C#实现网络爬虫详解
188 浏览量
更新于2024-09-02
收藏 118KB PDF 举报
"C# 实现网络爬虫的详细步骤及HTTP请求响应的处理"
网络爬虫是一种自动遍历和抓取互联网信息的程序,对于数据分析、搜索引擎优化等场景具有重要作用。在C#中实现网络爬虫,我们可以充分利用.NET框架提供的强大功能。下面将详细介绍C#实现网络爬虫的关键步骤。
1. **初始化URL集合**
- 首先,我们需要确定起始URL,并创建两个集合:一个用于存储待下载的URL(待下载集合),另一个用于记录已下载的URL(已下载集合)。通常使用Dictionary数据结构,键为URL字符串,值为URL的深度信息。
2. **HTTP请求与响应**
- 在C#中,`System.Net`命名空间提供了`HttpWebRequest`和`HttpWebResponse`类,用于发送HTTP请求和接收响应。例如,我们可以通过`HttpWebRequest.Create(url)`创建一个请求对象,然后设置请求头、超时时间等属性,最后通过`GetResponse()`方法获取响应。
3. **异步请求与并发下载**
- 为了提高爬虫的效率,可以使用异步请求和并发下载。C#中的异步编程模型(如`async/await`关键字)可以轻松实现这一点。创建一定数量的工作实例,每个实例负责一个请求,当一个实例完成请求后,将其标记为可用,并调度新的任务。
4. **控制并发数量**
- 通过一个布尔数组 `_reqsBusy` 来跟踪每个工作实例的状态,以及一个变量 `_reqCount` 记录工作实例的数量。在`DispatchWork`函数中,检查并分配任务给空闲的工作实例,确保并发数量在可控制范围内。
5. **发送HTTP请求**
- 发送请求通常涉及以下步骤:
- 创建`HttpWebRequest`对象并设置属性(如Method, ContentType, UserAgent等)。
- 如果需要,设置CookieContainer以处理登录和其他会话信息。
- 使用`GetRequestStream()`写入请求体(如POST数据)。
- 调用`GetResponse()`获取响应。
- 读取`HttpWebResponse`的响应流,如HTML内容或下载的文件。
6. **解析HTML内容**
- 从响应流中获取HTML后,需要解析HTML以提取所需信息。可以使用HTML解析库,如HtmlAgilityPack,它允许我们通过XPath或CSS选择器轻松地找到和提取元素。
7. **处理链接**
- 在解析的HTML中查找新的链接,将它们添加到待下载集合中,并更新其深度。同时检查链接是否已存在于已下载集合中,以避免重复下载。
