业务日志处理系统:Kafka+Elasticsearch驱动的实时与分析架构
13 浏览量
更新于2024-08-29
收藏 402KB PDF 举报
随着业务服务的不断增长,日志管理成为了一项关键任务,传统的日志收集和分析方式难以满足实时性、扩展性和容错性的要求。本文主要探讨了如何构建一个集中式海量业务日志实时处理系统,以解决这一挑战。
首先,系统的核心组件包括:
1. **Kafka**:作为分布式消息系统,Kafka因其高吞吐量和消息持久化特性,被选为集中处理日志的理想工具。它支持物理分片存储,能够处理海量日志发布和订阅,确保消息的可靠传输。Kafka的引入解决了直接将日志同步到下游服务可能导致的性能瓶颈和数据丢失问题。
2. **Elasticsearch**:作为一个实时分布式搜索引擎,Elasticsearch提供了零配置、自动分片、备份机制以及RESTful接口,便于日志查询和统计。它作为索引层,支持高效的搜索和数据分析。
3. **Flume**:作为分布式日志收集系统,Flume负责从各个业务服务(通过BizLogSDK)采集日志,并将数据输入到Kafka。Flume还负责数据预处理,根据不同的需求进一步分发。
4. **Zookeeper**:作为协调服务,Zookeeper用于维护Kafka集群的配置,确保系统的稳定性。
系统实现思路如下:
- 开发BizLogSDK,集成到业务服务端,自动收集和发送日志至Kafka。
- Kafka接收并持久化业务日志,降低下游系统的压力。
- Flume负责拉取Kafka中的日志,进行预处理和分发,减轻业务服务的负载。
- 日志内容通过Elasticsearch进行索引,便于后续查询和统计。
- Kibana作为用户界面,提供开发、运维和运营人员查询和统计报表的功能。
架构设计的重点在于解耦业务服务和日志处理,通过Kafka的消息队列机制,确保数据的可靠性和实时性。这种设计有助于提高系统的整体性能,降低故障风险,优化网络资源分配,并为用户提供直观的数据访问工具。
总结来说,本文介绍了如何通过Kafka、Elasticsearch和Flume等技术构建一个高效、灵活且稳定的业务日志服务架构,旨在解决分布式系统中日志管理的复杂性和效率问题,提升运维效率和问题诊断能力。
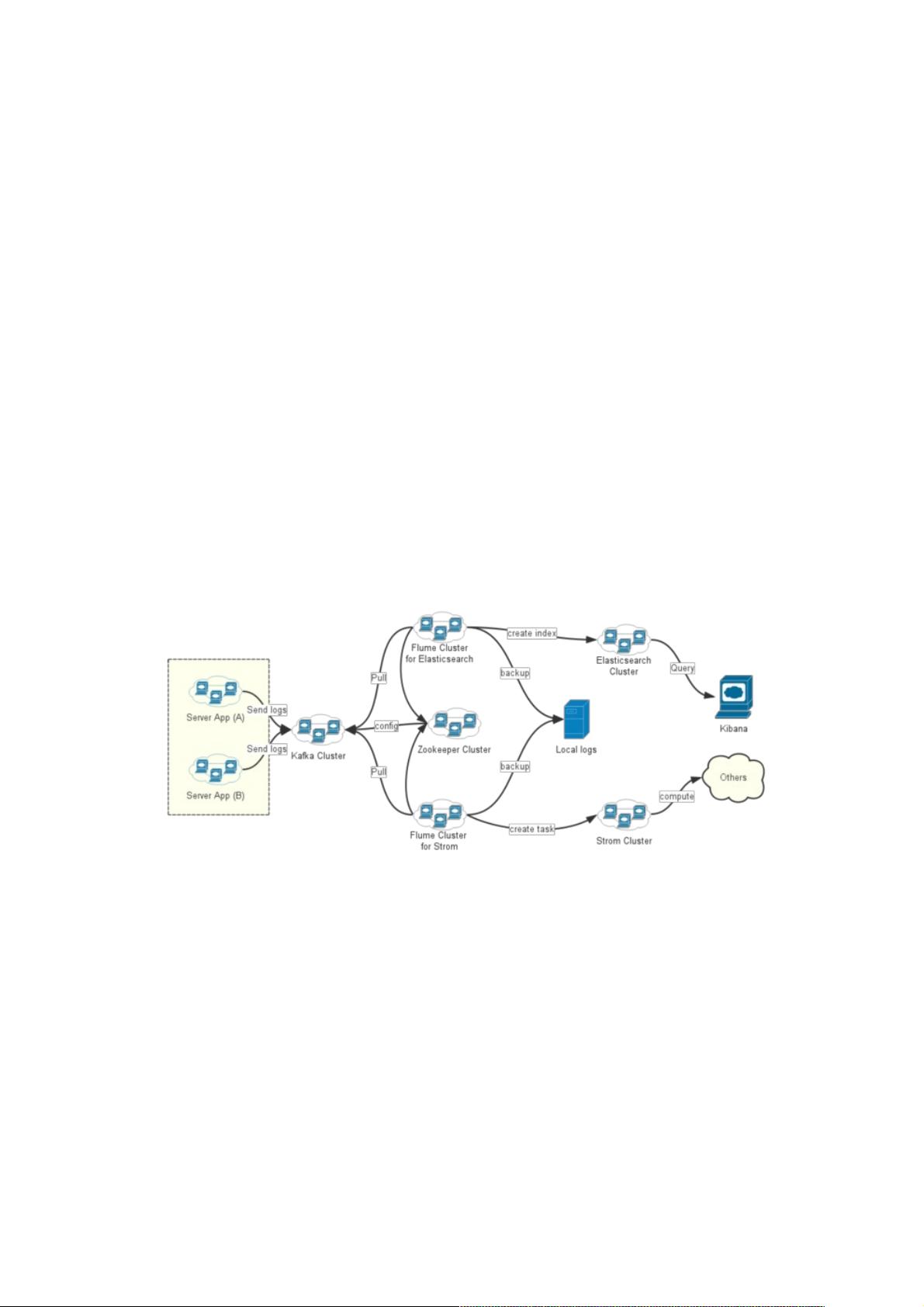
业务日志服务架构简介业务日志服务架构简介
背景介绍
随着业务服务(Server App)逐渐增加,使得问题排查非常困难,很多时候需要关联查询多个服务的日志,而且统计分析十分
