
Zookeeper原理原理
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实
现同步服务,配置维护和命名服务等。Zookeeper是hadoop的一个子项目,其发展历程无需赘述。在分布式应用中,由于工
程师不能很好地使用锁机制,以及基于消息的协调机制不适合在某些应用中使用,因此需要有一种可靠的、可扩展的、分布式
的、可配置的协调机制来统一系统的状态。Zookeeper的目的就在于此。本文简单分析zookeeper的工作原理,对于如何使用
zookeeper不是本文讨论的重点。
1 Zookeeper的基本概念
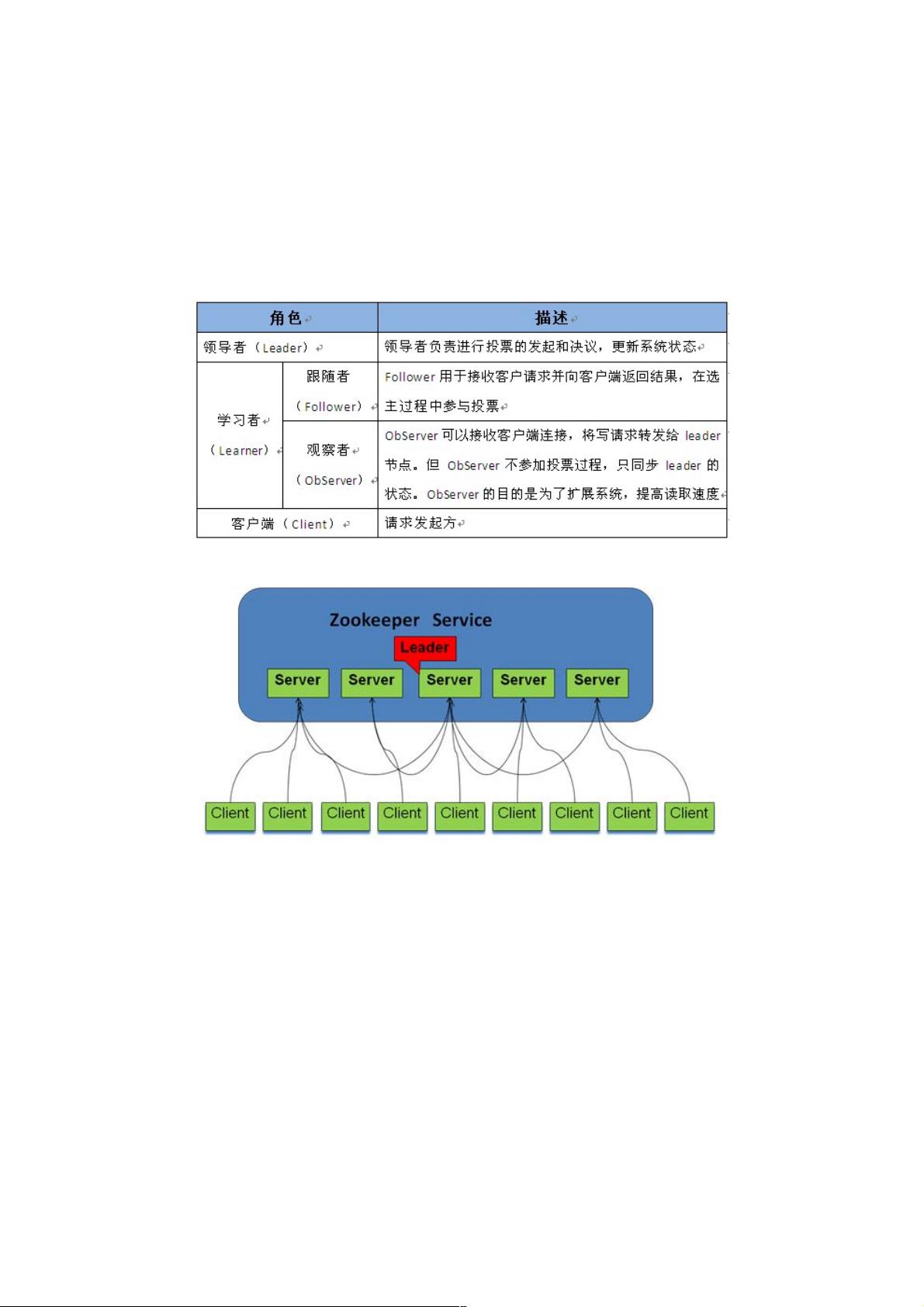
1.1 角色
Zookeeper中的角色主要有以下三类,如下表所示:
系统模型如图所示:
1.2 设计目的
1.最终一致性:client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。
2 .可靠性:具有简单、健壮、良好的性能,如果消息m被到一台服务器接受,那么它将被所有的服务器接受。
3 .实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时
等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
4 .等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
5.原子性:更新只能成功或者失败,没有中间状态。
6 .顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将
在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
2 ZooKeeper的工作原理
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种
模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导
者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相
同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时
下载后可阅读完整内容,剩余6页未读,立即下载

weixin_38538312
- 粉丝: 11
- 资源: 927
 我的内容管理
展开
我的内容管理
展开







最新资源
- Flex垃圾回收与内存管理:防止内存泄露
- Python编程规范与最佳实践
- EJB3入门:实战教程与核心概念详解
- Python指南v2.6简体中文版——入门教程
- ANSYS单元类型详解:从Link1到Link11
- 深度解析C语言特性与实践应用
- Gentoo Linux安装与使用全面指南
- 牛津词典txt版:信息技术领域的便捷电子书
- VC++基础教程:从入门到精通
- CTO与程序员职业规划:能力提升与路径指南
- Google开放手机联盟与Android开发教程
- 探索Android触屏界面开发:从入门到设计原则
- Ajax实战:从理论到实践
- 探索Android应用开发:从入门到精通
- LM317T稳压管详解:1.5A可调输出,过载保护
- C语言实现SOCKET文件传输简单教程
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


