HDF5技术深度调研:优势、存储格式与数据模型
需积分: 0 102 浏览量
更新于2024-08-04
收藏 2.2MB DOCX 举报
"UDA_HDF5调研1"
在深入探讨UDA(通用数据访问)与HDF5的关系之前,首先让我们详细了解HDF5的核心概念和技术优势。HDF5是一种强大的数据存储和管理框架,专为处理大规模、高复杂度的数据集而设计。它提供了可移植的文件格式,不受数据对象数量或大小的限制,支持多种数据类型和元数据,并具备高效的压缩和并行处理能力。HDF5被广泛应用于金融、能源、航空航天、汽车、生物医疗等多个领域。
HDF5的文件存储结构由超级块、B树节点、堆积块、对象头部和对象数据组成。超级块作为文件的起始标志,包含了关于文件的信息。B树节点用于高效地索引和检索数据,而堆积块则用于存储非结构化的数据。对象头部包含数据集的元信息,如数据类型、数据空间、布局和过滤器。数据集本身是一个包含这些元信息的对象,可以链接到其他数据块或B树。
HDF5的数据模型是其逻辑组织的基础,它由数据集、组和属性三个基本元素构成。数据集是可变大小的多维数组,可以包含任意复杂的数据类型。组类似于文件系统的目录,可以包含数据集和其他组,形成层次结构。属性则提供了附加的元数据,用于描述数据集或组的特性。
现在转向UDA,它是用于访问和管理数据库的一种抽象层,可以简化与不同数据库系统交互的复杂性。在HDF5的背景下,UDA可能涉及创建特定的接口或服务,使得用户能够以一致的方式访问和操作HDF5文件中的数据。这包括脉冲数据库、UDA索引数据库、UDA索引器、UDA服务和UDA客户端工具。脉冲数据库可能指的是存储时间序列数据的结构,而UDA索引数据库和索引器则用于高效地查找和定位数据。UDA服务可能是提供这些功能的后台进程,而UDA客户端工具则是用户与这些服务交互的界面。API接口则允许开发者在应用程序中集成这些功能,实现对HDF5数据的高级访问。
在并行处理方面,HDF5支持SWMR(Single-Writer Multiple-Reader)模式,允许多个读取者同时访问文件,而一个写入者可以在不中断读取的情况下更新数据。这种并发控制机制对于高性能计算和大数据分析至关重要。此外,HDF5的VDS(Virtual Dataset)机制允许动态创建和更新数据集视图,即使源数据在物理上分散或位于多个文件中,也能提供统一的访问接口。
UDA与HDF5的结合提供了强大且灵活的数据管理和访问方式,适用于需要高效处理大量复杂数据的场景。通过了解HDF5的底层结构、数据模型和并行处理特性,开发者和研究人员能够更好地利用UDA工具来满足特定的业务需求和安全要求,尤其是在制造和安全相关的领域。
HDF5(Hierarchical Data Format 5)调研
摘要:本文主要针对 HDF5 的特性和特点进行阐述,第一节简单介绍一下 HDF5 的应用和优势,
第二节介绍 HDF5 的文件存储格式,第三节介绍 HDF5 文件的数据模型,第四节介绍 HFD5 软
件,其中包含的库、语言接口和工具等,第五节介绍 HDF5 中的并行方法,第六节 SWMR 的并
发控制机制,第七节 VDS 虚拟数据集机制。
