TensorFlow二分类实战:神经网络与交叉熵优化
66 浏览量
更新于2024-08-29
收藏 116KB PDF 举报
在本文中,我们将探讨如何使用TensorFlow库实现一个简单的二分类问题。首先,我们明确了二分类问题的背景,即根据输入特征(在这个例子中是二维数组x1和x2)预测输出为0或1的结果,其中正负样本的区分规则是x1+x2小于1时,标签y设为1,否则为0。
在神经网络的构建中,关键部分包括:
1. **输入数据**:
输入数据是二维数组(x1, x2),使用numpy生成随机数据。为了方便训练,我们设置了固定的batch_size为8,以控制内存消耗。
2. **隐藏层**:
隐藏层设计为两层,每层有3个节点,参数表示为(2,3)和(3,1)的权重矩阵。数据通过这些矩阵进行线性变换,从而形成隐藏层的输出,输出维度为(1,3)。
3. **损失函数**:
本文选择交叉熵作为损失函数,这是一个常用的衡量分类任务模型性能的指标,它考虑了预测概率分布与实际标签之间的差异。
4. **优化函数**:
使用Adadelta优化算法来最小化损失函数,这是一种自适应学习率优化方法,能够自动调整学习速率并保持良好的性能。
5. **输出层**:
隐藏层输出经过(3,1)的权重矩阵后,得到一个一维输出,表示为0或1的概率,通常通过激活函数如sigmoid或softmax进行转换,但此处并未明确提及。
6. **TensorFlow代码实现**:
作者展示了如何使用TensorFlow的API来创建变量、占位符、前向传播过程以及损失函数和反向传播的定义。代码中提到的`tf.clip_by_value`函数用于限制输出的范围,以确保数值稳定。
通过这个示例,读者可以理解如何在TensorFlow框架下构建和训练一个基础的二分类神经网络,包括数据准备、模型结构设计和优化策略。这对于初学者来说是一个实用的入门教程,同时也展示了深度学习模型应用于实际问题中的基本步骤。
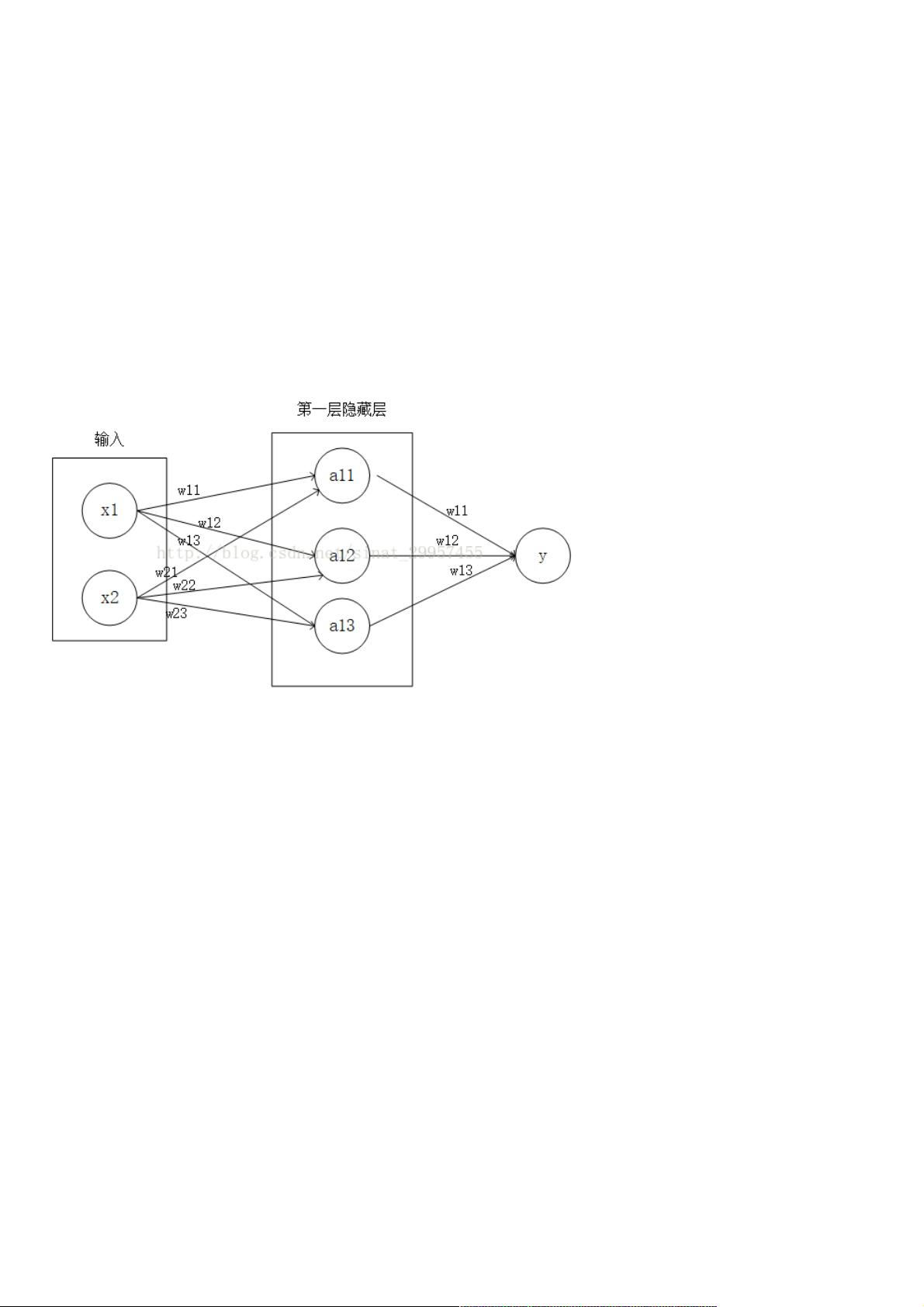
使用使用TensorFlow实现二分类的方法示例实现二分类的方法示例
使用使用TensorFlow构建一个神经网络来实现二分类,主要包括输入数据格式、隐藏层数的定义、损失函数的选择、优化函数的构建一个神经网络来实现二分类,主要包括输入数据格式、隐藏层数的定义、损失函数的选择、优化函数的
选择、输出层。下面通过选择、输出层。下面通过numpy来随机生成一组数据,通过定义一种正负样本的区别,通过来随机生成一组数据,通过定义一种正负样本的区别,通过TensorFlow来构造一个神经网络来构造一个神经网络
来实现二分类。来实现二分类。
一、神经网络结构一、神经网络结构
输入数据:定义输入一个二维数组(x1,x2),数据通过numpy来随机产生,将输出定义为0或1,如果x1+x2<1,则y为1,否则
y为0。
隐藏层:定义两层隐藏层,隐藏层的参数为(2,3),两行三列的矩阵,输入数据通过隐藏层之后,输出的数据为(1,3),t通过矩
阵之间的乘法运算可以获得输出数据。
损失函数:使用交叉熵作为神经网络的损失函数,常用的损失函数还有平方差。
优化函数:通过优化函数来使得损失函数最小化,这里采用的是Adadelta算法进行优化,常用的还有梯度下降算法。
输出数据:将隐藏层的输出数据通过(3,1)的参数,输出一个一维向量,值的大小为0或1。
二、TensorFlow代码的实现
import tensorflow as tf
from numpy.random import RandomState
if __name__ == "__main__":
