通用网络爬虫详解:架构、策略与工作流程
需积分: 50 125 浏览量
更新于2024-09-03
收藏 683KB PDF 举报
通用网络爬虫综述深入探讨了现代网络信息获取的重要工具——爬虫。网络爬虫是一种程序,能够遵循一定的规则,有组织地从互联网上抓取URL链接和页面内容,主要用于搜索引擎的数据源,但随着数据量的增长,也被广泛应用于各种专业领域,如金融、信贷、基金和社交媒体信息获取。
爬虫的核心工作流程包括:首先设定种子URL集合,然后将其加入待爬取队列;接着从队列中取出URL,获取网页内容并保存,解析网页以发现新的URL;这个过程会持续进行,直到满足停止条件,如队列为空。整体架构上,网络爬虫可分为集中式和分布式。集中式适合小型任务,但由于资源限制,对于大规模的通用爬虫,分布式架构更优,它能实现任务的高效分发和爬取器的协同工作。
分布式爬虫设计的关键在于任务管理和页面爬取的分离。在主从式架构中,有一个中央控制器节点管理所有运行的爬虫,负责URL排序、任务分配和节点间的通信。此外,还有增量爬取和系统稳定性控制等功能,确保爬虫能持续、稳定地执行任务。其他可能的分布式架构类型还包括基于消息队列的架构,以及P2P(点对点)网络结构,它们各自有其优缺点,适用于不同的应用场景和需求。
在技术细节上,通用爬虫涉及多种关键技术,例如高效的URL筛选和排序算法以减少重复抓取,网页去重策略防止重复资源占用带宽,以及应对动态网页的抓取策略,如使用Selenium等工具模拟用户行为。同时,还需要考虑如何对抗网站的反爬虫机制,如设置User-Agent、处理验证码等,以保持爬虫的合规性和有效性。
通用网络爬虫作为一种强大的信息采集工具,不仅要求开发者具备编程技能(如Python),还需深入理解网络协议、数据结构、算法优化以及如何适应不断变化的互联网环境。随着数据科学和人工智能的发展,爬虫技术将在数据分析、知识挖掘等领域发挥更大的作用。
1
通用网络爬虫综述
一、 引言
网络爬虫(Web Crawler/Spider/Robot)是一种根据一定规则、有条理地自动从网
络上获取 URL 链接与网页内容的程序或软件。通常要先给定一个特定的种子 URL 集合,
爬虫程序从种子 URL 集合中的链接出发,不断获取新的 URL 链接和页面内容,并将新
的 URL 储存到待爬取的 URL 队列中,直至满足某些特定条件时(比如待爬取 URL 队列
为空),爬虫终止运行。
[1][2][6]
爬虫不仅是搜索引擎的信息获取渠道,随着互联网的发展以及相应的网络数据量的
极大增加,爬虫也成为了各种专门用途的信息与数据获取的有力工具,如金融信贷信息、
基金信息甚至网络社区信息等
[3][4][5]
。而网络爬虫根据其功能用途和目的可以划分为通用
