稀疏表示提升面部识别鲁棒性:对抗变化与遮挡
在最新的研究中,"Robust Face Recognition via Sparse Representation"(鲁棒人脸识别通过稀疏表示)由John Wright、Allen Y. Yang、Arvind Ganesh、S. Shankar Sastry和Yi Ma等专家提出,他们针对人脸识别领域提出了一个革命性的方法。该论文关注的是如何在复杂的环境下自动识别人脸,包括面部表情变化、光照条件变化、遮挡以及伪装等问题。他们将人脸识别问题重新定义为多线性回归模型分类,并强调了稀疏信号表示理论在解决这一问题中的关键作用。
论文的核心观点是利用L1最小化技术来计算稀疏表示,从而设计出一种通用的图像对象识别算法。这种新框架对人脸识别中的两个关键问题提供了新的见解:特征提取和遮挡鲁棒性。作者指出,与传统方法不同,如果能够有效利用稀疏性,特征选择的重要性就会减弱。真正关键的是特征数量是否足够大,以及稀疏表示是否被准确地计算出来。
在特征提取方面,稀疏表示的优势在于,即使在特征选择不那么严格的情况下,通过寻找数据中最少的非零元素,依然能捕捉到关键信息。这使得系统能够更好地适应各种输入,提高识别的稳定性和准确性。同时,对于遮挡问题,稀疏表示能够提供一种内在的抗干扰能力,因为较少的非零元素意味着对缺失或部分信息的容忍度更高。
此外,论文可能还探讨了如何优化稀疏编码过程,例如使用高效的算法如ISTA(Iterative Shrinkage-Thresholding Algorithm)或FISTA(Fast Iterative Shrinkage-Thresholding Algorithm),以确保在实际应用中达到高效且精确的识别效果。通过实验验证,这种基于稀疏表示的算法在训练样本相对较少的情况下也能展现出优秀的识别性能,证明了其在实际人脸识别系统的潜力和价值。
"Robust Face Recognition via Sparse Representation"不仅提升了人脸识别的准确度,还革新了我们对特征提取和鲁棒性处理的理解,为处理复杂环境下的人脸识别任务开辟了新的研究方向。在未来的研究和实际应用中,这种稀疏表示的方法有望进一步推动人脸检测、识别技术的发展,尤其是在资源有限或者实时性要求高的场景下。
As the entries of the vector xx
0
encode the identity of the
test sample yy, it is tempting to attempt to obtain it by
solving the linear system of equations yy ¼ Axx. Notice,
though, that using the entire training set to solve for xx
represents a significant departure from one sample or one
class at a time methods such as NN and NS. We will later
argue that one can obtain a more discriminative classifier
from such a global representation. We will demonstrate its
superiority over these local methods (NN or NS) both for
identifying objects represented in the training set and for
rejecting outlying samples that do not arise from any of the
classes present in the training set. These advantages can
come without an increase in the order of growth of the
computation: As we will see, the complexity remains linear
in the size of training set.
Obviously, if m>n, the system of equations yy ¼ Axx is
overdetermined, and the correct xx
0
can usually be found as
its unique solution. We will see in Section 3, however, that
in robust face recognition, the system yy ¼ Axx is typically
underdetermined, and so, its solu tion is not unique.
6
Conventionally, this difficulty is resolved by choosing the
minimum ‘
2
-norm solution:
ð‘
2
Þ :
^
xx
2
¼ arg min kxxk
2
subject to Axx ¼ yy: ð4Þ
While this optimization problem can be easily solved (via
the pseudoinverse of A), the solution
^
xx
2
is not especially
informative for recognizing the test sample yy. As shown in
Example 1, ^xx
2
is generally dense, with large nonzero entries
corresponding to training samples from many different
classes. To resolve this difficulty, we instead exploit the
following simple observation: A valid test sample yy can be
sufficiently represented using only the training samples
from the same class. This representation is naturally sparse if
the number of object classes k is reasonably large. For
instance, if k ¼ 20, only 5 percent of the entries of the
desired xx
0
should be nonzero. The more sparse the
recovered xx
0
is, the easier will it be to accurately determine
the identity of the test sample yy.
