深度学习分布式计算框架解析:后端选型与实时离线计算
版权申诉
125 浏览量
更新于2024-06-21
收藏 2.07MB PDF 举报
"该资源是DeepLearning深度学习教程的第十八章,主要探讨了后端架构选型、离线及实时计算的相关知识。章节涵盖了分布式计算的重要性、多种深度学习分布式计算框架的介绍、如何选择合适的框架进行模型训练、实时计算与离线计算的概念及其应用,以及如何利用分布式框架提升模型训练速度和在个性化推荐系统中的应用。"
在深度学习领域,随着数据量的爆炸性增长,单机处理能力已难以满足大规模模型训练的需求,因此分布式计算成为了必然选择。本章首先提出问题,为什么需要分布式计算?答案在于它能有效解决计算资源限制、提高计算效率、加速模型收敛,使得研究人员能够处理更复杂的模型和更大规模的数据集。
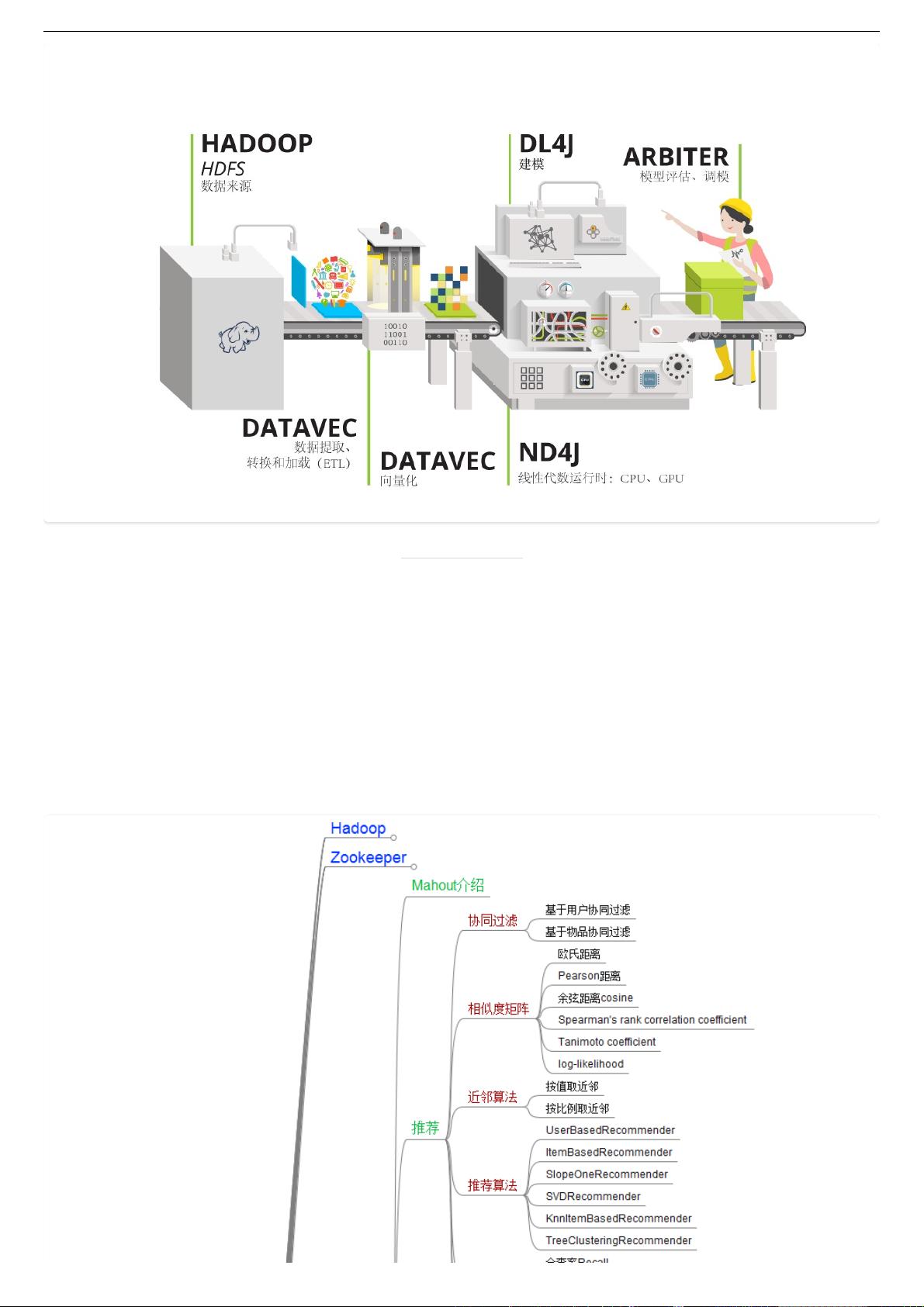
本章列举并简要介绍了多个深度学习分布式计算框架,包括PaddlePaddle(百度开源的深度学习平台,支持分布式训练)、Deeplearning4j(Java语言的深度学习库,适用于企业级应用)、Mahout(Apache的一个机器学习库,早期支持深度学习)、SparkMLlib(Apache Spark的机器学习库,不专注于深度学习,但可与TensorFlow等结合)、Ray(通用的分布式计算框架,支持机器学习)、Sparkstream(Apache Spark的实时流处理模块)、Horovod(Uber开发的用于分布式GPU训练的库)、BigDL(Intel的分布式深度学习库,运行于Apache Spark之上)、Petastorm(Uber开源的数据读取框架,用于大数据集的深度学习)以及TensorFlowOnSpark(将TensorFlow整合到Apache Spark上的框架)。
选择合适的分布式计算框架进行模型训练是一个关键决策,需要考虑的因素包括:框架的易用性、社区支持、性能优化、对特定硬件的支持以及与其他工具的兼容性。理解各框架的特性和适用场景对于有效地部署深度学习模型至关重要。
实时计算是指处理持续流入的数据流,通常应用于实时监控、预警等场景。实时流计算过程涉及数据捕获、转换和分发,要求快速响应并实时处理新数据。
离线计算则是在固定时间窗口内完成的批量数据处理,常用于数据分析、模型训练等任务。离线计算可以充分利用大量计算资源,但处理结果可能存在一定的延迟。
