Flink 或者 Spark 任务,进行资源
的调优,对实时数据流中的数据的元数据化。另外还有在 Web 端提供的 SQL IDE、任务运行状态的监控报警。在计算平台之
上业务方做的一些应用:指标分析、实时特征、安全风控、ETL、实时推荐等等。
2、目前现状
目前 YARN 平台大概有七百多个节点,一千多个实时任务,每天的消息量千亿级,高峰单个任务消息量百万条/s。
3、为什么要选择Flink
下载后可阅读完整内容,剩余9页未读,立即下载
146 浏览量
171 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38565628
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- AVR单片机C语言编程实战教程
- MATLAB实现π/4-QDPSK调制解调技术解析
- Rust开发微控制器USB设备端实验性框架介绍
- Report Builder 12.03汉化文件使用指南
- RG100E-AA U盘启动配置文件设置指南
- ASP客户关系管理系统的联系人报表功能解析
- DSPACK2.34:Delphi7控件的测试与应用
- Maven Web工程模板 nb-parent 评测
- ld-navigation:革新Web路由的数据驱动导航组件
- Helvetica Neue字体全系列免费下载指南
- stylelint插件:强化CSS属性值规则,提升代码规范性
- 掌握HTML5 & CSS3设计与开发的关键英文指南
- 开发仿Siri中文语音助理的Android源码解析
- Excel期末考试复习与习题集
- React自定义元素工具支持增强:react-ce-ubigeo示例
- MATLAB实现FIR数字滤波器程序及MFC界面应用
