Flume数据采集详解:高可用日志收集系统
需积分: 10 198 浏览量
更新于2024-07-16
收藏 2.91MB PPTX 举报
"这篇flume学习笔记主要涵盖了2019年9月更新的内容,包括Flume的安装、监控文件和目录数据的保存,以及Flume的启动脚本。"
Flume是大数据领域中用于数据采集的重要工具,由Cloudera开发并已归入Apache项目。它是一个高可用、高可靠且分布式的系统,专门用于收集、聚合和传输海量日志数据。Flume具有灵活性,可以定制多种数据发送方来收集数据,并具备基本的数据处理能力,将处理后的数据写入各种接收方。
Flume的发展历程分为Flume-OG和Flume-NG两个阶段。Flume-OG自2010年11月开源以来,因其功能逐渐完善而受到广泛应用。然而,随着功能的增加,其代码工程变得复杂,核心组件设计和配置存在不足,特别是0.94.0版本中出现了日志传输不稳定的问题。因此,Cloudera在2011年10月对Flume进行了重构,形成了Flume-NG,解决了原有问题,增强了系统的稳定性和可扩展性。
Flume的核心组件主要包括以下几个部分:
1. Events:是Flume处理的基本单元,包含了实际的日志数据(通常以字节数组形式),并附带有头部信息,可以是日志记录或其他Avro对象。
2. Agent:是Flume运行的基本实体,它在Java虚拟机中作为一个独立进程存在,由Source、Channel和Sink三个组件构成。
3. Client:在独立的线程中运行,负责生成数据并将其发送给Agent。
4. Source:源组件,负责消费传入的Event,从Client那里收集数据,并将数据送入Channel。
5. Channel:作为数据的临时存储,它在Source和Sink之间起到缓冲作用,类似于消息队列,确保数据在传输过程中的安全。
6. Sink:从Channel中获取数据,运行在独立线程,负责将数据持久化或转发到其他Source。
每个Flume Agent可以单独工作,也可以通过配置形成复杂的拓扑结构,实现数据的多级处理和传输。例如,一个Agent的Sink可以将数据发送到另一个Agent的Source,构建起多Agent的级联,从而扩大数据处理的范围和复杂性。
Flume的监控文件和目录数据的功能,使得它能够实时跟踪和收集指定位置的变化,如日志文件的新增或修改,进一步增强了其在大数据环境中的实用性。启动脚本则帮助用户便捷地管理和控制Flume服务的启动、停止和状态检查。
Flume作为一个强大的数据采集工具,不仅简化了日志数据的收集过程,还提供了灵活的数据处理和传输机制,对于大数据分析和日志管理具有重要作用。通过不断优化和升级,Flume已经成为企业级日志管理和分析系统中的首选工具之一。
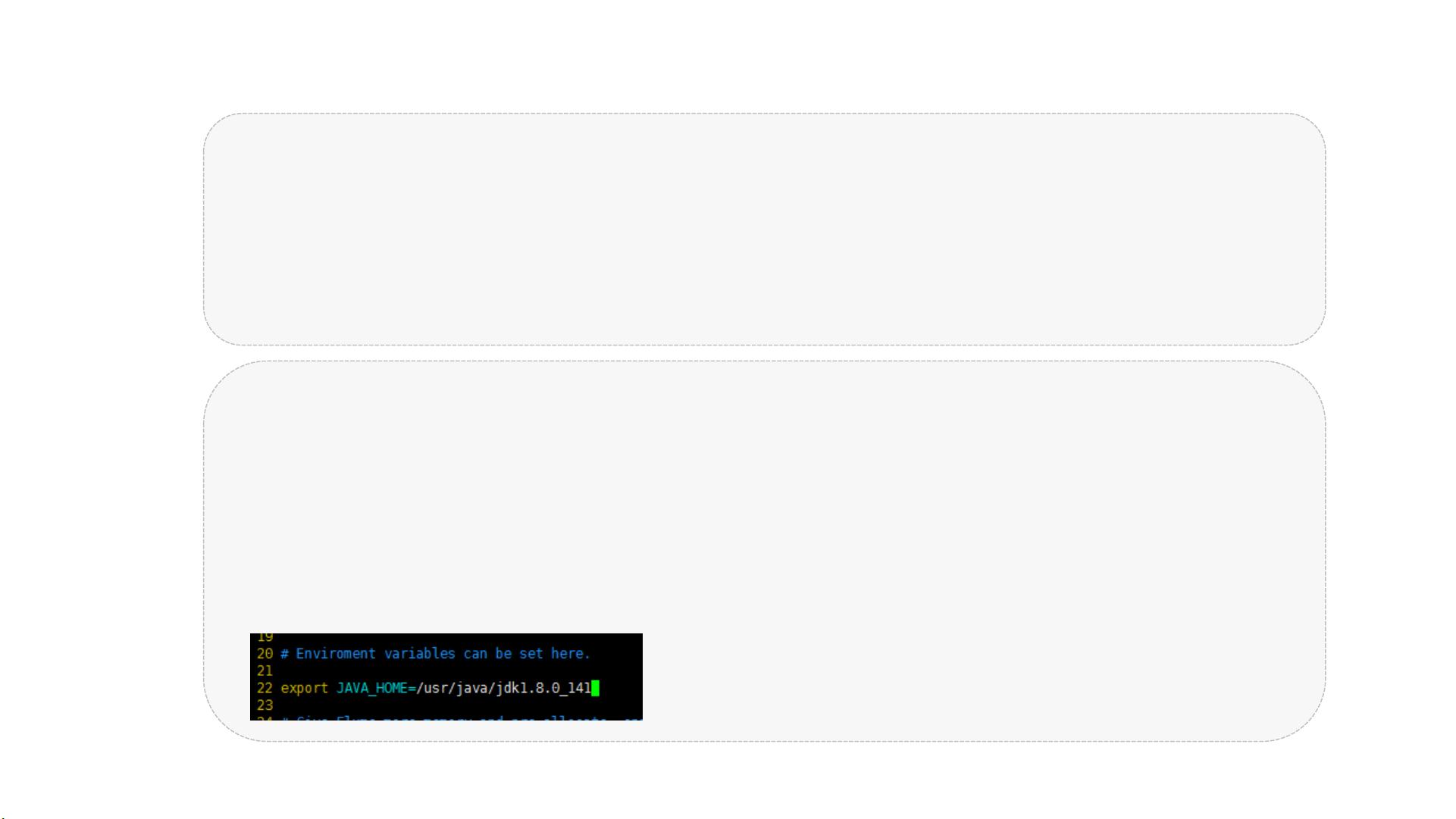
可以在 2 1" 下下载完成,通过 34 上传至指定目录下,也可以在图片上箭头指向的版本,
点击“右键”,复制链接地址,在指定目录下通过 1 安装
56""78/.
56"/78"
/9: ;
56"/78;34/9: ;
修改 /" 文件
56"/78/9: .4.
56"478"
/4 "/"/"< "
8 提供了一个模版文件 # 我们 = 出来一个 /"
56"478/"/"
修改
/"
将其中的
剩余26页未读,继续阅读
2022-05-08 上传
2019-11-07 上传
2022-12-23 上传
2021-12-18 上传
2021-10-14 上传
2022-12-23 上传
2022-12-23 上传
2022-12-23 上传