爬虫和主题爬虫(或聚焦爬虫),前者面向整个互联网的网页进行爬取,后者面向互联
网中特定的网页进行爬取
[2]
。
通用爬虫所涉及的技术主要有爬虫的整体架构、URL 筛选算法、URL 排序算法、网
页去重算法、网页更新策略、动态网页解析以及对于网页防抓取策略的对策等。
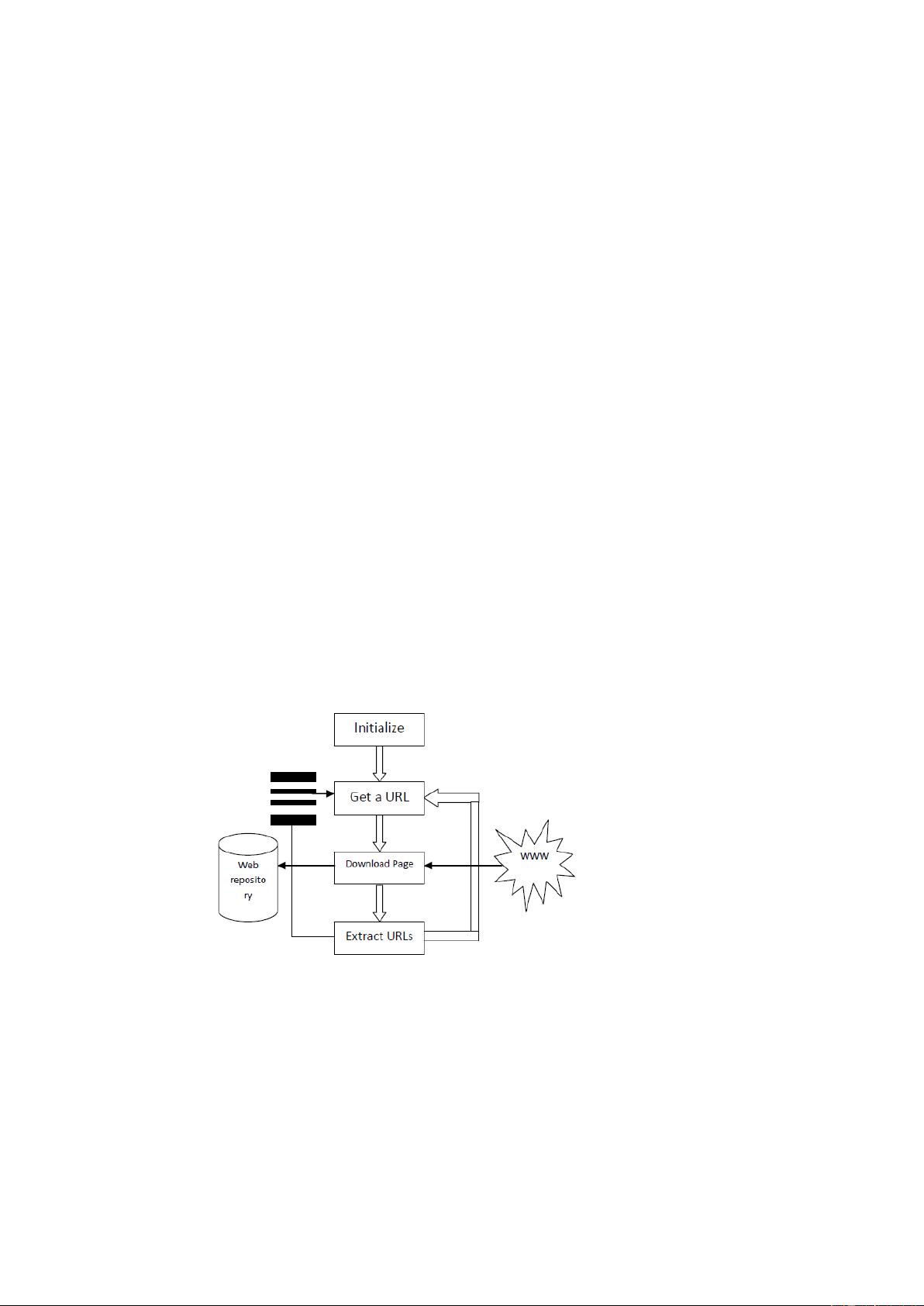
通用爬虫的工作流程可以分为以下几个阶段
[1]
:
1) 选定一个初始的种子 URL 集合;
2) 将 URL 集合加入待爬取队列;
3) 从待爬取队列中取出 URL;
4) 获取 3)中 URL 对应的网页内容并保存;
5) 解析 4)中的网页获取新的 URL 集合;
6) 回到 2)循环执行直至满足循环终止条件。
图示如下:
Figure 1-爬虫工作流程
二、 爬虫整体架构
爬虫的整体架构可以分为集中式和分布式。集中式是指由单一主机执行爬取任务,
这种架构中,由于单一主机的性能与计算资源的限制,比较适合执行任务量较小的爬取
任务,如面向某一主题的网页抓取。而通用爬虫的任务量通常很大,集中式的架构不能
满足效率和时间的要求,所以常常考虑分布式的架构。在分布式爬虫的设计中,需要实
现两个基本功能:爬取任务的分发和具体页面的爬取。按照控制器和爬取器之间通信方
下载后可阅读完整内容,剩余8页未读,立即下载
2021-11-08 上传
2023-09-07 上传
2023-10-15 上传
2023-11-21 上传
2023-05-17 上传
2023-05-17 上传
2023-12-23 上传
2023-06-08 上传
2023-05-31 上传

DataWizard~
- 粉丝: 2666
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- ASP.NET数据库高级操作:SQLHelper与数据源控件
- Windows98/2000驱动程序开发指南
- FreeMarker入门到精通教程
- 1800mm冷轧机板形控制性能仿真分析
- 经验模式分解:非平稳信号处理的新突破
- Spring框架3.0官方参考文档:依赖注入与核心模块解析
- 电阻器与电位器详解:类型、命名与应用
- Office技巧大揭秘:Word、Excel、PPT高效操作
- TCS3200D: 可编程色彩光频转换器解析
- 基于TCS230的精准便携式调色仪系统设计详解
- WiMAX与LTE:谁将引领移动宽带互联网?
- SAS-2.1规范草案:串行连接SCSI技术标准
- C#编程学习:手机电子书TXT版
- SQL全效操作指南:数据、控制与程序化
- 单片机复位电路设计与电源干扰处理
- CS5460A单相功率电能芯片:原理、应用与精度分析