7
This motivates us to seek the sparsest solution to yy ¼ Axx,
solving the following optimization problem:
ð‘
0
Þ :
^
xx
0
¼ arg min kxxk
0
subject to Axx ¼ yy; ð5Þ
where kk
0
denotes the ‘
0
-norm, which counts the number
of nonzero entries in a vector. In fact, if the columns of A are
in general position, then whenever yy ¼ Axx for some xx with
less than m=2 nonzeros, xx is the unique sparsest solution:
^
xx
0
¼ xx [33]. However, the problem of finding the sparsest
solution of an underdetermined system of linear equations is
NP-hard and difficult even to approximate [13]: that is, in the
general case, no known procedure for finding the sparsest
solution is significantly more efficient than exhausting all
subsets of the entries for xx.
2.2 Sparse Solution via ‘
1
-Minimization
Recent development in the emerging theory of sparse
representation and compressed sensing [9], [10], [11] reveals
that if the solution xx
0
sought is sparse enough, the solution of
the ‘
0
-minimization problem (5) is equal to the solution to
the following ‘
1
-minimization problem:
ð‘
1
Þ :
^
xx
1
¼ arg min kxxk
1
subject to Axx ¼ yy: ð6Þ
This problem can be solved in polynomial time by standard
linear programming methods [34]. Even more efficient
methods are available when the solution is known to be
very sparse. For example, homotopy algorithms recover
solutions with t nonzeros in Oðt
3
þ nÞ time, linear in the size
of the training set [35].
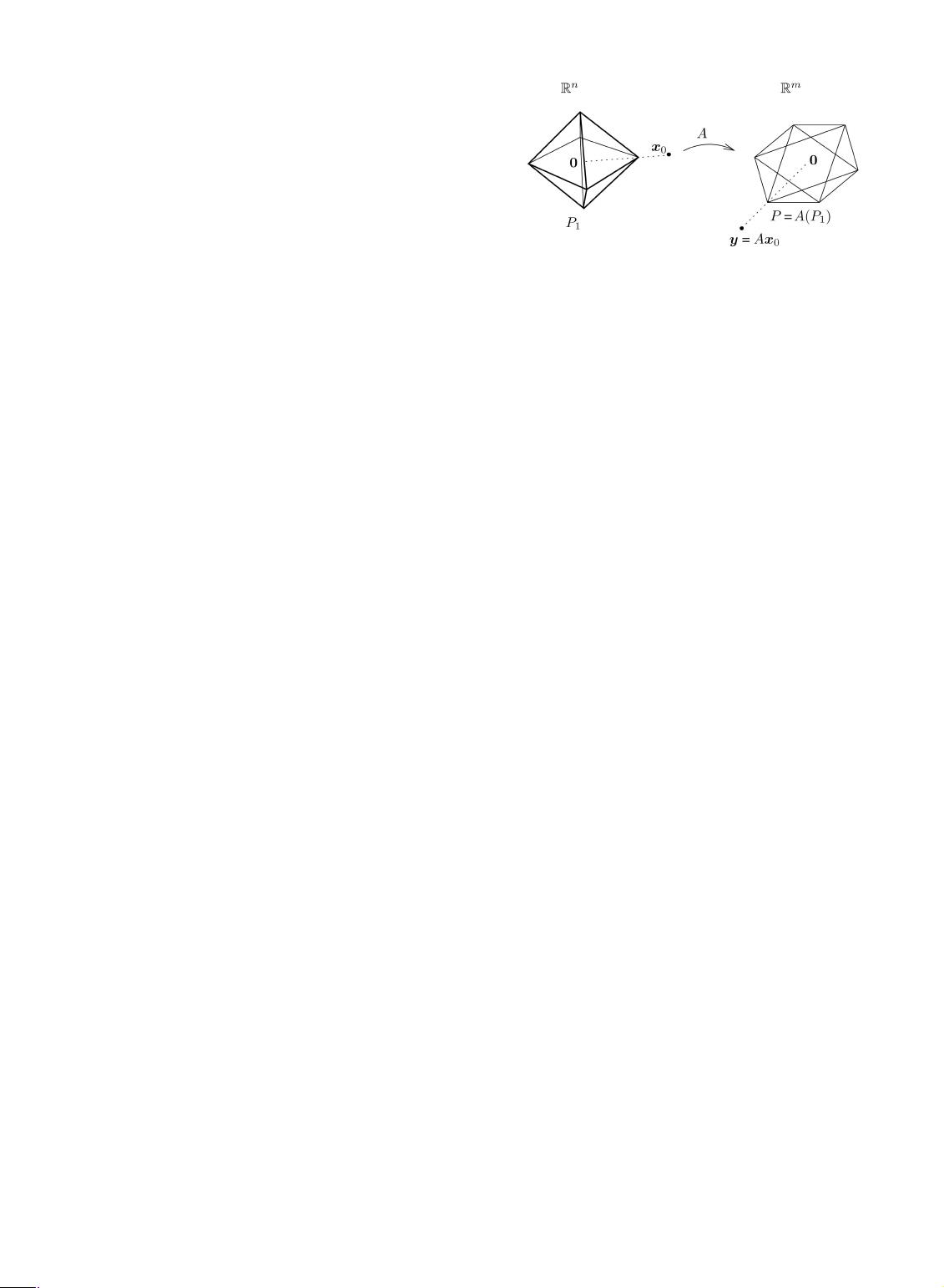
2.2.1 Geometric Interpretation
Fig. 2 gives a geometric interpretation (essentially due to
[36]) of why minimizing the ‘
1
-norm correctly recovers
sufficiently sparse solutions. Let P
denote the ‘
1
-ball (or
crosspolytope) of radius :
P
¼
:
fxx : kxxk
1
gIR
n
: ð7Þ
In Fig. 2, the unit ‘
1
-ball P
1
is mapped to the polytope
P¼
:
AðP
1
ÞIR
m
, consisting of all yy that satisfy yy ¼ Axx for
some xx whose ‘
1
-norm is 1.
The geometric relationship between P
and the polytope
AðP
Þ is invariant to scaling. That is, if we scale P
, its
image under multiplication by A is also scaled by the same
amount. Geometrically, finding the minimum ‘