利用分布式框架可以显著提高模型训练速度,通过并行化计算,将大任务拆分为小任务分配给多个计算节点同时执行。例如,Horovod提供了高效的多GPU和多节点同步训练方案。
在移动互联网环境中,深度学习分布式计算框架能够帮助处理设备端的计算限制,实现模型的高效运行和更新。而在个性化推荐系统中,这些框架可以帮助快速训练和调整模型,以适应用户行为的实时变化。
评估个性化推荐系统效果时,常见的指标有准确率、召回率、F-Measure、E值和平均正确率。这些指标帮助衡量推荐的精确度和覆盖率,从而优化推荐策略。
本章内容深入探讨了深度学习中的后端架构选择,提供了丰富的分布式计算框架信息,并介绍了如何在实际场景中应用这些技术,对理解和实践深度学习的分布式计算具有重要指导价值。
剩余24页未读,继续阅读
2020-07-27 上传
2022-08-03 上传
2022-08-03 上传
2023-08-23 上传
2022-08-03 上传
2022-08-03 上传
2024-04-21 上传

安全方案
- 粉丝: 2528
- 资源: 3959
 我的内容管理
展开
我的内容管理
展开







最新资源
- ayotidur
- Exsty-crx插件
- Language-zone
- SCATTERBAR3:创建一个 3-D 条形图,其中条形放置在用户指定的 XY 位置。-matlab开发
- TensorFlow2实战-系列教程14:Resnet实战
- [新闻文章]小虫新闻管理系统V1.0_xcnewsv1.0.rar
- AzureDiagnosticsPipeline:此存储库具有构建Azure诊断DevOps管道的源,以将诊断设置应用于Azure资源(动态)
- 蛇:基于控制台的蛇游戏
- TurboCStudy,c语言编译的源码,c语言项目
- Biorhythm:你的一周过得怎么样?-matlab开发
- koa-template-project:Koa模板项目
- 简洁棕色线条响应式html5模板5598.zip
- Coin Master Free Spins Loader-crx插件
- 苹果手机
- click-and-meet-calendar-generator:生成可打印的日历,以根据德国的COVID-19规则管理“点击并开会”约会
- -123r