不便。因此,急需设计一个集中式海量日志实时处理系统。需要满足功能需求(实时看日志、统计历史日志、实时行为分析、
用户轨迹跟踪等)、性能需求(具有高吞吐能力、高扩展性、高容错性)等。
组件介绍
Kafka 是一种高吞吐量的分布式发布订阅消息系统,它适合处理海量日志发布订阅,提供消息磁盘持久化、支持物理分片存
储、多组消费等特性。
Elasticsearch 是一个开源实时分布式搜索引擎,具备如下特征:零配置,索引自动分片,索引副本机制,restful风格接口,多
数据源,自动搜索负载等。
Flume 是Apache基金会的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,它支持在日志系统中定制
各类数据发送方,用于收集数据;同时提供对数据进行简单处理,并写到各种数据接受方(可定制)。
实现思路
1.开发业务日志SDK(下文为描述方便,称之为 BizLogSDK),嵌于各业务App;
2.从业务服务端收集日志并集中输出到Kafka;
3.根据不同需求(查询、统计),由Flume对数据预处理并分发;
4.Flume 的下游组件对日志内容进行消费;
架构设计
目前日志消费方式有两种:
1.Elasticsearch 做索引,用于查询、统计;
2.基于Storm流式计算实现(待完成)。
引入Kafka的目的:
线上业务集群规模较大,日志产生量巨大,如果直接同步日志对下游服务负荷较重,容易因为故障导致日志阻塞延迟和丢失,
所以引入了kafka ;
消息可以持久化,并且可以进行日志回溯。有了消息队列,上游服务和下游服务完全解藕,网络传输会更稳定、更高效、更均
衡,避免级联效应。
架构说明
1.由于业务日志量极大,为减轻业务服务的压力,故将业务日志首先输出到 Kafka 集群;
2.Flume 做分发和预处理。从Kafka中拉取待处理的业务日志,先在本地保留一份,然后做预处理和分发;
3.Elasticsearch 做日志索引。对业务日志按 Prefix-bizType-YYYY.MM.dd 的格式创建索引;
4.Kibana 做查询界面与简单的统计报表。供开发、运维、运营人员使用;
下载后可阅读完整内容,剩余3页未读,立即下载
2016-11-06 上传
2021-08-24 上传
304 浏览量
2023-07-12 上传
2021-01-27 上传
2021-10-12 上传
2021-10-11 上传
2024-04-02 上传
2021-10-25 上传

weixin_38672807
- 粉丝: 9
- 资源: 923
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
