Hadoop MapReduce详解与WordCount实战
需积分: 9 87 浏览量
更新于2024-07-22
收藏 806KB DOCX 举报
"Hadoop MapReduce实例解析,大数据学习"
MapReduce是Google提出的一种分布式计算模型,主要用于处理和生成大规模数据集。Hadoop将其作为一种核心组件,使得开发者能够编写处理海量数据的应用程序。在这个实例解析中,我们将深入理解MapReduce的工作原理和流程,以及通过运行WordCount程序来实践MapReduce。
1.1 MapReduce编程模型
MapReduce的核心理念是将大问题分解为小问题,通过并行处理得到结果,然后合并这些结果。它由两个主要函数构成:map和reduce。map函数负责将原始数据分割并转化为中间形式,reduce函数则对中间结果进行聚合,得出最终输出。在Hadoop中,JobTracker负责任务调度,而TaskTracker负责任务的实际执行。JobTracker只有一个,而TaskTracker在每个节点上都有一个实例,协同完成任务。
1.2 MapReduce处理过程
一个MapReduce任务始于一个Job,Job被拆分为map和reduce两个阶段。map阶段,输入数据被分割并由map函数处理,生成中间键值对。reduce阶段,这些中间键值对经过分区和排序后,作为reduce函数的输入,进行进一步的聚合操作,最终产生输出。
2. 运行WordCount程序
WordCount是MapReduce的经典示例,用于统计文本中的单词频次。它的实现包括以下步骤:
2.1 准备工作
在实际运行WordCount程序前,需要进行一些基本设置,比如创建本地示例文件,这里假设是在"/home/hadoop"目录下创建了待处理的文本文件。
2.2 编写Map函数
Map函数接收输入数据,通常是<key, value>对,例如<行号,整行文本>,然后将文本分割成单词,生成<单词,1>的中间键值对。
2.3 编写Reduce函数
Reduce函数接收由相同单词键聚合的中间键值对<单词,[1,1,...]>,并将所有计数累加,生成最终的<单词,总次数>对。
2.4 执行WordCount程序
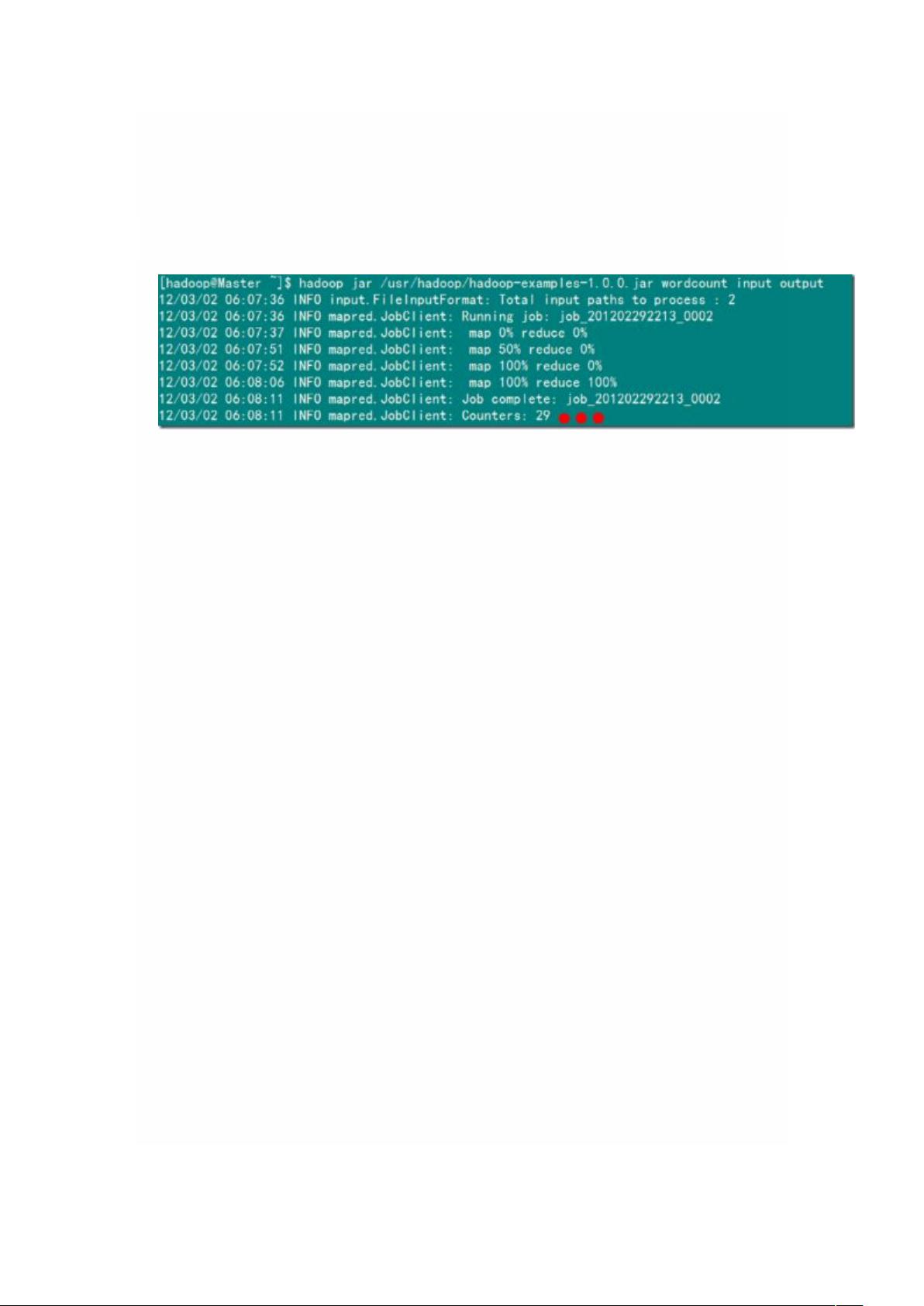
在Hadoop环境中,使用Hadoop的命令行工具提交WordCount程序,指定输入文件和输出目录。Hadoop会自动处理数据的分布、计算和结果的收集。
3. 结果分析
程序执行完成后,可以在指定的输出目录下查看结果,看到每个单词及其在文本中出现的次数。
总结来说,MapReduce通过将大规模数据处理任务分解,利用分布式计算的优势高效处理数据,然后通过reduce阶段将结果汇总,实现了对大数据集的有效分析。WordCount程序是理解和学习MapReduce的一个重要起点,展示了其基本的运算逻辑和处理流程。在实际应用中,MapReduce可以用于各种复杂的数据处理任务,如数据分析、搜索引擎索引构建等。

剩余25页未读,继续阅读
195 浏览量
2024-03-13 上传
点击了解资源详情
399 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

Shawn_Mei
- 粉丝: 2
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 华为公司内部编程语法规范
- Python 3 for Absolute Beginners.pdf
- C语言深度解剖---极富含金量的国内C语言书籍
- J2ME开发环境搭建\J2ME开发环境搭建
- C语言库函数(A-F开头).doc
- 天书夜读(完整版) pdf
- Netbeans6.8 配置php5.30.doc
- 有效沟通原理-企业管理和人际交往成功的基础
- 搜索引擎原理 技术与系统
- CAN总线入门手册 初学者首选
- windows mobile6.0(WM6.0)开发环境搭建
- 路创智能照明通讯协议
- UML2.0设计手册.pdf
- 2009软考程序员试题scxyx.pdf
- DIVCSS布局大全.pdf
- Professional Android App
