ADMM优化与Apache Spark的大规模机器学习
需积分: 5 23 浏览量
更新于2024-08-03
1
收藏 292KB PDF 举报
"这篇文档是阿里云相关的技术研究,由Sauptik Dhar和Mohak Shah在2017年5月21日发布,主要探讨了基于ADMM(交替方向乘子法)的可扩展机器学习在Apache Spark平台上的应用。文档中提到了大数据、Spark的现状以及当前机器学习库面临的挑战,并对比了ADMM与其他优化算法的优缺点。"
本文档深入讨论了如何利用ADMM(交替方向乘子法)在Apache Spark上实现大规模机器学习的可扩展性。ADMM是一种优化方法,特别适用于解决大型问题,它能够将复杂的问题分解为更简单的子问题,从而在分布式计算环境中高效地处理数据。与传统的梯度下降法(SGD)相比,ADMM在收敛性上有优势,其收敛不那么依赖于步长选择,并且对病态条件下的问题更具鲁棒性。而梯度下降法的收敛速度可能受到步长和问题条件性的影响。
当前的机器学习库,如Spark的MLlib和其他ML包,通常采用SGD或L-BFGS等优化算法。SGD在处理大规模数据时速度快,但其收敛性能受步长选择和数据条件性影响。L-BFGS虽然能适应非光滑函数,但在实现上较为复杂。相比之下,ADMM提供了保证的收敛性和对步长选择的鲁棒性,使其成为处理大规模机器学习任务的理想选择。
文档还提到了大数据和Spark的现状,暗示了在物联网(IoT)和大数据结合的背景下,如何有效地处理和分析数据成为了关键挑战。Apache Spark作为一个快速、通用的大数据处理框架,适合用于机器学习和其他数据分析任务,但其原生的优化算法可能无法满足所有复杂场景的需求,因此ADMM的引入为Spark提供了一个强大的工具,以应对不断增长的数据量和复杂性。
总结来说,这份资料揭示了在阿里云平台上,通过ADMM算法来提升Apache Spark上的机器学习效率和稳定性,这为大规模机器学习提供了新的解决方案,并展示了在大数据时代下,优化算法的重要性以及其对提升数据处理能力的潜在贡献。
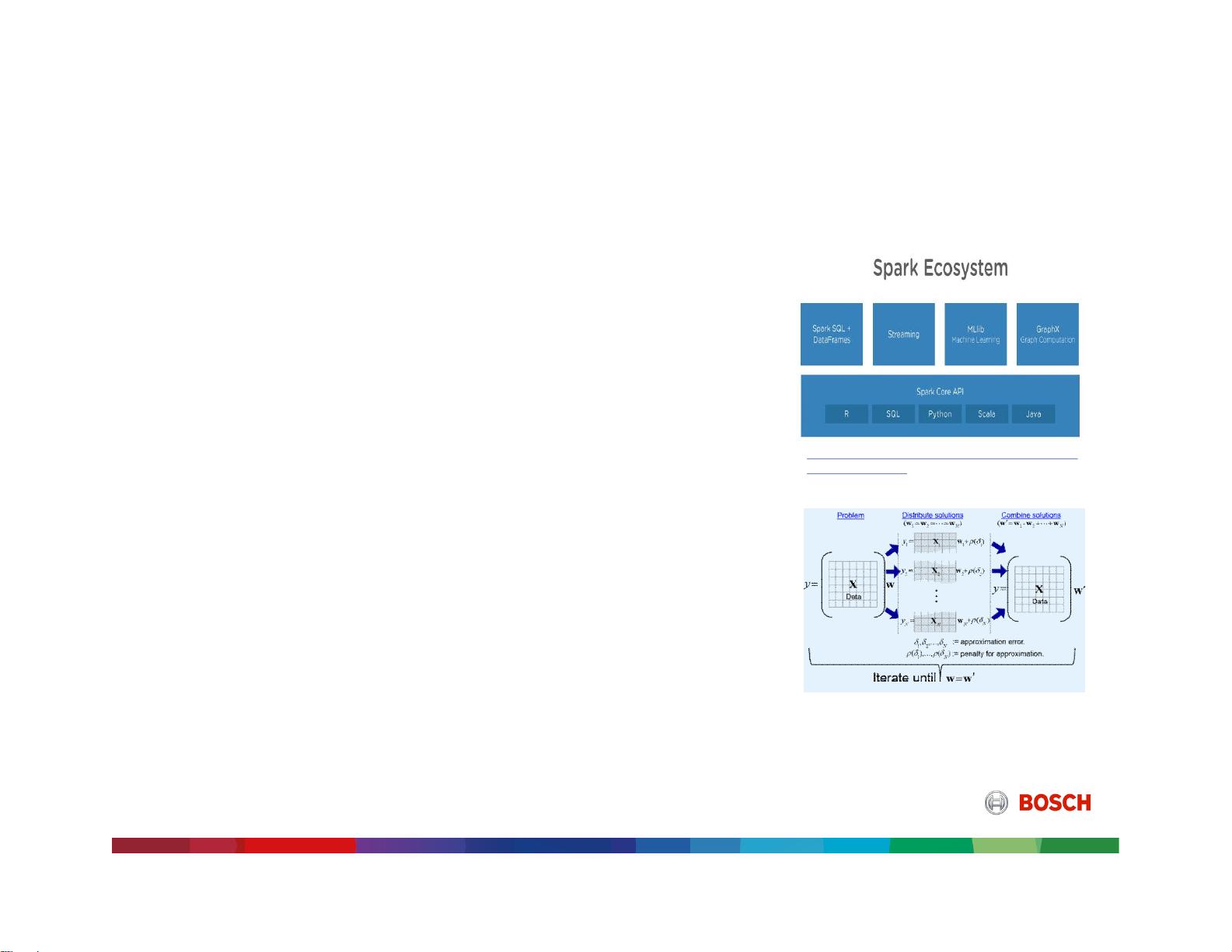
Big data, Spark and Status-quo
Research and Technology Center North America | Sauptik Dhar, Mohak Shah | 5/21/2017
© 2017 Robert Bosch LLC and affiliates. All rights reserved.
3
Challenges