#定义每次训练数据batch的大小为8,防止内存溢出
batch_size = 8
#定义神经网络的参数
w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
#定义输入和输出
x = tf.placeholder(tf.float32,shape=(None,2),name="x-input")
y_ = tf.placeholder(tf.float32,shape=(None,1),name="y-input")
#定义神经网络的前向传播过程
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
#定义损失函数和反向传播算法
#使用交叉熵作为损失函数
#tf.clip_by_value(t, clip_value_min, clip_value_max,name=None)
#基于min和max对张量t进行截断操作,为了应对梯度爆发或者梯度消失的情况
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y,1e-10,1.0)))
# 使用Adadelta算法作为优化函数,来保证预测值与实际值之间交叉熵最小
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
#通过随机函数生成一个模拟数据集
rdm = RandomState(1)
# 定义数据集的大小
dataset_size = 128
# 模拟输入是一个二维数组
X = rdm.rand(dataset_size,2)
#定义输出值,将x1+x2 < 1的输入数据定义为正样本
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-05-15 上传
2020-05-15 上传
2020-09-20 上传
2017-11-11 上传
2021-01-22 上传
224 浏览量

weixin_38676500
- 粉丝: 9
- 资源: 915
 我的内容管理
展开
我的内容管理
展开







最新资源
- VC++创建和删除快捷方式,添加程序组菜单
- BoltzmannMachinesRPlots
- 4-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- Bluebird.WkBrowser:超级基本的Web浏览器,使用WkWebView和Xamarin.Mac。 旨在作为WkWebView兼容性问题的测试工具
- ReactWebpack
- imageflow-prototype:新 WordPress Image Flow 的工作响应原型 - 不与 WordPress 数据集成
- gfg-coding-problems:解决编码问题
- Mohamed-Bengrich.com
- behrtheme:基于Susty WP的Behr Immobilien的WordPress主题
- symfony-angular-seed:基于API(symfony2)和前端(Angular)的种子项目
- VC++让程序在开机启动时就自动运行
- Gprinter_2020.4_M-2.zip
- AT89S52+AT24C010+DAC0832+MAX7128SLC84-15+按键+LCD+7805组成的原理图和PCB电路
- Frontend-01-模板
- Raw JSON Library:原始JSON库(RJL)是一种高性能JSON(符合RFC 4627)-开源
- 通俗易懂的Go语言教程第4季(含配套资料)