1 HDF5 优势及其应用
HDF5 是一种独特的技术套件,可以管理极其庞大和复杂的数据集。HDF5 包含用于存储
HDF5 数据的文件格式,用于从应用程序逻辑组织和访问 HDF5 数据的数据模型,以及用于处
理此格式的库、语言接口和工具。其广泛应用于金融服务、天然油气、航天、汽车、医药生
物、芯片制造、电子器件、政府、国防安全等部门和领域。HDF5 有以下优势:
可移植的文件格式,对集合中数据对象的数量或大小没有限制。
多功能数据模型,可以表示非常复杂的数据对象和各种元数据。
丰富的软件库,其中包含的库、工具和语言接口,用于管理,操作,查看和分析集
合中数据。
高效灵活的数据压缩和并行处理的机制,可实现访问时间和存储空间优化。
2 HDF5 的文件存储格式
在最低级别,因为信息实际写入在磁盘上,HDF5 文件由以下内容组成对象:
超级块(Superblock)
B 树节点(B-tree nodes)
堆积块(Heap blocks)
对象头部(Object headers)
对象数据(Object data)
可用空间(Free space)
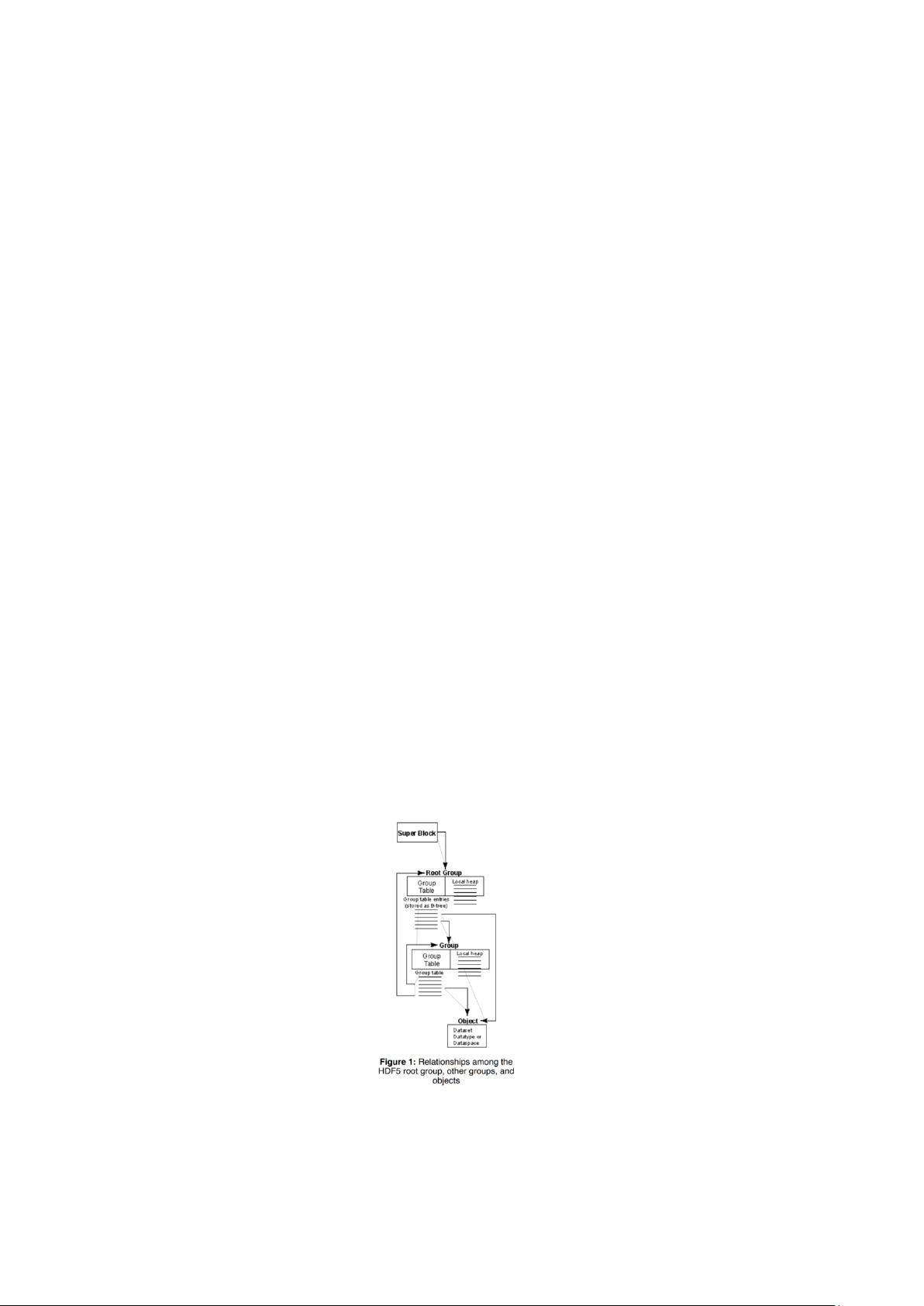
图 1.文件存储格式
HDF5 使用低级对象表示高级对象,其中高水平的对象通过 API 为用户提供接口。如图 1
所示,一个组(group)由一个对象头部(object headers)和 B 树节点(B-tree nodes)组
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-04-27 上传
2021-03-16 上传
2021-03-21 上传
2021-03-02 上传
2021-04-03 上传
2021-10-04 上传

BJWcn
- 粉丝: 35
- 资源: 293
 我的内容管理
展开
我的内容管理
展开







最新资源
- 行业分类-设备装置-可调式行走平台.zip
- segy-loader:这是一个读取敏感数据的软件。
- SiamRPN-PyTorch:SiamRPN在PyTorch上的实现
- reactjs
- 行业分类-设备装置-可调节体内分解速度的水凝胶及其制造方法.zip
- ShapeDescriptor
- statnet:来源源于statnet
- MysticCombatLogger
- bbiwiki-开源
- 行业分类-设备装置-同时识别1型和3型鸭甲型肝炎病毒的单克隆抗体及其杂交瘤细胞株和应用.zip
- 照片审核小工具.zip
- terraform-aws:与Amazon Web Services相关的Terraform项目的集合
- Alpha-Testing
- enterprise-incident-tracking:React,redux,react-redux,react-saga,样式化组件,Ant Design,Axios,Node.js
- reactstock_sqlite_db
- nor-async-profile:异步配置文件的 Q.fcall 风格界面