1
-norm
solution
^
xx
1
to (6) is equivalent to expanding the ‘
1
-ball P
until the polytope AðP
Þ first touches yy. The value of at
which this occurs is exactly k
^
xx
1
k
1
.
Now, suppose that yy ¼ Axx
0
for some sparse xx
0
. We wish
to know when solving (6) correctly recovers xx
0
.This
question is easily resolved from the geometry of that in
Fig. 2: Since
^
xx
1
is found by expanding both P
and AðP
Þ
until a point of AðP
Þ touches yy, the ‘
1
-minimizer
^
xx
1
must
generate a point A
^
xx
1
on the boundary of P .
Thus,
^
xx
1
¼ xx
0
if and only if the point Aðxx
0
=kxx
0
k
1
Þ lies on
the boundary of the polytope P. For the example shown in
Fig. 2, it is easy to see that the ‘
1
-minimization recovers all
xx
0
with only one nonzero entry. This equivalence holds
because all of the vertices of P
1
map to points on the
boundary of P.
In general, if A maps all t-dimensional facets of P
1
to
facets of P , the polytope P is referred to as (centrally)
t-neighborly [36]. From the above, we see that the
‘
1
-minimization (6) correctly recovers all xx
0
with t þ 1
nonzeros if and only if P is t-neighborly, in which case, it is
WRIGHT ET AL.: ROBUST FACE RECOGNITION VIA SPARSE REPRESENTATION 213
Fig. 2. Geometry of sparse representation via ‘
1
-minimization. The
‘
1
-minimization determines which facet (of the lowest dimension) of the
polytope AðP
Þ, the point yy=kyyk
1
lies in. The test sample vector yy is
represented as a linear combination of just the vertices of that facet, with
coefficients xx
0
.
6. Furthermore, even in the overdetermined case, such a linear equation
maynotbeperfectlysatisfiedinthepresenceofdatanoise(see
Section 2.2.2).
7. This intuition holds only when the size of the database is fixed. For
example, if we are allowed to append additional irrelevant columns to A,
we can make the solution xx
0
have a smaller fraction of nonzeros, but this
does not make xx
0
more informative for recognition.
剩余17页未读,继续阅读
2014-09-17 上传
2021-02-07 上传
2014-02-07 上传
2018-12-05 上传
2021-02-09 上传
2023-05-17 上传
2024-11-12 上传

wdmjx
- 粉丝: 1
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