Learning (Convex) Optimization
Current solutions (MLLib/ML packages) adopt
‒ SGD: convergence dependent on step-size, conditionality
‒ LBFGS: Adapting to non-differentiable functions non-trivial
ADMM (Alternating Direction Method of Multipliers)
Large problem (simpler) sub-problems
Guaranteed convergence and robustness to step-size selection
Robust to ill-conditioned problems
https://www.simplilearn.com/apache-spark-guide-
for-newbies-article
剩余13页未读,继续阅读
2023-05-05 上传
198 浏览量
2023-08-25 上传
2020-12-01 上传
2021-10-03 上传
2022-07-14 上传
2021-05-28 上传
2021-05-26 上传
2022-07-14 上传

weixin_40191861_zj
- 粉丝: 83
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- NIST REFPROP问题反馈与解决方案存储库
- 掌握LeetCode习题的系统开源答案
- ctop:实现汉字按首字母拼音分类排序的PHP工具
- 微信小程序课程学习——投资融资类产品说明
- Matlab犯罪模拟器开发:探索《当蛮力失败》犯罪惩罚模型
- Java网上招聘系统实战项目源码及部署教程
- OneSky APIPHP5库:PHP5.1及以上版本的API集成
- 实时监控MySQL导入进度的bash脚本技巧
- 使用MATLAB开发交流电压脉冲生成控制系统
- ESP32安全OTA更新:原生API与WebSocket加密传输
- Sonic-Sharp: 基于《刺猬索尼克》的开源C#游戏引擎
- Java文章发布系统源码及部署教程
- CQUPT Python课程代码资源完整分享
- 易语言实现获取目录尺寸的Scripting.FileSystemObject对象方法
- Excel宾果卡生成器:自定义和打印多张卡片
- 使用HALCON实现图像二维码自动读取与解码