8. **循环下载**
- 检查待下载集合,如果非空,则取出第一个URL进行下载和解析,然后将其移动到已下载集合。持续这个过程,直到待下载集合为空。
9. **异常处理与中断**
- 爬虫应包含适当的异常处理机制,以处理网络错误、超时等问题。此外,提供一个中断标志(如`_stop`),以便在需要时停止爬虫。
10. **存储和管理数据**
- 抓取的数据可能需要存储在文件、数据库或其他持久化存储中。确保正确处理重复数据,考虑使用去重策略。
以上就是C#实现网络爬虫的基本流程,实际应用中还可能涉及到IP代理、验证码识别、JavaScript执行等复杂问题。了解并熟练掌握这些知识点,将有助于构建更高效、更健壮的网络爬虫。
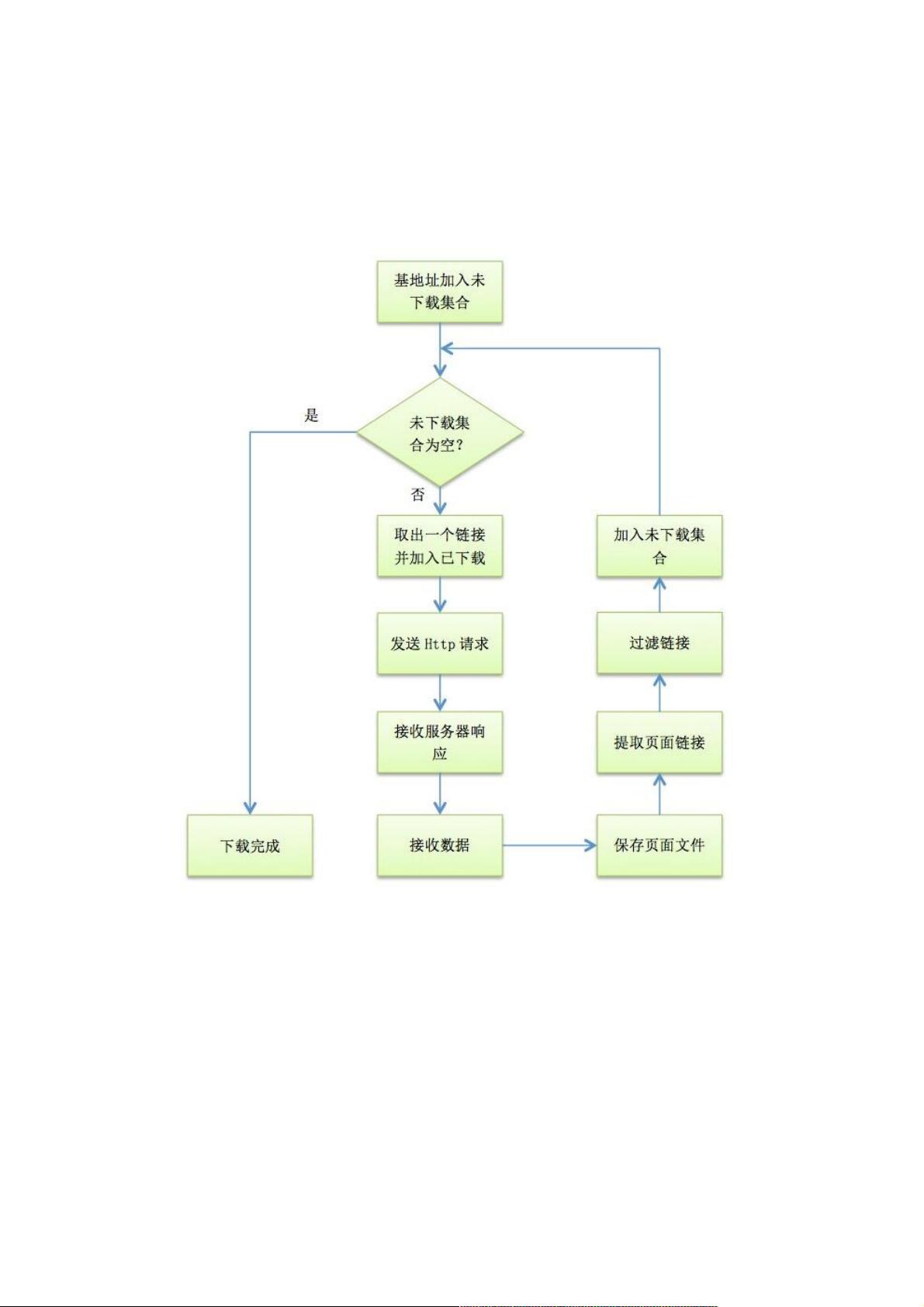
利用利用C#实现网络爬虫实现网络爬虫
主要介绍了利用C#实现网络爬虫,完整的介绍了C#实现网络爬虫详细过程,感兴趣的小伙伴们可以参考一下
网络爬虫在信息检索与处理中有很大的作用,是收集网络信息的重要工具。
接下来就介绍一下爬虫的简单实现。
爬虫的工作流程如下
爬虫自指定的URL地址开始下载网络资源,直到该地址和所有子地址的指定资源都下载完毕为止。
下面开始逐步分析爬虫的实现。
1. 待下载集合与已下载集合待下载集合与已下载集合
为了保存需要下载的URL,同时防止重复下载,我们需要分别用了两个集合来存放将要下载的URL和已经下载的URL。
因为在保存URL的同时需要保存与URL相关的一些其他信息,如深度,所以这里我采用了Dictionary来存放这些URL。
具体类型是Dictionary<string, int> 其中string是Url字符串,int是该Url相对于基URL的深度。
每次开始时都检查未下载的集合,如果已经为空,说明已经下载完毕;如果还有URL,那么就取出第一个URL加入到已下载的
集合中,并且下载这个URL的资源。
2. HTTP请求和响应请求和响应
C#已经有封装好的HTTP请求和响应的类HttpWebRequest和HttpWebResponse,所以实现起来方便不少。
为了提高下载的效率,我们可以用多个请求并发的方式同时下载多个URL的资源,一种简单的做法是采用异步请求的方法。
下载后可阅读完整内容,剩余6页未读,立即下载
2011-01-05 上传
2018-03-06 上传
109 浏览量
2023-05-30 上传
2024-11-01 上传
2023-06-06 上传
2024-11-07 上传
2024-10-31 上传
2023-09-08 上传

weixin_38640794
- 粉丝: 4
- 资源: 942
 我的内容管理
展开
我的内容管理
展开







